Understanding Automated Data Extraction in the Digital Age
In an increasingly data-driven world, the ability to efficiently acquire and process vast amounts of information is paramount for technological advancement and innovation. Data scraping, at its core, refers to the automated process of extracting information from websites or other digital sources. Unlike manual data entry, which is labor-intensive and prone to human error, data scraping leverages specialized software or scripts to systematically collect structured or unstructured data at scale. This technique has become a cornerstone for numerous applications across the tech landscape, enabling unprecedented insights and powering cutting-edge solutions.

Defining Data Scraping: Beyond Manual Entry
Data scraping fundamentally involves programmatically reading and parsing data from a source that wasn’t primarily designed for automated consumption. While often associated with extracting information from public web pages (a practice commonly known as web scraping), the concept extends to various digital repositories, databases, and even documents. The distinction from manual data collection is crucial: scraping tools can visit thousands or millions of pages, extract specific data points, and consolidate them into a usable format (like a spreadsheet or database) in a fraction of the time it would take a human. This automation is vital for handling the sheer volume and velocity of data generated in the digital age, transforming raw information into actionable intelligence.
The Core Mechanics: Scripts, Bots, and Parsers
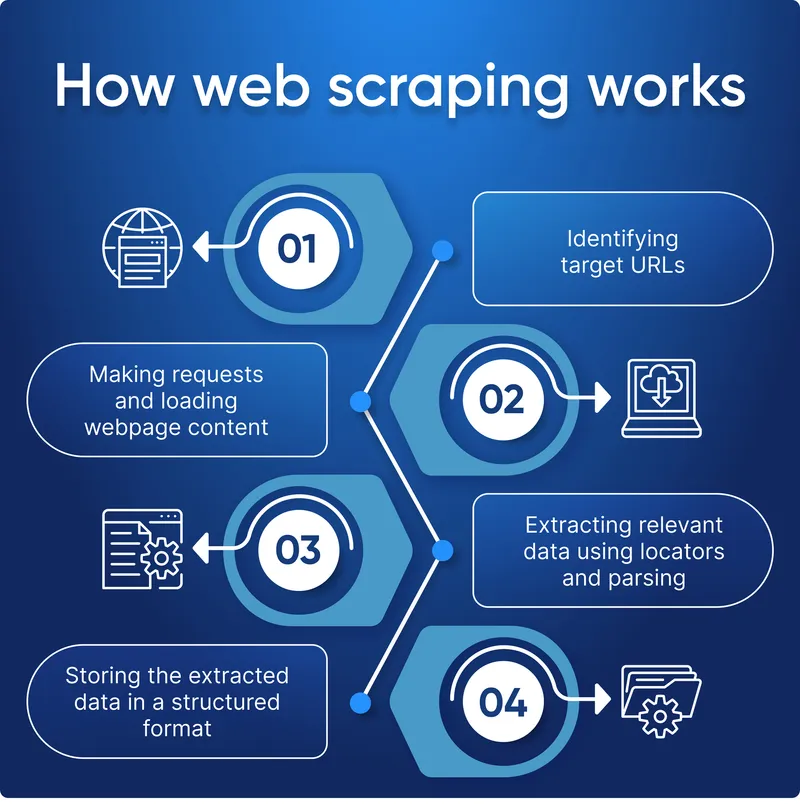
The operational principles behind data scraping revolve around sophisticated software components. At its simplest, a data scraping tool is a bot or a script designed to mimic human browsing behavior. It sends HTTP requests to web servers, much like a web browser does, and receives the raw HTML content of a page. Once the content is received, a “parser” component takes over. Parsers are specialized algorithms or libraries that analyze the structure of the HTML (or other data formats like XML or JSON) to identify and extract the specific pieces of information desired. This often involves navigating the Document Object Model (DOM) to pinpoint elements by their tags, classes, or IDs. More advanced scrapers can handle complex scenarios like JavaScript-rendered content, CAPTCHAs, dynamic loading, and session management, effectively simulating an interactive user experience to access and extract data that might not be immediately visible in the initial page load.
The Engine of Innovation: Applications Across Tech Sectors
The ability to programmatically gather vast datasets has profound implications for innovation across virtually every tech sector. Data scraping acts as a critical enabler, providing the raw material necessary for training advanced algorithms, informing strategic decisions, and fueling groundbreaking research. Its applications span from enhancing artificial intelligence capabilities to providing real-time market intelligence and supporting complex spatial analytics.
Fueling Artificial Intelligence and Machine Learning
One of the most significant impacts of data scraping is its role in advancing Artificial Intelligence (AI) and Machine Learning (ML). These technologies are inherently data-hungry, requiring massive, diverse datasets for training, validation, and testing. Data scraping provides an efficient means to acquire this data. For instance, natural language processing (NLP) models can be trained on scraped text from news articles, social media, and academic papers to understand context, sentiment, and linguistic nuances. Computer vision models benefit from vast collections of images and videos scraped from various sources to learn object recognition, facial detection, and scene understanding. In the context of autonomous systems, historical data on environmental conditions, traffic patterns, and sensor readings, potentially aggregated through scraping techniques from public repositories, can be crucial for developing robust navigation and decision-making algorithms. The iterative process of collecting, refining, and applying scraped data is fundamental to the continuous improvement and innovation within the AI/ML domain.
Driving Market Intelligence and Strategic Decision-Making
For businesses and organizations, data scraping offers unparalleled capabilities for market intelligence and strategic decision-making. Companies can scrape competitor pricing, product features, customer reviews, and market trends to gain a competitive edge. This real-time visibility allows for agile adjustments in pricing strategies, product development, and marketing campaigns. Beyond competitive analysis, scraping public sentiment from social media or news outlets can provide early warnings about brand perception or emerging societal trends. In financial markets, data scraping is used to gather financial news, stock market data, and economic indicators, feeding into algorithmic trading strategies and predictive models. The strategic insights derived from meticulously scraped and analyzed data enable organizations to innovate faster, respond more effectively to market changes, and optimize their operations for greater efficiency and profitability.
Enhancing Research, Development, and Spatial Analytics
Research and development (R&D) across scientific and engineering disciplines heavily relies on access to current and comprehensive data. Data scraping facilitates this by enabling researchers to compile vast bodies of academic literature, patent databases, and scientific datasets that would be impossible to gather manually. This accelerates discovery, identifies research gaps, and prevents duplication of effort. In spatial analytics and remote sensing, while direct drone data collection is distinct, the principles of automated data acquisition are highly relevant. Public repositories often contain geospatial data, historical satellite imagery, weather patterns, and environmental parameters. Data scraping techniques can be used to aggregate and prepare this auxiliary data, enriching drone-collected imagery or sensor readings. For example, a project mapping urban heat islands using thermal drones might scrape historical temperature data from meteorological archives, property data from real estate sites, and demographic information from public census websites to provide a comprehensive analytical framework. This integration of scraped contextual data with primary sensor data yields richer, more actionable insights for urban planning, environmental monitoring, and disaster management.
Methodologies and Tools for Intelligent Data Harvesting
The landscape of data scraping is diverse, encompassing a range of methodologies and tools tailored to different complexities and scales of data extraction. From highly customized programmatic approaches to user-friendly cloud-based platforms, the evolution of these tools reflects the growing demand for efficient data acquisition in an innovation-driven economy.
Programmatic Approaches: APIs, Libraries, and Frameworks
At the core of many sophisticated scraping operations are programmatic approaches. Developers often leverage programming languages like Python (with libraries such as Beautiful Soup, Scrapy, and Selenium), JavaScript (Node.js with libraries like Puppeteer), or Ruby (Nokogiri) to build custom scrapers. These tools offer granular control over the scraping process, allowing for handling complex website structures, dynamic content, pagination, and various anti-scraping measures. While custom scripts provide maximum flexibility, they require significant development effort and ongoing maintenance to adapt to website changes. Another key methodology involves Application Programming Interfaces (APIs). Many websites and services offer public APIs, which are designed specifically for programmatic data access. While not “scraping” in the traditional sense, utilizing APIs is the preferred, most ethical, and most stable method for data retrieval when available, as it implies explicit permission and structured data delivery. When an API is not present or insufficient, custom scraping frameworks become the next best alternative, offering a balance between automation and control.

Dedicated Platforms and Cloud-Based Solutions
Beyond custom coding, a robust ecosystem of dedicated data scraping platforms and cloud-based services has emerged. These tools often provide graphical user interfaces (GUIs) that allow users to visually define the data points they wish to extract, simplifying the process for non-programmers. Platforms like Octoparse, ParseHub, and Import.io offer intuitive drag-and-drop interfaces to build scrapers, manage proxies, schedule tasks, and export data in various formats. Cloud-based solutions abstract away the infrastructure complexities, running scrapers on remote servers and handling scalability, IP rotation, and CAPTCHA solving. These services democratize data access, enabling smaller businesses, researchers, and individuals to leverage the power of automated data extraction without significant technical overhead. They represent a significant innovation in making data acquisition more accessible and efficient for a wider audience, driving broader participation in data-driven innovation.
From Structured to Unstructured Data: Advanced Techniques
Modern data scraping extends beyond merely extracting well-defined data fields from structured web pages. Advanced techniques are continuously being developed to handle more complex scenarios, particularly the extraction of insights from unstructured data. Natural Language Processing (NLP) and Machine Learning (ML) are increasingly integrated into scraping workflows to extract sentiment, entities, and relationships from free-form text, such as product reviews, social media posts, or news articles. Image and video scraping, combined with computer vision, allows for the analysis of visual content for specific features, object identification, or metadata extraction. Techniques like headless browser automation using tools such as Selenium or Puppeteer are essential for scraping data from single-page applications (SPAs) that heavily rely on JavaScript to render content dynamically. These advancements mean that data scrapers can now process richer, more diverse forms of data, unlocking new possibilities for analysis and innovation that were previously unattainable.
Navigating the Complexities: Ethics, Legality, and Responsible Innovation
While data scraping offers immense potential for innovation, its implementation is fraught with ethical and legal complexities. Responsible innovation demands a careful consideration of data privacy, intellectual property rights, and website terms of service. Navigating this intricate landscape is crucial for sustainable and ethical technological development.
Ethical Considerations: Data Privacy and Resource Respect
Ethical data scraping centers on two main pillars: respecting data privacy and being a good digital citizen. Scraping personal identifiable information (PII) without consent or legitimate grounds raises significant privacy concerns and can lead to severe reputational damage and legal repercussions. Developers and users of scraping tools must ensure compliance with privacy regulations like GDPR and CCPA. Furthermore, aggressive or poorly designed scrapers can put a significant load on target websites, consuming server resources and potentially impacting legitimate user experience. This constitutes a lack of respect for the website’s infrastructure and its owners. Ethical scraping practices include adhering to robots.txt guidelines, throttling request rates to avoid overloading servers, and identifying oneself in HTTP headers. The ethical imperative is to operate transparently and responsibly, recognizing the impact of automated data collection on both individuals and online service providers.
Legal Frameworks and Compliance Challenges
The legality of data scraping is a constantly evolving and often ambiguous area. It typically hinges on several factors, including whether the data is publicly accessible, whether it constitutes intellectual property, the intent behind the scraping, and the terms of service (ToS) of the website being scraped. While publicly available data is generally not subject to copyright in itself, the way it’s presented or structured on a website might be. Breaching a website’s ToS, even if the data is public, can sometimes lead to legal action for breach of contract. High-profile cases have set precedents, but legal interpretations vary significantly across jurisdictions. Moreover, specific laws regarding data privacy (e.g., GDPR in Europe) explicitly regulate how personal data can be collected, processed, and stored, irrespective of whether it was publicly available. Staying abreast of these complex and evolving legal frameworks is a significant challenge for any entity engaged in data scraping, demanding careful legal counsel and a proactive approach to compliance.
Promoting Responsible Data Practices for Sustainable Innovation
For data scraping to continue contributing to sustainable innovation, it must be underpinned by responsible data practices. This involves not only adhering to legal requirements and ethical guidelines but also promoting a culture of transparency and accountability. Developers of scraping tools should build in features that encourage responsible behavior, such as rate limiting and robots.txt compliance. Organizations utilizing scraped data must implement robust data governance policies, ensuring that collected data is processed securely, used only for its intended purpose, and deleted when no longer necessary. Education about the implications of data scraping for privacy, security, and intellectual property is also vital. By fostering an environment where ethical considerations are integrated into every stage of the data lifecycle, the tech community can harness the power of data scraping for innovation while mitigating its potential harms, leading to more trustworthy and sustainable technological progress.
The Evolving Landscape: Data Scraping and Future Technologies
The trajectory of data scraping is inextricably linked to the broader evolution of digital technologies. As AI, autonomous systems, and big data continue to reshape the tech landscape, data scraping is adapting and integrating with these advancements, paving the way for even more sophisticated data-driven innovations.
Real-time Data Streams and Predictive Analytics
The future of data scraping is increasingly moving towards real-time or near real-time data acquisition, shifting from batch processing to continuous streams. This shift is critical for applications demanding immediate insights, such as financial trading, real-time market sentiment analysis, or dynamic pricing models. Integrating scraped data with stream processing technologies allows businesses and researchers to react instantaneously to unfolding events, enabling predictive analytics with greater accuracy and timeliness. For instance, monitoring changes in product availability or competitor promotions in real-time can trigger automated business responses. This capability to tap into dynamic data streams is fundamental for powering the next generation of intelligent, responsive systems that can adapt to rapidly changing digital environments.
Integration with Autonomous Systems and Edge Computing
The synergy between data scraping and autonomous systems, including those leveraging drones, represents a frontier of innovation. While drones directly collect their own sensor data, the preparatory and contextual data necessary for their autonomous operation can benefit from advanced data acquisition. For example, autonomous vehicles require constantly updated maps, traffic conditions, and local regulations; data scraping could contribute to aggregating this external information. Edge computing plays a role by enabling some scraping and preliminary data processing closer to the data source, reducing latency and bandwidth requirements. This localized processing can filter irrelevant data, enhance security, and deliver only critical information to the central cloud for further analysis by AI models that guide autonomous decisions. This integration underscores the role of robust data provisioning, partially enabled by scraping techniques, in the functionality and intelligence of future autonomous technologies.
The Synergy with Big Data and Cloud Infrastructures
Data scraping is a critical feeder for big data initiatives. The sheer volume of data collected through scraping necessitates robust big data storage and processing capabilities, typically provided by cloud infrastructures. Cloud platforms offer scalable resources for storing petabytes of scraped data, powerful computing for running complex analytics, and sophisticated tools for data warehousing and visualization. Technologies like Hadoop, Spark, and cloud data lakes are essential for managing, cleaning, and transforming the vast, often messy, datasets acquired through scraping. This synergy allows organizations to derive deep insights from massive datasets that would be impossible to handle with traditional methods. As cloud technologies continue to mature and become more accessible, the capacity to collect and analyze even larger and more diverse datasets through automated scraping will only grow, further driving innovation in fields ranging from scientific discovery to personalized consumer experiences.