The landscape of technology is in perpetual motion, constantly unveiling innovations that reshape how we interact with information, automate tasks, and even understand intelligence itself. Among these groundbreaking advancements, ChatGPT has emerged as a phenomenon, not just within the specialized circles of artificial intelligence research but across the global consciousness. It represents a significant leap forward in conversational AI, captivating users with its ability to generate human-like text, answer complex questions, write code, and engage in surprisingly nuanced dialogues. More than just a chatbot, ChatGPT is a powerful demonstration of the capabilities of large language models (LLMs) and a harbinger of future technological paradigms.
At its core, ChatGPT is an artificial intelligence model developed by OpenAI, designed to understand and generate human language. Its name is an acronym for “Chat Generative Pre-trained Transformer.” Each component of this name offers a clue to its nature: “Chat” signifies its conversational interface; “Generative” points to its ability to create novel text; “Pre-trained” indicates it has learned from a vast dataset before being fine-tuned for specific tasks; and “Transformer” refers to the neural network architecture that underpins its impressive performance. Unveiled to the public in late 2022, ChatGPT quickly moved beyond novelty, demonstrating practical applications that span a multitude of industries and personal uses, from assisting with creative writing and complex problem-solving to revolutionizing customer service and educational support. Understanding ChatGPT means delving into the innovation that powers it, its diverse applications, and the profound implications it holds for the future of technology and society.
The Genesis of Conversational AI: A Journey Through Technological Innovation
The path to sophisticated conversational AI like ChatGPT is paved with decades of research and iterative technological breakthroughs. From early rule-based systems to the neural network revolution, each era contributed foundational elements that culminated in today’s advanced models.
From Rule-Based Systems to Neural Networks
Early attempts at artificial intelligence, particularly in natural language processing (NLP), were largely characterized by symbolic AI and rule-based systems. These programs relied on meticulously crafted rules, grammars, and lexicons to process and generate text. ELIZA, developed in the mid-1960s, is a classic example. It mimicked a psychotherapist by recognizing keywords and rephrasing user inputs into questions. While impressive for its time, such systems were rigid, struggled with ambiguity, and were incredibly labor-intensive to build and scale. They lacked true understanding or the ability to generalize beyond their predefined rules.
The paradigm shifted significantly with the advent of machine learning and, more profoundly, deep learning. Neural networks, inspired by the structure of the human brain, began to demonstrate superior capabilities in pattern recognition and data processing. Recurrent Neural Networks (RNNs) and their more advanced variants, Long Short-Term Memory (LSTM) networks, became the workhorses for sequential data like language. These models could process words in context, remembering information from previous parts of a sentence, which was a crucial step towards more coherent and contextually aware text generation. However, RNNs and LSTMs still faced challenges with long-range dependencies, meaning they struggled to connect information across very long sentences or paragraphs, and they were notoriously slow to train on large datasets.
The Transformer Architecture: A Game Changer
The true breakthrough that paved the way for ChatGPT and similar large language models arrived in 2017 with the introduction of the Transformer architecture by Google researchers. The Transformer revolutionized NLP by abandoning the sequential processing of RNNs in favor of a mechanism called “self-attention.” This mechanism allows the model to weigh the importance of different words in an input sentence relative to each other, irrespective of their position. Crucially, it enabled parallel processing of data, significantly speeding up training times and allowing models to handle vastly larger datasets and longer contexts than ever before before.
The Transformer’s ability to efficiently capture complex relationships within text, combined with its scalability, made it the ideal foundation for building truly massive language models. OpenAI quickly adopted and refined this architecture, leading to the development of the Generative Pre-trained Transformer (GPT) series. GPT-1, GPT-2, and GPT-3 progressively demonstrated increasing scale and capability, with GPT-3, released in 2020, becoming one of the largest neural networks ever trained at the time, boasting 175 billion parameters. ChatGPT, though not a direct successor in the parameter count race, is built upon a similar foundational model, specifically tailored and fine-tuned for conversational interaction, bringing the power of these massive models directly to the user in an accessible chat interface. This architectural innovation is the cornerstone of its unprecedented fluency and versatility.
Unpacking the Power of ChatGPT: How It Works Under the Hood
To appreciate ChatGPT’s capabilities, it’s essential to understand the intricate process by which it learns, generates, and refines its linguistic abilities. This involves a multi-stage training regimen leveraging vast datasets and human feedback.
Large Language Models (LLMs) and Pre-training
At its core, ChatGPT is an instance of a Large Language Model (LLM). These models are “large” not just in the number of parameters they possess but also in the sheer volume of data they are trained on. The initial phase of training, known as “pre-training,” involves feeding the model an enormous corpus of text data drawn from the internet. This includes books, articles, websites, conversations, and more. The objective of pre-training is for the model to learn the statistical relationships between words and phrases, essentially internalizing the grammar, syntax, semantics, and various styles of human language.
During pre-training, the model is given tasks such as predicting the next word in a sentence, filling in missing words, or even predicting entire masked segments of text. By repeatedly performing these tasks across trillions of words, the model develops a highly sophisticated internal representation of language. It learns what words typically follow others, how concepts are related, and even common facts and patterns expressed in text. This unsupervised learning process is akin to a child absorbing language by listening and reading extensively without explicit instruction on grammar rules. The result is a model that can generate coherent, contextually relevant, and grammatically correct text, even though it doesn’t “understand” in the human sense but rather predicts the most probable next sequence of words based on its learned patterns.
Fine-tuning for Conversational Excellence
While pre-training instills a vast general knowledge of language, a raw LLM isn’t inherently optimized for engaging in human-like conversations. This is where the crucial “fine-tuning” phase comes in. For ChatGPT, this involved further training the pre-trained model specifically on conversational data. This dataset typically consists of dialogues, questions and answers, and instructions paired with appropriate responses. The goal is to teach the model to follow instructions, answer questions directly, admit when it doesn’t know an answer, and generally behave like a helpful conversational agent.
This supervised fine-tuning helps the model adapt its general language understanding to the specific nuances of interaction: maintaining context over several turns, asking clarifying questions, and generating responses that are not just grammatically correct but also relevant and aligned with user intent. It’s a critical step that transforms a powerful text predictor into a capable conversationalist, moving beyond simply generating plausible text to generating useful and interactive text.
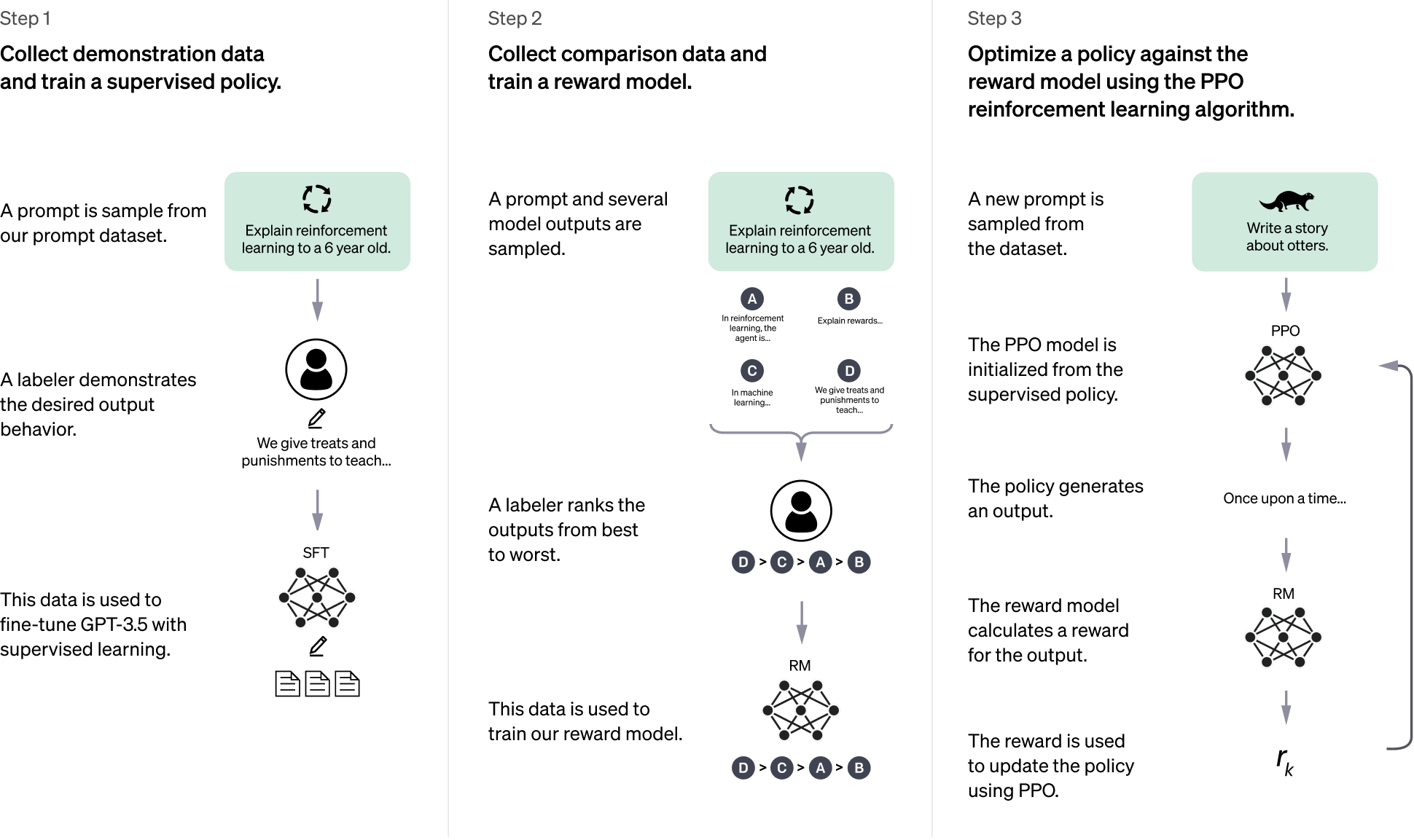
Reinforcement Learning from Human Feedback (RLHF)
Perhaps the most innovative aspect of ChatGPT’s development pipeline is the integration of Reinforcement Learning from Human Feedback (RLHF). This technique is pivotal in aligning the model’s outputs with human preferences and ethical guidelines, making its responses more helpful, harmless, and honest. The process generally involves:
- Human Demonstrations: Human labelers act as both users and AI assistants, crafting desired responses to a wide range of prompts. This data is used to further fine-tune the model, teaching it to respond in preferred ways.
- Comparison and Ranking: The model generates multiple responses to a given prompt. Human labelers then rank these responses from best to worst based on criteria like helpfulness, accuracy, coherence, and safety.
- Reward Model Training: This ranked data is used to train a separate “reward model.” This reward model learns to predict which responses humans would prefer.
- Reinforcement Learning: The primary language model is then fine-tuned using reinforcement learning, where it tries to maximize the “reward” predicted by the reward model. This continuous loop allows the model to learn directly from human values and improve its conversational abilities in subtle, yet powerful, ways.
RLHF is what gives ChatGPT its distinct personality and conversational style, enabling it to navigate complex queries, refuse inappropriate requests, and generate outputs that feel remarkably human-centric. It is a key innovation in ensuring that powerful AI models are not just intelligent, but also aligned with human expectations and societal norms.
Revolutionizing Interactions: Key Applications and Capabilities
ChatGPT’s versatility has opened doors to a myriad of applications across various domains, fundamentally altering how individuals and organizations approach tasks that involve language generation, comprehension, and interaction.
Content Generation and Creative Writing
![]()
One of the most immediate and impactful applications of ChatGPT is in content creation. From drafting marketing copy, social media posts, and blog outlines to generating creative stories, poems, and scripts, the model can produce high-quality text on demand. Writers can use it for brainstorming ideas, overcoming writer’s block, or generating multiple drafts to refine their work. Marketers leverage it to quickly produce engaging content tailored for different platforms and audiences. Its ability to mimic various styles and tones makes it an invaluable tool for enhancing creative output and accelerating content pipelines.
Information Retrieval and Summarization
While not a search engine in the traditional sense, ChatGPT excels at synthesizing information. Users can ask complex questions, and the model can often provide concise, understandable answers by drawing upon the vast knowledge embedded in its training data. It can summarize lengthy documents, articles, or research papers into key bullet points or a brief overview, saving significant time for researchers, students, and professionals alike. This capability transforms how users access and digest information, moving beyond keyword searches to direct, conversational inquiry.
Coding Assistance and Debugging
For developers, ChatGPT has become an unexpected coding companion. It can generate code snippets in various programming languages, explain complex coding concepts, help debug existing code by identifying errors or suggesting improvements, and even translate code from one language to another. This functionality not only streamlines the development process but also serves as an invaluable educational tool for learning new languages or understanding intricate algorithms, democratizing access to coding knowledge.
Education and Learning Support
In the realm of education, ChatGPT presents a powerful new form of learning support. Students can use it to get explanations for difficult concepts, generate practice questions, receive feedback on their writing, or explore subjects from different perspectives. Educators can utilize it to create lesson plans, generate diverse examples, or even design interactive learning scenarios. While its use requires careful guidance to prevent misuse, its potential to personalize learning and provide instant, tailored assistance is immense, offering a complementary resource to traditional teaching methods.
Navigating the Landscape: Challenges, Limitations, and Ethical Considerations
Despite its impressive capabilities, ChatGPT is not without its limitations and raises significant ethical concerns that demand careful consideration as this technology matures and integrates further into society.
Hallucinations and Factual Accuracy
One of the most critical limitations of ChatGPT and similar LLMs is their propensity to “hallucinate” – generating plausible-sounding but factually incorrect information. Because the model predicts the most probable sequence of words rather than truly “knowing” facts, it can sometimes confidently present false data or fabricate sources. This can be particularly problematic in fields requiring high accuracy, such as medical advice, legal interpretations, or academic research. Users must always verify information obtained from ChatGPT, highlighting that it is a tool for generation, not a definitive source of truth.
Bias and Fairness in AI Outputs
ChatGPT’s training data, drawn from the internet, reflects the biases and stereotypes present in human language and society. Consequently, the model can inadvertently perpetuate or amplify these biases in its responses. This can manifest as unfair or discriminatory outputs related to gender, race, ethnicity, religion, or other protected characteristics. Addressing bias requires ongoing research into data curation, model architecture, and ethical fine-tuning, but it remains a persistent challenge in ensuring AI fairness and equitable outcomes for all users.
Data Privacy and Security Implications
The use of ChatGPT, particularly in enterprise settings, raises concerns about data privacy and security. Users input sensitive information into the model, and while OpenAI has policies in place regarding data usage, the risk of inadvertently exposing proprietary information or personal data exists. Organizations must establish clear guidelines for employee use and be cautious about what information is shared with the model. Furthermore, the potential for malicious actors to exploit LLMs for phishing, misinformation campaigns, or other harmful activities poses a significant security challenge.
The Future of Work and Societal Impact
The rise of highly capable AI models like ChatGPT sparks widespread debate about their impact on the future of work. While AI can automate mundane tasks and augment human capabilities, concerns about job displacement in creative, administrative, and even technical roles are valid. Understanding how to integrate AI into workflows to enhance human productivity rather than replace it entirely will be crucial. Beyond employment, the proliferation of AI-generated content raises questions about intellectual property, the nature of creativity, and the very definition of authenticity in an increasingly AI-driven digital world.
The Road Ahead: ChatGPT’s Influence on Tech & Innovation
ChatGPT is more than a fleeting trend; it is a foundational technology that is already profoundly influencing the trajectory of tech and innovation, setting the stage for future advancements and integrated intelligence.
Advancements in AI Personalization
The capabilities demonstrated by ChatGPT are pushing the boundaries of AI personalization. Future iterations will likely offer even more tailored experiences, understanding individual user preferences, learning from past interactions, and adapting its communication style and knowledge base to specific needs. This could lead to hyper-personalized educational tutors, highly intuitive personal assistants, and adaptive interfaces that feel genuinely responsive to each user, fundamentally changing the nature of human-computer interaction.
Integration Across Industries
ChatGPT’s core technology, large language models, is rapidly being integrated into a diverse array of industries. In healthcare, it could assist doctors with diagnostics or personalize patient education. In finance, it might power intelligent advisors or fraud detection systems. Customer service is already being transformed by AI chatbots that can handle complex queries with human-like fluency. This cross-industry integration points towards a future where intelligent language processing becomes an invisible yet indispensable layer in virtually every digital product and service, augmenting human capabilities across the board.

Paving the Way for AGI?
While ChatGPT and its peers are incredibly powerful, they are still considered “narrow AI” – highly proficient at specific tasks (like language generation) but lacking true general intelligence or consciousness. However, the rapid advancements in LLMs, coupled with other breakthroughs in AI, fuel discussions about the long-term goal of Artificial General Intelligence (AGI). While AGI remains a distant and complex challenge, the development of models that can understand, reason, and learn across a broad spectrum of tasks, much like humans do, is a compelling vision. ChatGPT serves as a critical stepping stone, providing insights into scalable learning, emergent capabilities, and the potential for AI to bridge the gap between specialized tools and truly versatile intelligence, driving significant research and investment into the next generation of transformative AI.
In conclusion, ChatGPT stands as a testament to the relentless pace of technological innovation. From its sophisticated Transformer architecture and rigorous training methodologies to its widespread applications and the complex ethical dilemmas it presents, it encapsulates the promise and challenges of modern AI. As we continue to explore and expand its capabilities, ChatGPT will undoubtedly remain a pivotal force, shaping the future of human-computer interaction, driving innovation across industries, and prompting humanity to reconsider its relationship with intelligence itself.