In the rapidly evolving landscape of big data and analytics, organizations are constantly seeking robust and scalable solutions to manage, process, and derive insights from ever-increasing volumes of information. Azure Data Lake emerges as a cornerstone of Microsoft’s cloud-based data analytics platform, designed to address these challenges head-on. It’s not merely a storage repository; it’s a comprehensive ecosystem that enables the collection, transformation, and analysis of vast datasets, paving the way for advanced business intelligence and data-driven innovation.
At its core, Azure Data Lake is a highly scalable and secure data lake analytics solution in the Microsoft Azure cloud. It provides a massively scalable, unified data store that supports various data processing workloads. Think of it as a central repository for all your raw data, regardless of its source or format, from which you can then apply powerful analytical tools. This flexibility and scalability are crucial in today’s data-intensive world, where data volumes are exploding, and the need for rapid, insightful analysis is paramount.
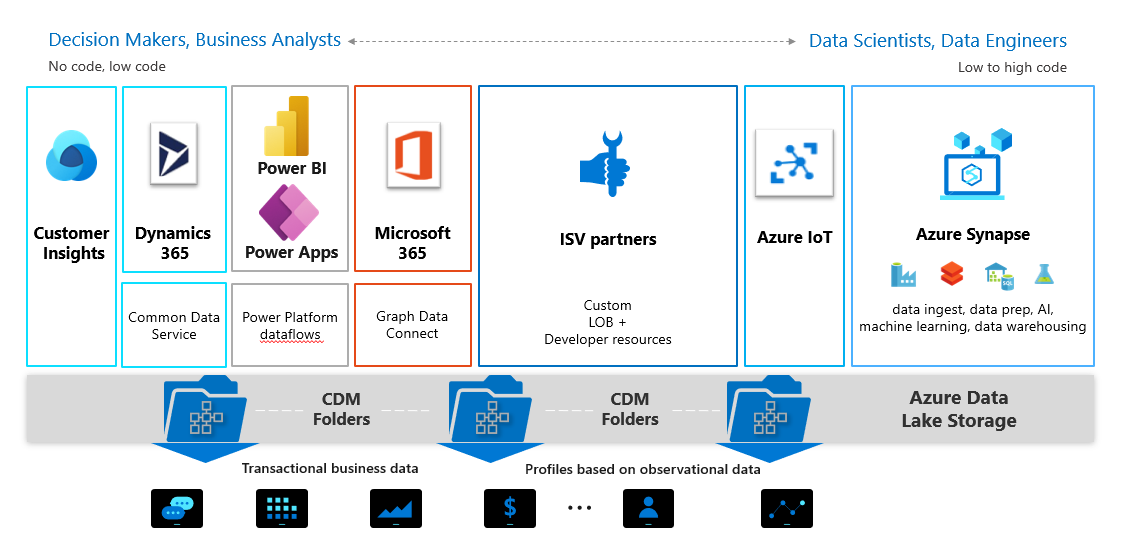
The Foundation: Azure Data Lake Storage Gen2
While “Azure Data Lake” often refers to the broader ecosystem, the foundational component is Azure Data Lake Storage Gen2 (ADLS Gen2). This is a set of capabilities built on Azure Blob Storage, specifically designed for big data analytics. It combines the scalability and cost-effectiveness of object storage with the performance, security, and manageability of a file system. This duality is key to its effectiveness.
Object Storage Meets File System Semantics
Traditionally, big data workloads required specialized file systems like Hadoop Distributed File System (HDFS) running on expensive on-premises hardware. ADLS Gen2 offers the best of both worlds. It leverages the robust, highly available, and cost-effective object storage of Azure Blob Storage, but with the addition of a hierarchical namespace. This hierarchical namespace allows for the organization of data into directories and subdirectories, mimicking the familiar file system structure that many analytical tools and applications are accustomed to. This makes it significantly easier to manage and access large datasets compared to flat object storage.
Optimized for Analytics Workloads
Beyond the hierarchical namespace, ADLS Gen2 is optimized for analytical workloads. It provides high throughput and low latency access to data, which is critical for demanding big data processing engines like Apache Spark, Hadoop, and Azure Databricks. Furthermore, its design facilitates efficient data querying and processing, reducing the time it takes to extract valuable insights. This performance optimization is not just about speed; it’s about enabling real-time or near-real-time analytics that can significantly impact business decisions.
Scalability and Cost-Effectiveness
One of the most compelling advantages of ADLS Gen2 is its unparalleled scalability. It can handle petabytes of data without compromising performance. This elasticity is a hallmark of cloud computing and is essential for organizations experiencing exponential data growth. Moreover, its foundation on Azure Blob Storage makes it a highly cost-effective solution compared to traditional on-premises storage for big data. Organizations can scale their storage up or down as needed, paying only for what they use, which significantly reduces capital expenditure and operational overhead.
The Ecosystem: Beyond Storage
While ADLS Gen2 provides the robust storage foundation, the true power of Azure Data Lake lies in its integration with a rich ecosystem of Azure services designed for data processing, transformation, and analysis. This interconnectedness transforms raw data into actionable intelligence.
Data Ingestion and Transformation
Before data can be analyzed, it needs to be ingested and often transformed into a usable format. Azure Data Lake seamlessly integrates with a variety of data ingestion services.
Azure Data Factory
Azure Data Factory (ADF) is Microsoft’s cloud-based ETL (Extract, Transform, Load) and data integration service. ADF allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. It can ingest data from a vast array of on-premises and cloud sources, transform it using various compute services, and load it into ADLS Gen2. This makes it the go-to service for building complex data pipelines that feed into your data lake.
Azure Databricks
Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform. It provides a unified platform for data engineering, data science, and machine learning. When combined with ADLS Gen2, Databricks enables powerful interactive data exploration, batch processing, and real-time analytics. Its integrated notebooks and collaborative features accelerate the development and deployment of data solutions.

Data Analysis and Visualization
Once data is stored and transformed in Azure Data Lake, a suite of powerful tools can be employed to uncover insights and present them in an understandable format.
Azure Synapse Analytics
Azure Synapse Analytics is an unbounded analytics service that brings together data warehousing and Big Data analytics. It provides a unified experience for ingesting, preparing, managing, and serving data for immediate BI and machine learning needs. Synapse Analytics can directly query data stored in ADLS Gen2, allowing for sophisticated SQL-based analysis and data warehousing capabilities on massive datasets without the need for complex data movement.
Power BI
For data visualization and business intelligence, Power BI is the leading solution. It can connect directly to ADLS Gen2 and the data processed through services like Azure Synapse Analytics or Azure Databricks. This allows users to create interactive dashboards and reports that provide a clear and concise view of their data, enabling informed decision-making across the organization.
Key Benefits and Use Cases
The adoption of Azure Data Lake offers significant advantages for businesses looking to leverage their data more effectively. Its inherent scalability, cost-efficiency, and integration capabilities make it suitable for a wide range of demanding scenarios.
Scalability and Performance for Big Data
The primary benefit of Azure Data Lake is its ability to handle massive datasets. Whether dealing with IoT data streams, clickstream data from websites, social media feeds, or transactional logs, ADLS Gen2 can scale to accommodate virtually any volume. The optimized performance ensures that analytical queries and processing tasks complete in a timely manner, even with petabytes of data. This scalability is not just about storage capacity; it’s about ensuring that analytical workloads remain performant as data volumes grow.
Unified Data Management
By consolidating data from disparate sources into a central repository like Azure Data Lake, organizations can achieve a more unified view of their information. This breaks down data silos and eliminates the need to manage multiple, often redundant, data stores. This centralized approach simplifies data governance, security, and access control, leading to greater efficiency and reduced complexity.
Enabling Advanced Analytics and AI
Azure Data Lake is a crucial enabler for advanced analytics, machine learning, and artificial intelligence initiatives. The ability to store and process large, diverse datasets is fundamental for training machine learning models, developing predictive analytics, and implementing AI-driven solutions. Services like Azure Machine Learning can directly access data in ADLS Gen2, accelerating the development and deployment of intelligent applications.
Cost Optimization
As mentioned earlier, the cloud-native nature of Azure Data Lake, built on Azure Blob Storage, offers significant cost advantages. Organizations can avoid the substantial upfront capital investments in hardware and infrastructure associated with on-premises big data solutions. The pay-as-you-go model allows for flexible scaling, ensuring that costs remain aligned with actual usage.
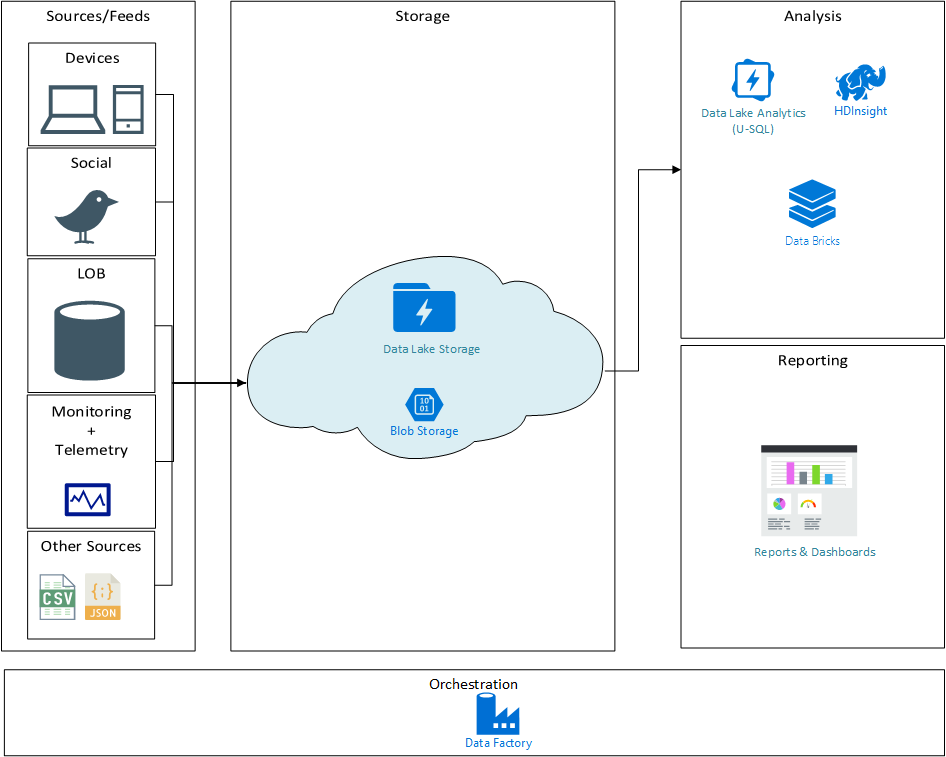
Use Cases:
- Customer 360: Consolidating customer data from various touchpoints (CRM, website, social media, support tickets) to gain a comprehensive understanding of customer behavior and preferences.
- IoT Analytics: Ingesting and analyzing massive streams of data from IoT devices to monitor performance, predict failures, and optimize operations.
- Fraud Detection: Processing large volumes of transactional data to identify anomalies and patterns indicative of fraudulent activity.
- Log Analytics: Storing and analyzing application and server logs to troubleshoot issues, monitor system health, and identify security threats.
- Scientific Research: Storing and analyzing vast datasets generated from scientific experiments and simulations for discovery and insight.
In conclusion, Azure Data Lake, with Azure Data Lake Storage Gen2 at its core and its seamless integration with a powerful ecosystem of analytical services, represents a significant advancement in big data management and analytics. It empowers organizations to not only store and process vast amounts of data but also to unlock its true potential, driving innovation, informing strategic decisions, and ultimately achieving a competitive edge in the data-driven economy.