In the realm of computer science, particularly within the Java programming language, understanding fundamental data structures is crucial for efficient and scalable software development. Among these, the HashMap stands out as a ubiquitous and powerful tool for managing collections of data. At its core, a HashMap is an implementation of the Map interface that stores key-value pairs. This means that each piece of data, or value, is associated with a unique identifier, or key. This association allows for rapid retrieval of values when the corresponding key is known.
The fundamental principle behind a HashMap is hashing. When you insert a key-value pair, the HashMap computes a hash code for the key. This hash code is then used to determine the specific “bucket” or index within the underlying array where the key-value pair will be stored. When you later try to retrieve a value using its key, the HashMap once again computes the hash code for that key and directly accesses the corresponding bucket, significantly reducing the time it takes to find the desired data. This hashing mechanism is what enables the HashMap to offer average time complexities of O(1) for insertion, deletion, and retrieval operations, making it a cornerstone for many applications requiring quick lookups.
The Mechanics of HashMap: Hashing and Collisions
The efficiency of a HashMap hinges on the effective use of hashing. The process begins when you attempt to store an entry:
Hash Code Generation
When a key is inserted into a HashMap, its hashCode() method is invoked. Every object in Java inherits a hashCode() method from the Object class. However, for HashMap to function correctly and efficiently, the keys must implement this method in a way that produces distinct hash codes for distinct objects, whenever possible. A well-designed hashCode() method distributes keys evenly across the available buckets. Ideally, equal objects (as determined by the equals() method) should produce the same hash code.
Buckets and Array Storage
Internally, a HashMap uses an array to store its entries. Each element of this array is often referred to as a “bucket.” The hash code generated for a key is typically mapped to an index within this array. The formula for this mapping usually involves taking the hash code modulo the size of the array. For instance, if the array has a size of 16, and a key produces a hash code of 123, the entry might be placed in bucket 123 % 16 = 11.
Handling Collisions
The primary challenge in hashing is the possibility of “collisions.” A collision occurs when two different keys produce the same hash code, or when their hash codes map to the same array index. While a well-designed hashCode() and a sufficiently large array size minimize collisions, they cannot be entirely eliminated. Java’s HashMap handles collisions using a combination of techniques, primarily separate chaining and, more recently, treeification.
Separate Chaining
In older versions of Java (and still as a foundational concept), separate chaining was the predominant collision resolution strategy. When a collision occurs, all key-value pairs that hash to the same bucket are stored in a linked list within that bucket. So, if multiple keys hash to index 11, they would all be added to the linked list at index 11. When retrieving a value, the HashMap first finds the correct bucket using the key’s hash code and then iterates through the linked list in that bucket, comparing keys using the equals() method until the matching key is found. While this still offers O(1) average performance, in the worst-case scenario where all keys collide into a single bucket, the performance can degrade to O(n), where n is the number of entries in the map.
Treeification (Java 8 and later)
To address the performance degradation associated with long linked lists in separate chaining, Java 8 introduced a significant enhancement called “treeification.” If the number of entries in a particular bucket exceeds a certain threshold (typically 8), the linked list in that bucket is converted into a balanced tree, specifically a Red-Black Tree. This transformation changes the time complexity for searching within that bucket from O(n) to O(log n). This ensures that even in scenarios with many collisions, the HashMap maintains reasonably good performance. When an entry is removed from a tree-based bucket and the number of entries falls below another threshold (typically 6), it is converted back to a linked list.
Key Characteristics and Behavior of HashMap
Understanding the internal workings is important, but so is recognizing the practical implications of using a HashMap.
Null Keys and Values
HashMap allows for one null key and multiple null values. This flexibility can be useful in certain scenarios, although it’s generally advisable to use meaningful, non-null keys for clarity and to avoid potential confusion. When a null key is used, its hash code is effectively treated as 0, placing it in the first bucket of the internal array.
Unordered Nature
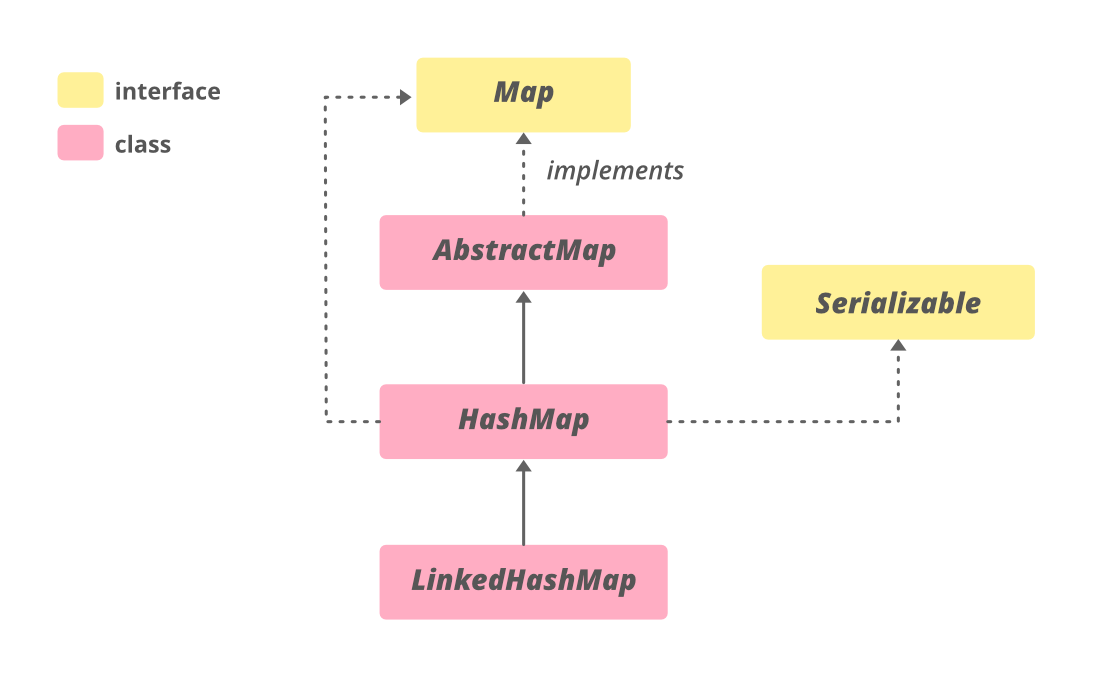
Unlike some other Map implementations like LinkedHashMap (which maintains insertion order) or TreeMap (which maintains sorted order), HashMap does not guarantee any specific order of its elements. The order in which you iterate through a HashMap might not be the same as the order in which you inserted the elements, and this order can even change over time as the map is modified and potentially resized. If order is important, you should consider using a different Map implementation.
Non-Synchronized
HashMap is not synchronized. This means that if multiple threads access a HashMap concurrently, and at least one of the threads modifies the map structurally (e.g., adds or removes an entry), the map must be synchronized externally. Failing to do so can lead to unpredictable behavior, including infinite loops or corrupted data. For thread-safe map implementations, Java provides ConcurrentHashMap or Collections.synchronizedMap().
Resizing and Rehashing
As more elements are added to a HashMap, the load factor (the ratio of the number of entries to the capacity of the map) increases. When the load factor exceeds a predefined threshold (by default, 0.75), the HashMap automatically resizes itself. This involves creating a new, larger internal array (typically double the size of the old one) and rehashing all existing entries into the new array. Rehashing is a necessary but computationally intensive process, as each key must be re-evaluated to determine its new bucket location in the larger array. This resizing operation contributes to the amortized O(1) performance of HashMap operations; while a single resize can be O(n), it happens infrequently enough that the average cost remains constant.
Common Use Cases for HashMap
The versatility and performance of HashMap make it a go-to choice for a wide array of programming tasks.
Caching
HashMap is an excellent choice for implementing caches. When you need to store and quickly retrieve frequently accessed data, a HashMap allows you to map a unique identifier (the cache key) to the data itself (the cache value). For instance, in a web application, you might cache expensive database query results or rendered HTML fragments, using unique identifiers derived from the request parameters as keys.
Frequency Counting
When you need to count the occurrences of items in a collection, HashMap is ideal. You can use the items themselves as keys and their counts as values. As you iterate through your collection, you check if an item already exists as a key in the HashMap. If it does, you increment its associated count. If not, you add the item as a new key with a count of 1.
Indexing and Lookups
HashMap excels at providing fast lookups. If you have a collection of objects and you need to quickly find a specific object based on a unique property, you can create a HashMap where that property serves as the key and the object itself is the value. For example, if you have a list of User objects and you need to retrieve a user by their userId, you can build a HashMap<String, User> where the userId is the key.
Storing Configuration Settings
Configuration parameters for applications are often stored in key-value pairs. A HashMap is a natural fit for this, allowing you to load configuration settings from a file or other source and then access them efficiently by their names (keys).
Representing Dictionaries or Associative Arrays
In many programming contexts, the terms “dictionary” or “associative array” are used interchangeably with “map.” HashMap in Java directly implements this concept, enabling you to associate arbitrary data values with unique keys, creating a flexible and powerful data structure for representing relationships between different pieces of information.
When to Choose HashMap vs. Other Map Implementations
While HashMap is a powerful default choice, understanding its alternatives is essential for optimizing your Java applications.
-
LinkedHashMap: UseLinkedHashMapwhen you need to maintain the order in which elements were inserted or when you need to access elements in their access order (useful for implementing LRU caches). It internally uses both a hash table and a linked list to achieve this. -
TreeMap: ChooseTreeMapwhen you require your map’s keys to be sorted in a natural order or according to a customComparator. It is implemented as a Red-Black Tree, ensuring O(log n) performance for most operations. -
ConcurrentHashMap: For thread-safe operations in multithreaded environments,ConcurrentHashMapis the preferred choice. It offers much better scalability and performance thanCollections.synchronizedMap()by allowing concurrent reads and writes without blocking all threads.
In conclusion, HashMap is a fundamental and highly efficient data structure in Java. Its ability to store and retrieve data using key-value pairs with average O(1) time complexity makes it indispensable for a vast range of applications. By understanding its underlying mechanics, including hashing, collision resolution, and resizing, developers can leverage its power to build robust, performant, and scalable Java programs.