The Core of Modern Data Integration: An Essential Tech Innovation
The digital era is defined by data—its volume, velocity, and variety. Organizations across every sector are grappling with an unprecedented deluge of information, stemming from diverse sources ranging from on-premises databases and enterprise applications to cloud services, IoT devices, social media feeds, and external APIs. This proliferation of data presents both an immense opportunity and a significant challenge. Raw data, in its fragmented and disparate forms, offers little direct value. Its true potential is unlocked only when it is effectively extracted, transformed, and loaded (ETL) into a cohesive, analytics-ready state. This complex process of data integration, orchestration, and preparation is where groundbreaking technologies truly shine, providing scalable, efficient, and robust solutions for data ingestion and refinement.
Microsoft Azure Data Factory (ADF) emerges as a pivotal cloud-based ETL and data integration service designed precisely to address these contemporary data challenges. It stands as a testament to innovation in data engineering, offering a fully managed, serverless platform that empowers enterprises to construct intricate data pipelines capable of orchestrating data movement and transformations across a vast ecosystem of interconnected data stores. ADF’s primary purpose is to automate and streamline the often laborious and error-prone tasks associated with preparing data for analytics, reporting, and machine learning initiatives. As a cornerstone of modern data architecture, ADF exemplifies “Tech & Innovation” by abstracting away the underlying infrastructure complexities, allowing data professionals to focus purely on the logic and flow of their data workflows, making it a critical enabler for data-driven decision-making in any advanced technological landscape.
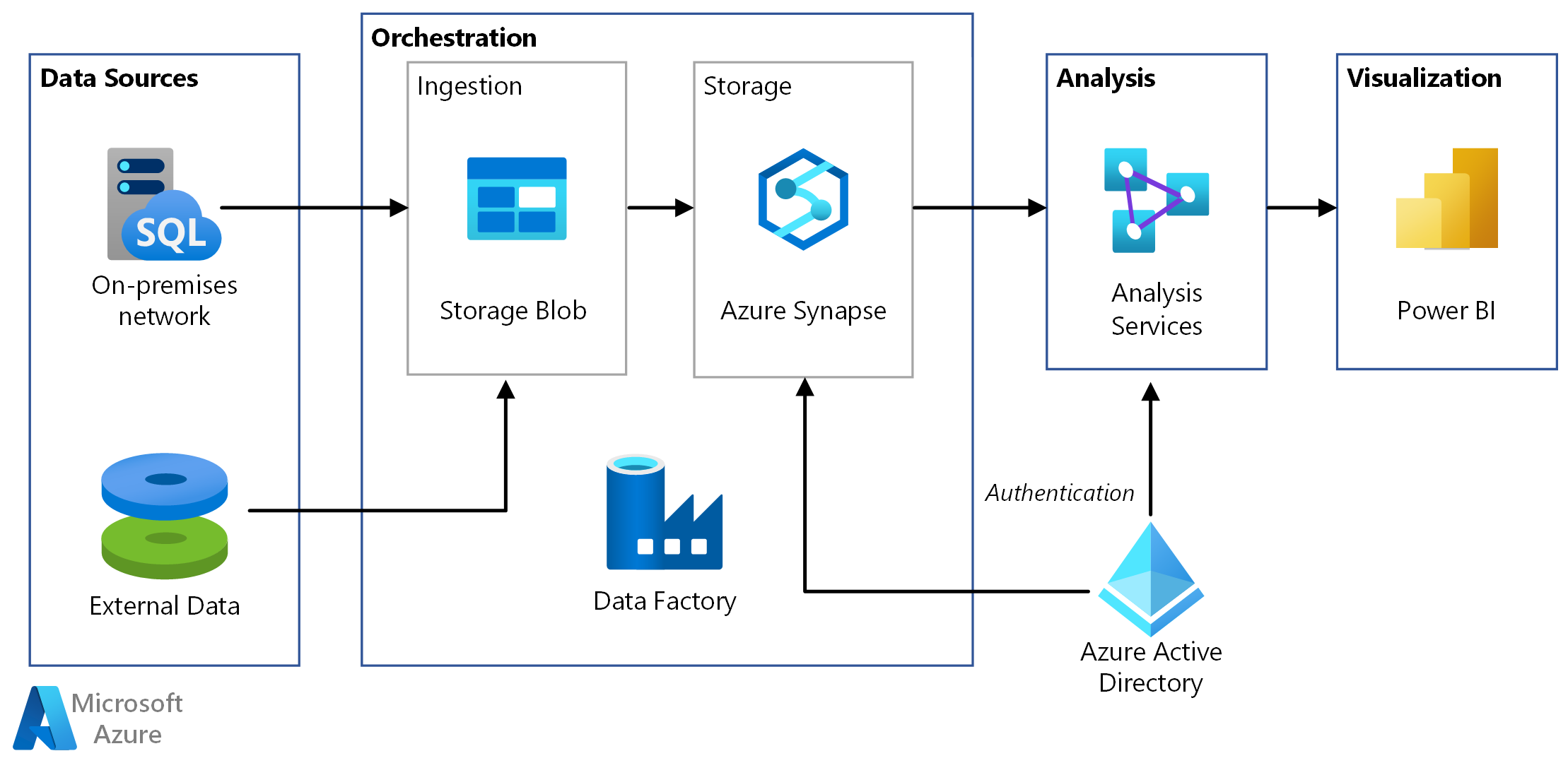
Architecting Data Workflows: Key Components and Concepts in ADF
At the heart of Azure Data Factory’s innovation lies its intuitive, modular architecture, which provides the building blocks for constructing powerful data integration solutions. Understanding these core components is crucial for leveraging ADF’s full capabilities and appreciating its role in modern data processing.
Orchestration with Pipelines and Activities
The fundamental unit of work in Azure Data Factory is a pipeline. Conceptually, a pipeline is a logical grouping of activities that perform a specific task. It represents a complete workflow, akin to a flowchart or a sequence of operations that guide data from its origin to its destination, undergoing necessary transformations along the way. Within each pipeline, individual operations are executed as activities. These activities are the discrete steps that carry out actions such as copying data from one source to another, transforming data using various compute services, or invoking external code.
ADF supports several types of activities:
- Data Movement Activities: The most common is the Copy Activity, which facilitates high-throughput, secure, and performant data transfer between over 100 different data stores, both cloud-based and on-premises.
- Data Transformation Activities: These activities allow for data manipulation. Examples include Data Flow activities (for code-free data transformations at scale), Stored Procedure activities (to execute SQL procedures), Databricks Notebook/JAR/Python activities, HDInsight Hive/Pig/Spark activities, and Azure Machine Learning activities (for predictive analytics).
- Control Flow Activities: These govern the flow of the pipeline, enabling conditional execution (If Condition), iteration (For Each), waiting (Wait), executing multiple activities in parallel (Execute Pipeline), and setting variables. This rich set of control flow options allows for the creation of highly sophisticated and resilient data workflows.
Connecting Data Sources with Linked Services and Datasets
To interact with external resources, Azure Data Factory relies on two crucial components: Linked Services and Datasets.
A Linked Service is essentially a connection string that defines the connection information needed for Data Factory to link to an external data store or compute service. It’s similar to a connection string in traditional programming, containing parameters like server name, database name, credentials, and network configuration. ADF offers an extensive array of linked services for popular data sources like Azure Blob Storage, Azure SQL Database, Azure Synapse Analytics, Amazon S3, Google Cloud Storage, Oracle, SAP, Salesforce, and many more, ensuring broad connectivity.
A Dataset, on the other hand, is a named view of data within a linked service. It represents the structure, format, and schema of the data that you want to ingest or produce. While a linked service points to the data store, a dataset points to a specific file, folder, table, or query within that data store, providing a schema-on-read capability that defines how ADF should interpret the data.
Execution Environments: Integration Runtime
The Integration Runtime (IR) is the compute infrastructure that Azure Data Factory uses to execute activities. It acts as a bridge, enabling ADF to connect to different network environments and data stores securely and efficiently. There are three main types of Integration Runtimes:
- Azure Integration Runtime: This is a fully managed, serverless compute environment hosted in Azure. It’s used for data movement between cloud data stores, dispatching activities to various Azure compute services (like Databricks or HDInsight), and running Data Flow activities. It requires no infrastructure management from the user.
- Self-Hosted Integration Runtime (SHIR): For scenarios involving data stores located on-premises or within a private network (like an Azure Virtual Network), the SHIR acts as an agent installed on a customer-managed machine. It securely connects to the data sources behind firewalls, bridging the gap between on-premises environments and the Azure cloud, ensuring secure and private data movement without opening network ports.
- Azure-SSIS Integration Runtime: This specialized IR allows organizations to lift and shift their existing SQL Server Integration Services (SSIS) packages to Azure. It provides a managed environment to run SSIS workloads natively in the cloud, leveraging ADF’s orchestration capabilities.
Triggering and Monitoring Data Flows
ADF pipelines can be executed manually, but their real power for “Tech & Innovation” comes from automated execution via Triggers. Triggers define when a pipeline should run, based on various criteria. Common trigger types include:
- Schedule Trigger: Executes pipelines at recurring intervals (e.g., hourly, daily, weekly).
- Tumbling Window Trigger: Fires on a periodic basis, but maintains a one-to-one relationship with the window it produces, typically used for historical backfills or processing data in contiguous, non-overlapping time slices.
- Event-Based Trigger: Initiates pipelines in response to events occurring in Azure Storage, such as a file being created, deleted, or updated in a blob container.

For operational oversight, Azure Data Factory provides robust monitoring tools. These tools offer a comprehensive view of pipeline runs, activity status, and resource consumption. Users can track the progress of their data flows in real-time, review logs, troubleshoot errors, and set up alerts to proactively manage their data integration processes, ensuring reliability and performance.
Unlocking Data Value: Capabilities and Advanced Use Cases
Azure Data Factory’s comprehensive suite of capabilities extends far beyond basic data movement, making it an indispensable tool for complex data engineering challenges and a clear example of technological advancement.
Comprehensive Data Movement and Transformation
ADF excels at both high-volume data ingestion and sophisticated data transformation. The Copy Activity is optimized for speed and security, allowing petabytes of data to be transferred efficiently. For more intricate transformations, Data Flows (Mapping Data Flows) offer a visual, code-free environment to design, build, and manage data transformations at scale. This innovative feature allows data engineers to construct complex ETL and ELT processes by simply dragging and dropping transformation components (e.g., joins, aggregations, filters, sorts) onto a canvas. Behind the scenes, ADF translates these visual designs into optimized Spark code, which is executed on serverless Spark clusters, abstracting away the complexity of big data processing. This significantly democratizes complex data manipulation, making advanced analytics more accessible.
Furthermore, ADF’s code-free development experience, combined with its robust integration with Azure DevOps, facilitates collaborative development, version control, and continuous integration/continuous deployment (CI/CD) pipelines, streamlining the entire data lifecycle management. Its hybrid data integration capabilities are particularly noteworthy, enabling seamless connectivity and data flow between on-premises systems and cloud environments, which is critical for organizations undergoing digital transformation.
Real-world Applications as Tech Innovation
Azure Data Factory is instrumental in a multitude of contemporary scenarios, empowering enterprises to derive profound insights from their data:
- Data Warehousing and Analytics: ADF is often the critical first step in populating modern data warehouses like Azure Synapse Analytics. It orchestrates the ingestion, cleansing, and transformation of raw data from various operational systems into a structured format suitable for business intelligence dashboards and analytical reports, enabling faster, more accurate insights.
- Hybrid Data Migration and Modernization: Organizations leverage ADF to migrate large, complex datasets from legacy on-premises databases and file systems to Azure cloud storage and databases. This facilitates cloud adoption strategies and modernizes data platforms, reducing operational costs and enhancing scalability.
- IoT Data Processing and Telemetry: While not exclusively drone-related, the principles apply broadly to any form of sensor or telemetry data. Modern technological ecosystems, including IoT devices and advanced robotics, generate massive streams of data. ADF can ingest this raw data from various sources, clean it, aggregate it, and prepare it for real-time analytics dashboards or archival in data lakes, providing critical operational intelligence. This demonstrates its flexibility in handling diverse, high-volume data streams essential for cutting-edge technology.
- Application Log Analytics: Consolidating log data from myriad applications, microservices, and infrastructure components into a centralized analytical platform is crucial for operational visibility and troubleshooting. ADF orchestrates the collection and preparation of this log data, making it amenable to querying and analysis for performance monitoring and security auditing.
- Machine Learning Data Preparation: A significant component of artificial intelligence and machine learning initiatives is the preparation of high-quality training data. ADF plays a vital role in this process by cleaning, transforming, normalizing, and feature-engineering datasets from disparate sources, ensuring that data is in the optimal format for training robust AI/ML models. This directly fuels advanced AI capabilities and predictive analytics.
The Strategic Advantage of Azure Data Factory in the Enterprise
As a flagship service within the Azure ecosystem, Data Factory offers compelling strategic advantages that underscore its position as a leading “Tech & Innovation” platform for data management.
Scalability and Performance
ADF is built on a highly scalable, distributed architecture. It can elastically scale on demand to handle virtually any volume of data, from gigabytes to petabytes, without requiring users to manage underlying compute resources. Its parallel processing capabilities ensure that data integration tasks are executed efficiently and quickly, meeting the performance requirements of even the most demanding enterprise workloads. This inherent scalability is crucial for organizations dealing with ever-growing data volumes and increasing analytical demands.
Cost-Effectiveness
Being a serverless platform, Azure Data Factory operates on a pay-as-you-go model. Organizations only pay for the resources consumed during pipeline execution, eliminating the need for upfront investments in hardware or ongoing maintenance of infrastructure. This cost-efficiency is a significant advantage, particularly for businesses seeking to optimize their IT expenditures while gaining access to powerful data integration capabilities. Resource utilization is optimized automatically, leading to a lower total cost of ownership.
Robustness and Security
Azure Data Factory is engineered for enterprise-grade reliability and security. It offers built-in monitoring, comprehensive logging, error handling, and alerting mechanisms to ensure that data flows are resilient and operational issues can be addressed swiftly. Security is paramount, with seamless integration with Azure security features such as Azure Virtual Networks (VNETs), Azure Private Link for secure data access, and Azure Key Vault for managing credentials. Data in transit is encrypted, and strict access controls can be enforced, safeguarding sensitive information throughout the data journey.

Empowering Data-Driven Decisions
Ultimately, the most profound strategic advantage of Azure Data Factory lies in its ability to empower organizations to become truly data-driven. By simplifying and accelerating the complex process of data integration and transformation, ADF enables businesses to consolidate disparate data sources, prepare data for advanced analytics, fuel machine learning models, and deliver timely, accurate insights to decision-makers. It serves as the intelligent orchestration layer for any modern data platform, facilitating the continuous flow of clean, contextualized data that is essential for innovation, competitive advantage, and informed strategic planning in today’s rapidly evolving technological landscape.