In the vast and ever-expanding landscape of data-driven innovation, SQL (Structured Query Language) stands as a foundational pillar, enabling the efficient management, retrieval, and manipulation of information that fuels modern technological advancements. Among its powerful constructs, the subquery, often referred to as an inner query or nested query, represents a sophisticated technique for extracting and processing data with remarkable precision and flexibility. Understanding subqueries is crucial for anyone engaging with advanced data analytics, robust application development, or the intricate design of information systems that characterize contemporary tech and innovation.
The Core Concept of Subqueries
A subquery is fundamentally a query nested inside another SQL query. This embedding allows the results of the inner query to be used as input or a condition for the outer query, creating a powerful mechanism for solving complex data retrieval challenges that might be cumbersome or impossible with a single, standalone query. The primary purpose of a subquery is to return data that will be used by the main query to complete its operation, acting as a dynamic value, a set of values, or even a table.
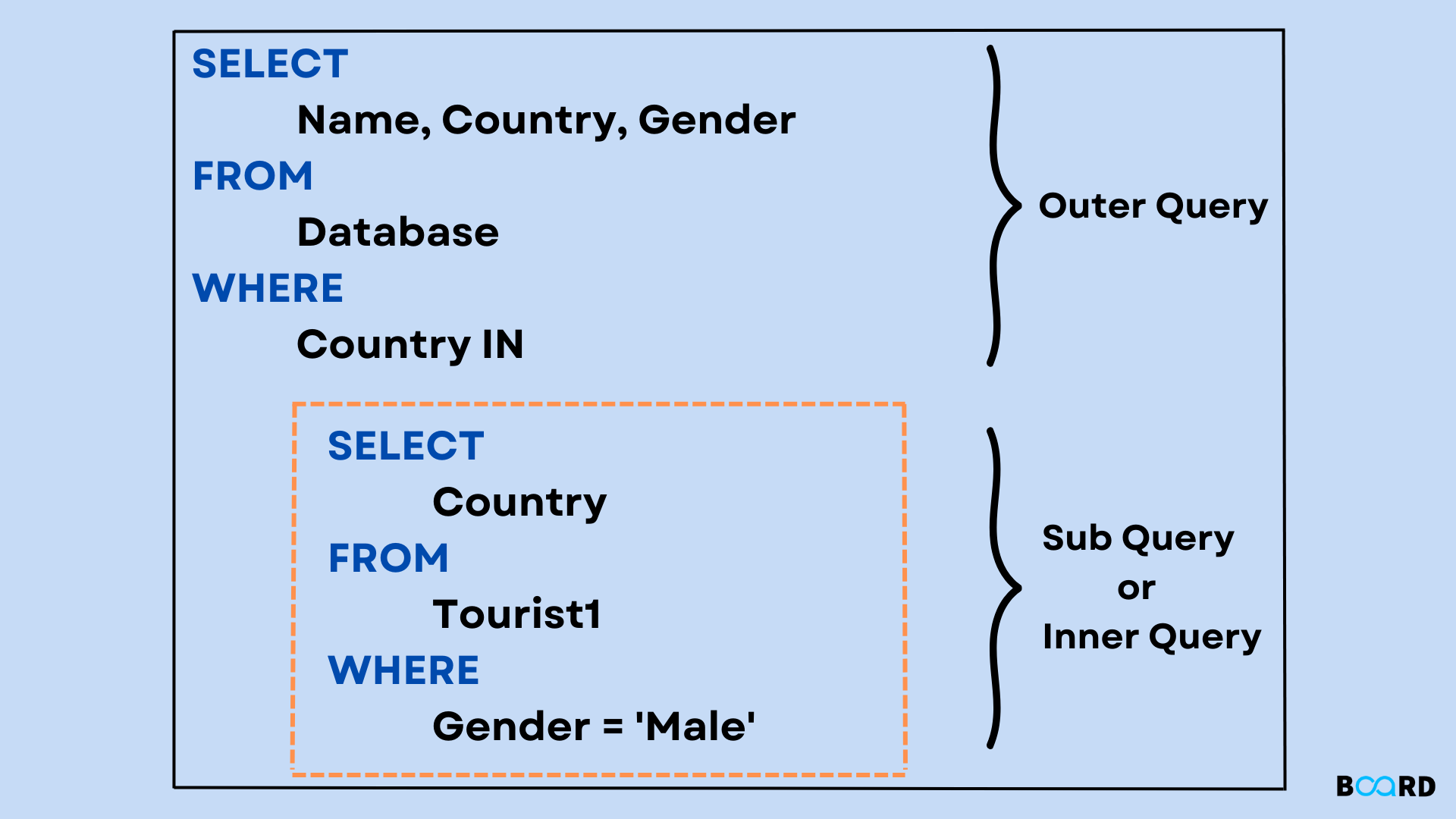
Nested Queries Explained
Imagine a scenario where you need to identify all products whose prices are above the average price of all products. A single SELECT statement cannot achieve this directly because the average price must first be calculated. This is where a subquery shines. The inner query calculates the average price, and the outer query then uses this calculated average to filter the product list.
The execution flow typically starts with the inner query. The database engine executes the subquery first, obtains its result, and then passes this result to the outer query. The outer query then processes its operations using the data provided by the subquery, effectively breaking down a complex problem into smaller, manageable parts. This modular approach significantly enhances the expressiveness and capability of SQL queries, enabling developers and analysts to craft highly specific data retrieval logic.
Why Subqueries Matter in Modern Data Architectures
In an era defined by big data, machine learning, and real-time analytics, the ability to efficiently query and analyze vast datasets is paramount. Subqueries play a vital role in this context by:
- Enhancing Data Filtering: They provide a dynamic way to filter data based on conditions that are themselves derived from other parts of the database, going beyond static literal values.
- Facilitating Complex Joins: While SQL
JOINoperations are powerful, subqueries can sometimes simplify the logic for correlating data across multiple tables, especially when conditional logic within the join is complex. - Enabling Aggregation and Comparison: Subqueries allow for comparisons against aggregated values (like averages, sums, counts) without requiring temporary tables or complex application-side logic.
- Improving Readability for Certain Operations: For some intricate data manipulation tasks, a well-structured subquery can be more readable and maintainable than a single, overly complex query.
- Supporting Advanced Analytics: Many advanced analytical queries, especially those involving ranking, windowing, or comparisons against dynamic thresholds, heavily rely on the capabilities offered by subqueries.
As data volumes continue to swell and the demand for deeper, more nuanced insights grows, the strategic application of subqueries becomes an indispensable skill in the toolkit of any data professional operating within the innovative tech landscape.
Types and Syntax of Subqueries
Subqueries are highly versatile and can be employed in various clauses of a SQL statement, including SELECT, FROM, WHERE, HAVING, and even INSERT, UPDATE, and DELETE statements. Their classification often depends on the number of values they return and their relationship with the outer query.
Scalar Subqueries
A scalar subquery returns a single value (one row, one column). It can be used anywhere a single expression or value is expected. This is the most common and straightforward type of subquery, often used in SELECT clauses to retrieve a related value or in WHERE clauses for comparison.
- Example in
SELECT: Fetching an employee’s department name alongside their details.
sql
SELECT
e.EmployeeID,
e.EmployeeName,
(SELECT d.DepartmentName FROM Departments d WHERE d.DepartmentID = e.DepartmentID) AS DepartmentName
FROM
Employees e;
- Example in
WHERE: Finding products more expensive than the average product price.
sql
SELECT ProductName, Price
FROM Products
WHERE Price > (SELECT AVG(Price) FROM Products);
Row Subqueries
A row subquery returns a single row but potentially multiple columns. These are typically used in WHERE or HAVING clauses for comparison with another row of values. The comparison often involves operators like =, <, >, <=, >=, <>, IN, NOT IN.
- Example: Finding employees who match both the department and job title of a specific employee.
sql
SELECT EmployeeName, DepartmentID, JobTitle
FROM Employees
WHERE (DepartmentID, JobTitle) = (SELECT DepartmentID, JobTitle FROM Employees WHERE EmployeeName = 'Jane Doe');
Table Subqueries
A table subquery returns an entire table (multiple rows, multiple columns). These are most frequently found in the FROM clause, where they effectively create a derived table that the outer query can then treat as a regular table. They are also used with IN, NOT IN, EXISTS, NOT EXISTS operators.
- Example in
FROM(Derived Table): Calculating average salaries for departments with more than 5 employees.
sql
SELECT
dt.DepartmentName,
dt.AverageSalary
FROM
(SELECT
d.DepartmentName,
AVG(e.Salary) AS AverageSalary,
COUNT(e.EmployeeID) AS EmployeeCount
FROM
Departments d
JOIN
Employees e ON d.DepartmentID = e.DepartmentID
GROUP BY
d.DepartmentName) AS dt
WHERE
dt.EmployeeCount > 5;
- Example with
IN: Selecting customers who have placed orders.
sql
SELECT CustomerName
FROM Customers
WHERE CustomerID IN (SELECT DISTINCT CustomerID FROM Orders);
Correlated vs. Non-Correlated Subqueries
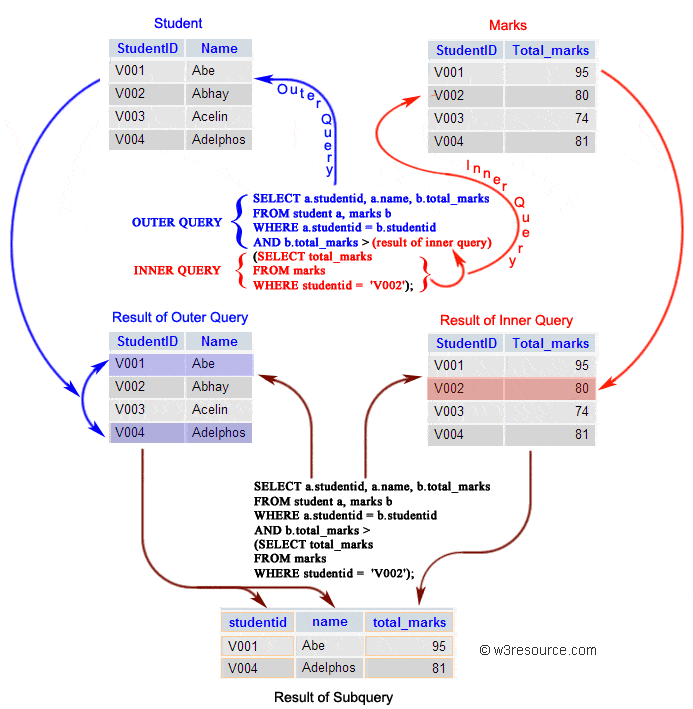
The distinction between correlated and non-correlated subqueries is crucial for understanding their behavior and performance implications:
-
Non-Correlated Subquery: This is a self-contained query that can be executed independently. Its results do not depend on the outer query, and it runs only once, passing its complete result set to the outer query. All the scalar, row, and table subqueries demonstrated above are typically non-correlated.
-
Correlated Subquery: Unlike its non-correlated counterpart, a correlated subquery depends on the outer query for its values. It executes once for each row processed by the outer query. This means the inner query references a column from the outer query. While powerful for specific scenarios, they can sometimes be less performant than non-correlated subqueries or alternative approaches like
JOINs, especially on large datasets. -
Example of Correlated Subquery: Finding employees who earn more than the average salary in their respective departments.
sql
SELECT EmployeeName, Salary, DepartmentID
FROM Employees e1
WHERE Salary > (SELECT AVG(Salary) FROM Employees e2 WHERE e2.DepartmentID = e1.DepartmentID);
Here,e2.DepartmentID = e1.DepartmentIDlinks the inner query’s execution to each row of the outer query.
Practical Applications and Innovative Use Cases
Subqueries, in their various forms, empower developers and data scientists to build sophisticated data solutions critical for many facets of modern tech and innovation, from predictive analytics to intelligent automation systems.
Data Filtering and Advanced Analytics
Beyond simple equality checks, subqueries facilitate dynamic and context-aware filtering. For instance, in supply chain management, one might use a subquery to identify all suppliers whose average delivery time is faster than the overall average, enabling real-time performance evaluations. In financial technology, subqueries can pinpoint transactions that deviate significantly from a user’s typical spending patterns, flagging potential fraud. This dynamic filtering capability is essential for building intelligent systems that adapt to evolving data characteristics.
Dynamic Value Generation
Subqueries excel at generating values on the fly that are then incorporated into the main query’s logic. Consider an AI-driven recommendation engine. A subquery could dynamically calculate a user’s preference score based on historical interactions and then the main query uses this score to filter and rank potential recommendations from a product catalog. This real-time, data-driven value generation allows for highly personalized and responsive applications.
Complex Reporting and Aggregation
Many analytical dashboards and business intelligence tools rely heavily on complex aggregations that often involve subqueries. For example, generating a report showing the year-over-year growth for each product category requires calculating current year sales, previous year sales, and then comparing them. Subqueries can neatly encapsulate these individual calculations, making the overall reporting query more structured and manageable. This is invaluable in sectors like e-commerce analytics, where granular insights into sales performance are crucial for strategic decision-making.
Enhancing Data Integrity and Validation
While primarily used for data retrieval, subqueries can also play a role in data modification statements. They can be used within UPDATE or DELETE statements to select which rows to modify or delete based on conditions derived from other tables or aggregated values. For instance, updating a ‘status’ field for all projects that have passed their deadline, where the deadline itself is contingent on multiple factors calculated in a subquery, ensures robust data integrity within complex project management systems.
Performance Considerations and Best Practices
While subqueries offer immense power, their inefficient use can lead to significant performance bottlenecks, especially with large datasets. Understanding how to optimize them and when to consider alternatives is key to building high-performance, scalable tech solutions.
Optimizing Subquery Performance
- Index Usage: Ensure that columns used in
WHEREclauses of both the outer and inner queries, particularly those involved inJOINconditions for correlated subqueries, are appropriately indexed. Indexes drastically speed up data retrieval. - Avoid Redundant Calculations: For non-correlated subqueries, the database executes them only once. However, for correlated subqueries, they execute for every row of the outer query. Minimize the complexity of correlated subqueries.
- Limit Result Sets: If a subquery is only needed to check for existence, consider
EXISTSorNOT EXISTSrather thanINwith a large result set, asEXISTScan stop processing as soon as it finds the first match. - Choose the Right Type: Understand if a scalar, row, or table subquery is truly needed. Sometimes a simpler approach suffices.
Alternatives to Subqueries (e.g., JOINs, CTEs)
Modern SQL offers powerful alternatives that can often outperform subqueries or provide clearer syntax for certain problems:
- JOINs (Inner, Left, Right, Full): For retrieving data that combines information from multiple tables,
JOINoperations are frequently more efficient than table subqueries in theFROMclause or correlated subqueries in theWHEREclause. Database optimizers are highly tuned forJOINs. - Common Table Expressions (CTEs –
WITHclause): CTEs allow you to define a temporary, named result set that you can reference within a singleSELECT,INSERT,UPDATE, orDELETEstatement. They enhance query readability and can sometimes improve performance by allowing the optimizer to better understand the query plan, especially for complex, multi-stage operations. CTEs are essentially named subqueries, but they can be recursive and often clearer. - Window Functions: For complex analytical tasks involving ranking, aggregation over a specific partition of data, or calculating moving averages, window functions (e.g.,
ROW_NUMBER(),RANK(),AVG() OVER()) are often far more efficient and concise than correlated subqueries. They process data in a single pass over the dataset, avoiding the row-by-row execution typical of many correlated subqueries.

Leveraging Subqueries for Scalable Solutions
Despite alternatives, subqueries remain indispensable. Their strength lies in their ability to express specific logical conditions that are otherwise difficult to formulate. For example, in dynamic pricing algorithms within e-commerce, a subquery might calculate a competitor’s lowest price for a product in real-time. In advanced geospatial mapping systems, a subquery could identify all points within a certain radius that meet a specific characteristic.
The key is to use subqueries judiciously, understanding their execution model, and combining them with other SQL features where appropriate. When applied thoughtfully, subqueries empower tech innovators to extract granular insights from complex data, enabling the development of smarter, more responsive, and data-driven applications that define the forefront of modern technology.