The concept of an inode might seem esoteric to those who primarily interact with their computing devices through user-friendly graphical interfaces. However, understanding inodes is fundamental to grasping how file systems function at a deeper level, particularly within Unix-like operating systems. For anyone involved in advanced system administration, software development, or even curious about the inner workings of their operating system, a solid grasp of inodes is invaluable. This article will demystify the inode, exploring its purpose, structure, and critical role in managing data on storage devices.
The Foundation of File Management: Understanding Inodes
At its core, a file system is responsible for organizing and managing data stored on a disk. It needs a way to keep track of every file and directory, where its data resides, and what permissions are associated with it. This is where inodes come into play. An inode, short for “index node,” is a data structure on a Unix-style file system that stores all the information about a file except its name and the actual data content. Think of it as a metadata container for each file and directory.
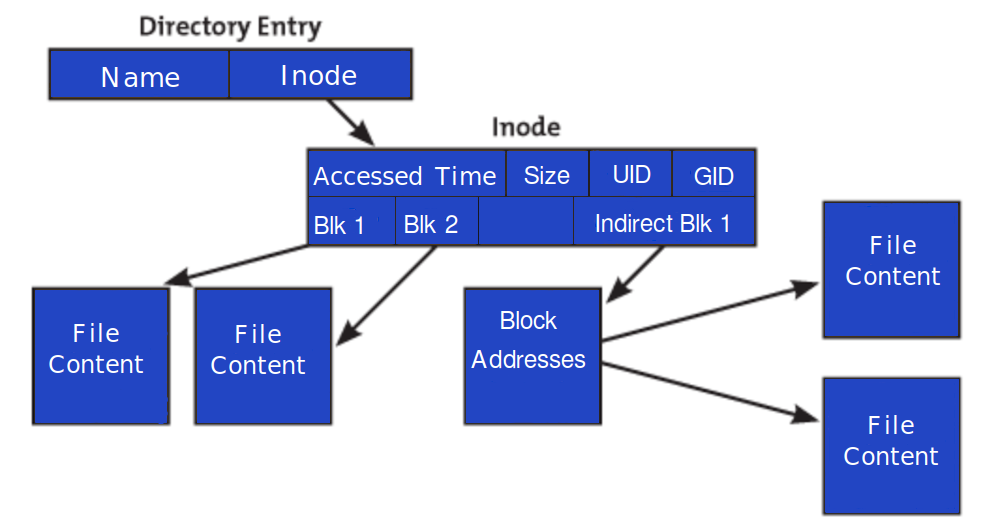
What Information Does an Inode Hold?
Each inode is assigned a unique number within its file system, serving as its primary identifier. This inode number is crucial for the operating system to locate and access the file. Within the inode structure itself, a wealth of metadata is stored, enabling the file system to manage the file efficiently. This metadata includes:
- File Type: Whether the entry is a regular file, a directory, a symbolic link, a block device, a character device, a named pipe (FIFO), or a socket. This is essential for the operating system to know how to interact with the entry.
- Permissions: The access permissions for the owner, the group, and others. This includes read (r), write (w), and execute (x) permissions, as well as special permissions like the set-user-ID (SUID), set-group-ID (SGID), and the sticky bit.
- Owner ID: The user ID of the file’s owner.
- Group ID: The group ID of the file’s group.
- Size: The size of the file in bytes.
- Timestamps:
- Access Time (atime): The last time the file was accessed.
- Modification Time (mtime): The last time the file’s content was modified.
- Change Time (ctime): The last time the file’s inode was changed (e.g., permissions modified, owner changed).
- Link Count: The number of hard links pointing to this inode. When this count drops to zero, the inode and its associated data blocks are freed and become available for reuse.
- Pointers to Data Blocks: This is perhaps the most critical part of the inode. It contains pointers (addresses) to the actual blocks on the disk where the file’s data is stored.
The Inode Table: A Central Repository
File systems typically maintain an “inode table” – an array of inodes. Each entry in this table corresponds to a specific inode number. When a file is created, a new inode is allocated in this table, and its entry is populated with the relevant metadata. The directory entry, which does store the file’s name, then contains a pointer to this inode number.
When you request to access a file (e.g., cat myfile.txt), the operating system performs the following steps:
- Locate the Directory Entry: It finds the directory entry for
myfile.txt. This entry contains the filename and the inode number. - Access the Inode: Using the inode number, the operating system looks up the corresponding inode in the inode table.
- Retrieve Metadata: It reads the metadata from the inode, including permissions, ownership, and crucially, the pointers to the data blocks.
- Access Data Blocks: Using the pointers, the operating system then accesses the disk blocks that contain the actual content of
myfile.txtand reads it for you.
This separation of file name from file content and metadata is a fundamental design choice in Unix-like systems.
The Structure and Mechanics of Inodes
The exact structure of an inode can vary slightly between different file system implementations (e.g., ext4, XFS, Btrfs), but the core principles remain consistent. Generally, an inode is a fixed-size structure. The pointers to data blocks are typically managed using a multi-level indexing scheme to efficiently handle files of various sizes.
Direct, Indirect, Double Indirect, and Triple Indirect Pointers
To accommodate files of all sizes, from a few bytes to many gigabytes, inodes use a clever system of pointers. A typical inode will contain:
- Direct Pointers: A fixed number of pointers that directly point to data blocks on the disk. For smaller files, these pointers are sufficient to locate all the file’s data.
- Single Indirect Pointer: If the file is larger than what the direct pointers can cover, a single indirect pointer points to a block that contains a list of pointers to data blocks.
- Double Indirect Pointer: For even larger files, a double indirect pointer points to a block that contains pointers to blocks that, in turn, contain pointers to data blocks.
- Triple Indirect Pointer: For extremely large files, a triple indirect pointer points to a block that contains pointers to blocks that point to blocks that contain pointers to data blocks.
This hierarchical approach allows the file system to efficiently manage data blocks without requiring an excessively large inode structure for every file. The number of direct and indirect pointers, and the size of a data block, are determined by the file system’s design.
Hard Links and Their Relationship to Inodes
One of the powerful features enabled by the inode system is the concept of hard links. A hard link is essentially another directory entry that points to the same inode number as an existing file. When you create a hard link, you are not creating a copy of the file; you are creating an alias.
- Creating a Hard Link: When you issue a command like
ln source_file hard_link_name, a new directory entry (hard_link_name) is created, and it points to the same inode number assource_file. - The Link Count: The crucial effect of creating a hard link is that the link count within the inode is incremented by one.
- Deleting a Hard Link: When you delete a hard link (e.g.,
rm hard_link_name), the directory entry is removed, and the link count in the inode is decremented by one. - Data Deletion: The actual data blocks associated with the inode are only deallocated (freed) and become available for reuse when the link count in the inode reaches zero. This means a file’s data persists as long as at least one hard link to its inode exists.
This mechanism ensures data integrity. Even if you delete a file’s primary name, as long as other hard links exist, the data remains accessible. This is fundamentally different from symbolic links, which are essentially just pointers to a file’s name, not its inode.
Symbolic Links (Soft Links) vs. Hard Links

It’s important to distinguish hard links from symbolic links (or soft links).
- Hard Links: Point directly to an inode. They must reside on the same file system as the target file and cannot link to directories (to prevent circular references and complications). All hard links to a file are indistinguishable from the original file from the perspective of accessing data and metadata.
- Symbolic Links: Are special files that contain the path to another file or directory. They are essentially pointers to a filename. They can span across different file systems and can link to directories. When you access a symbolic link, the operating system first reads the path stored within the symbolic link and then follows that path to the target file or directory. Deleting a symbolic link does not affect the target file’s inode or data.
The inode concept is central to the operation of hard links, providing a robust mechanism for referencing and managing data.
Inodes in Action: Practical Implications and Troubleshooting
Understanding inodes provides valuable insights into system performance and can be crucial for troubleshooting various file system issues.
Disk Space Usage and Inode Exhaustion
While inodes themselves consume a small amount of disk space, the primary concern is often the number of inodes available, not their size. On some file systems, particularly those designed for large numbers of small files (like /tmp or mail spool directories), the number of available inodes can become a limiting factor.
If a file system runs out of free inodes, you will be unable to create new files or directories, even if there is ample free disk space available in terms of bytes. This is because creating a new file requires allocating a new inode.
Symptoms of Inode Exhaustion:
- “No space left on device” errors when trying to create new files or directories, despite
df -hshowing free disk space. - Applications failing to write new files or temporary data.
Troubleshooting Inode Exhaustion:
- Check Inode Usage: Use the
df -icommand (where ‘i’ stands for inodes) to view inode usage for each mounted file system. This will show you the total number of inodes, how many are used, and how many are free. - Identify Large Numbers of Small Files: If
df -iindicates high inode usage, the next step is to find where these files are located. Tools likefindcan be extremely useful. For example, to find directories with a high number of files:
bash
find /path/to/mountpoint -xdev -printf '%hn' | sort | uniq -c | sort -nr | head -20
This command will list the top 20 directories with the most files within the specified mountpoint. - Clean Up Unnecessary Files: Once identified, you can begin deleting temporary files, old logs, cache data, or any other unwanted files that are consuming inodes.
File System Corruption and Inodes
Inodes are a critical component of file system integrity. If an inode becomes corrupted, it can lead to various problems, including:
- Unreadable Files: If the inode’s pointers to data blocks are corrupted, the file may become inaccessible.
- Incorrect File Sizes or Permissions: Corrupted inode metadata can lead to inaccurate information about the file.
- System Instability: In severe cases, corrupted inodes can affect the entire file system’s stability.
File System Check (fsck):
Tools like fsck (file system check) are designed to scan file systems for errors, including inode corruption. Running fsck (often on an unmounted file system or during boot) can help detect and repair such issues.
File System Design and Inode Allocation
The way a file system allocates and manages inodes has a direct impact on its performance and scalability. Modern file systems employ sophisticated algorithms to:
- Efficiently Allocate Inodes: Distribute inode allocation across the disk to avoid bottlenecks.
- Manage Free Inodes: Maintain accurate records of available inodes.
- Handle Large Numbers of Files: Optimize for scenarios with millions or billions of files.
For instance, some file systems use dynamic inode allocation, where inodes are created as needed, rather than pre-allocating a fixed number at format time. This provides flexibility but requires careful management.

Conclusion: The Unsung Hero of File Management
While not directly visible to the average user, the inode is a cornerstone of modern operating systems. It acts as the central index for all file metadata, enabling the efficient storage, retrieval, and management of data. From its role in tracking permissions and timestamps to its intricate system of data block pointers and its crucial function in the concept of hard links, the inode is an indispensable component.
A deeper understanding of inodes empowers system administrators and developers to diagnose performance issues, troubleshoot storage problems, and appreciate the elegant design principles behind Unix-like file systems. The next time you access a file, remember the unsung hero working diligently behind the scenes: the inode.