In the realm of technology and innovation, the efficient and reliable management of information is paramount. As we push the boundaries of what’s possible with autonomous systems, advanced mapping, and remote sensing, the underlying data infrastructure becomes increasingly critical. One fundamental concept that underpins robust database design for these cutting-edge applications is data normalization. While often perceived as a purely technical database concept, its principles directly impact the effectiveness and scalability of the data pipelines that power our most sophisticated tech and innovation endeavors.
Normalization, at its core, is a database design technique aimed at reducing data redundancy and improving data integrity. It involves organizing data into tables in a way that ensures dependencies are correctly applied. This process breaks down larger tables into smaller, more manageable ones and defines relationships between them. The ultimate goal is to eliminate undesirable characteristics like insertion, update, and deletion anomalies, ensuring that data remains consistent and accurate across the entire database.
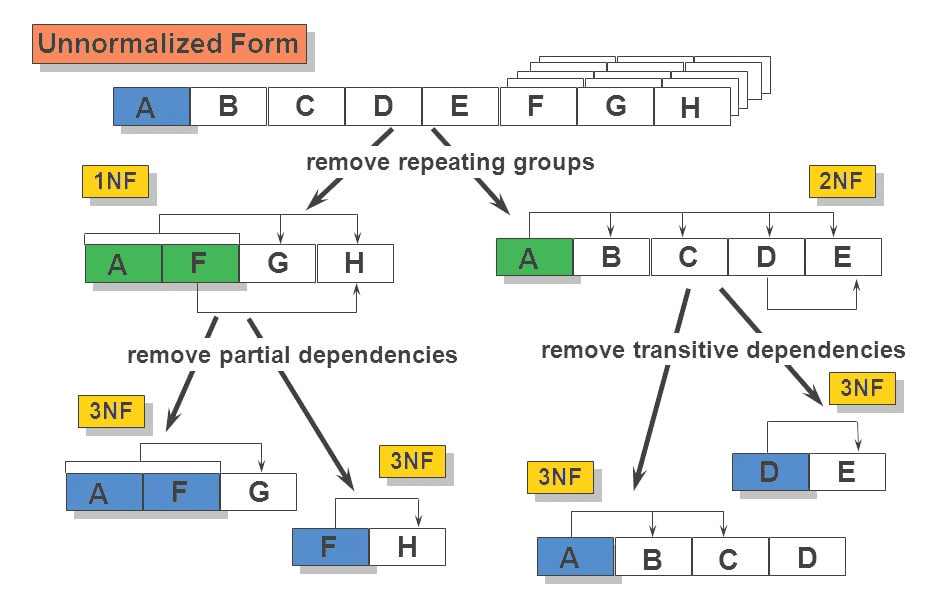
Understanding the Core Principles of Data Normalization
Data normalization is not a single step but rather a series of guidelines, known as normal forms. Each normal form builds upon the previous one, progressively refining the database structure. While there are many normal forms, the first three (1NF, 2NF, and 3NF) are the most commonly applied in practical database design. Understanding these forms is key to appreciating how normalization achieves its objectives.
First Normal Form (1NF): Eliminating Repeating Groups
The foundational step in normalization is achieving First Normal Form (1NF). A relation (table) is in 1NF if and only if all of its attribute values are atomic. This means that each cell in the table contains a single, indivisible piece of data. In simpler terms, you shouldn’t have multiple values within a single field, nor should you have repeating groups of columns.
For example, consider a table storing information about drone flight missions. If a single record contained a list of all sensors used in a mission within a single “sensors” field, this would violate 1NF. To achieve 1NF, this would need to be broken down. One way is to create a separate table for sensors, linking each sensor to a specific mission.
Key characteristics of 1NF:
- Atomicity of Attributes: Each column contains atomic, single values.
- Uniqueness of Rows: Each row in the table is unique.
- No Repeating Groups: Columns do not contain lists or sets of values.
Achieving 1NF is the prerequisite for moving to higher normal forms. It lays the groundwork for a more structured and organized database, preventing the ambiguity that arises from multi-valued fields.
Second Normal Form (2NF): Removing Partial Dependencies
Once a database is in 1NF, the next step is to ensure it adheres to Second Normal Form (2NF). 2NF applies to tables that have composite primary keys (keys made up of two or more columns). A table is in 2NF if it is in 1NF and all non-key attributes are fully functionally dependent on the entire primary key. This means that no non-key attribute should depend on only a part of the composite primary key.
Imagine a table that records drone flight path segments and the specific battery used for each segment. If the primary key is a composite of (flight_segment_id, battery_serial_number), and the battery_capacity attribute depends solely on battery_serial_number (a part of the key), this creates a partial dependency and violates 2NF. The battery capacity is relevant to the battery itself, not specifically to that particular flight segment’s use of the battery.
To rectify this, the table would be split. The battery_capacity would be moved to a separate “Batteries” table, where battery_serial_number would be the primary key. The original table would then reference this “Batteries” table. This ensures that battery information is stored once and updated in one place, preventing inconsistencies if the same battery is used across multiple flight segments.
Key characteristics of 2NF:
- Must be in 1NF: The table must first satisfy the conditions of 1NF.
- Full Functional Dependency: All non-key attributes must depend on the entire primary key, not just a part of it.
2NF is crucial for reducing redundancy when dealing with composite keys, ensuring that information relevant to only a portion of the key isn’t duplicated across multiple rows.
Third Normal Form (3NF): Eliminating Transitive Dependencies
The final widely adopted normal form is Third Normal Form (3NF). A table is in 3NF if it is in 2NF and there are no transitive dependencies. A transitive dependency occurs when a non-key attribute is dependent on another non-key attribute, which in turn is dependent on the primary key. In essence, it’s an indirect dependency.

Consider a table that stores drone model information, including the manufacturer’s name and the manufacturer’s headquarters location. If the primary key is drone_model_id, then manufacturer_name might be dependent on drone_model_id. However, the manufacturer_headquarters_location might be dependent on manufacturer_name, which is itself a non-key attribute. This creates a transitive dependency: drone_model_id -> manufacturer_name -> manufacturer_headquarters_location.
If the headquarters location for a manufacturer changes, you would have to update it in every row where that manufacturer’s drone model appears. This is inefficient and prone to errors. To achieve 3NF, this would be resolved by creating a “Manufacturers” table with manufacturer_name as the primary key, storing the headquarters location there. The drone model table would then contain a foreign key referencing the manufacturer_name in the “Manufacturers” table.
Key characteristics of 3NF:
- Must be in 2NF: The table must first satisfy the conditions of 2NF.
- No Transitive Dependencies: Non-key attributes cannot be dependent on other non-key attributes.
3NF is vital for maintaining data integrity by ensuring that facts about an entity are stored directly and not indirectly through other non-key attributes. This minimizes update anomalies and simplifies maintenance.
The Practical Implications for Tech & Innovation
While the theoretical underpinnings of data normalization might seem distant from the exciting world of autonomous flight or advanced imaging, their practical implications are profound, especially within the “Tech & Innovation” category.
Enhancing Data Integrity for AI and Autonomous Systems
The efficacy of AI algorithms, particularly those involved in drone navigation, object recognition, and autonomous decision-making, relies heavily on clean and consistent data. Unnormalized databases can lead to:
- Inconsistent Sensor Readings: If sensor calibration data is duplicated and inconsistently updated, AI models might interpret faulty readings, leading to navigation errors or incorrect environmental assessments.
- Flawed Mission Logs: Redundant and inconsistent mission parameters (e.g., altitude, speed, target waypoints) can corrupt training data for autonomous flight, impacting the reliability of future missions.
- Anomalous Environmental Data: For remote sensing and mapping applications, inconsistent storage of geographical features or sensor metadata can lead to inaccuracies in generated maps and analyses, potentially misinforming research or operational decisions.
By normalizing data, we ensure that each piece of information, whether it’s a sensor type, a mission parameter, or a geographical coordinate, is stored and managed in a single, authoritative location. This significantly reduces the likelihood of contradictory data influencing AI processing and autonomous operations.
Scalability and Performance for Large Datasets
As the scope of tech and innovation projects expands, so does the volume of data generated. Think of high-resolution aerial imagery from multiple drones, intricate lidar point clouds for 3D mapping, or vast telemetry logs from extended autonomous flights.
- Reduced Storage Footprint: Normalization eliminates redundant data, leading to smaller database sizes. This is crucial when dealing with terabytes or petabytes of information generated by advanced imaging and sensing technologies.
- Faster Query Performance: With normalized data, queries are more targeted. Instead of scanning massive, de-normalized tables, the database can efficiently retrieve information from smaller, linked tables. This is critical for real-time analysis and decision-making in autonomous systems.
- Efficient Updates and Insertions: When data needs to be added or modified, normalization ensures that these operations are performed efficiently, without the need to update multiple records. This is vital for continuous data streams from drones and sensors.
Streamlining Development and Maintenance
For teams building complex technological solutions, a well-normalized database simplifies the development process.
- Clearer Data Relationships: Normalization forces developers to think critically about how different pieces of information relate to each other, leading to more intuitive and maintainable code.
- Reduced Complexity: Instead of dealing with intricate, de-normalized structures, developers can work with well-defined tables and relationships, making it easier to understand and modify the database schema.
- Easier Integration: Normalized data models facilitate easier integration with other systems and applications, which is often necessary in the interconnected world of modern technology.
Beyond 3NF: Higher Normal Forms and Denormalization
While 3NF is often sufficient for many applications, higher normal forms exist, such as Boyce-Codd Normal Form (BCNF) and Fourth Normal Form (4NF). These address more complex dependencies and anomalies. However, applying them can sometimes lead to an excessive number of tables, increasing query complexity.
In some performance-critical scenarios, a degree of denormalization might be employed. Denormalization involves intentionally introducing some redundancy back into the database structure to optimize read performance, often at the expense of write performance and increased storage. This is a trade-off made strategically, usually after a normalized design has been established and performance bottlenecks have been identified. For example, in a system where frequently accessed derived data is needed for immediate display, that data might be pre-calculated and stored in a separate table.
For the “Tech & Innovation” category, especially in areas like AI training, mapping, and remote sensing, a solid understanding and application of 3NF provide a robust foundation. Strategic denormalization can then be considered for specific performance bottlenecks where immediate data retrieval is paramount, ensuring that cutting-edge technologies are powered by efficient and reliable data management. Data normalization, therefore, is not just a database concept; it’s a critical enabler of accuracy, scalability, and innovation in the most advanced technological frontiers.