Deoxyribonucleic acid, or DNA, is often hailed as the blueprint of life, carrying the genetic instructions used in the growth, development, functioning, and reproduction of all known living organisms and many viruses. At the heart of this intricate molecule lies its fundamental building block: the DNA nucleotide. Understanding what a DNA nucleotide is, its composition, and how these units assemble, is crucial to grasping the elegance and complexity of genetic information storage and transfer.
The Fundamental Building Block of Life
A DNA nucleotide is a complex organic molecule that serves as the monomer unit of a DNA polymer. Imagine DNA as a vast, intricate building; each nucleotide is like a single, specialized brick. These bricks are not identical but come in four distinct variations, each crucial for the overall structure and function of the DNA molecule. The specific sequence and arrangement of these nucleotides along the DNA strand encode the vast array of genetic information that defines every living thing.

Without nucleotides, the iconic double helix structure of DNA would not exist, nor would the mechanisms for heredity, protein synthesis, or cellular regulation. They are the essential components that allow for the storage, replication, and expression of genetic data, making them central to all biological processes. Their stability and precise interaction are fundamental to life’s continuity and diversity.
Components of a DNA Nucleotide
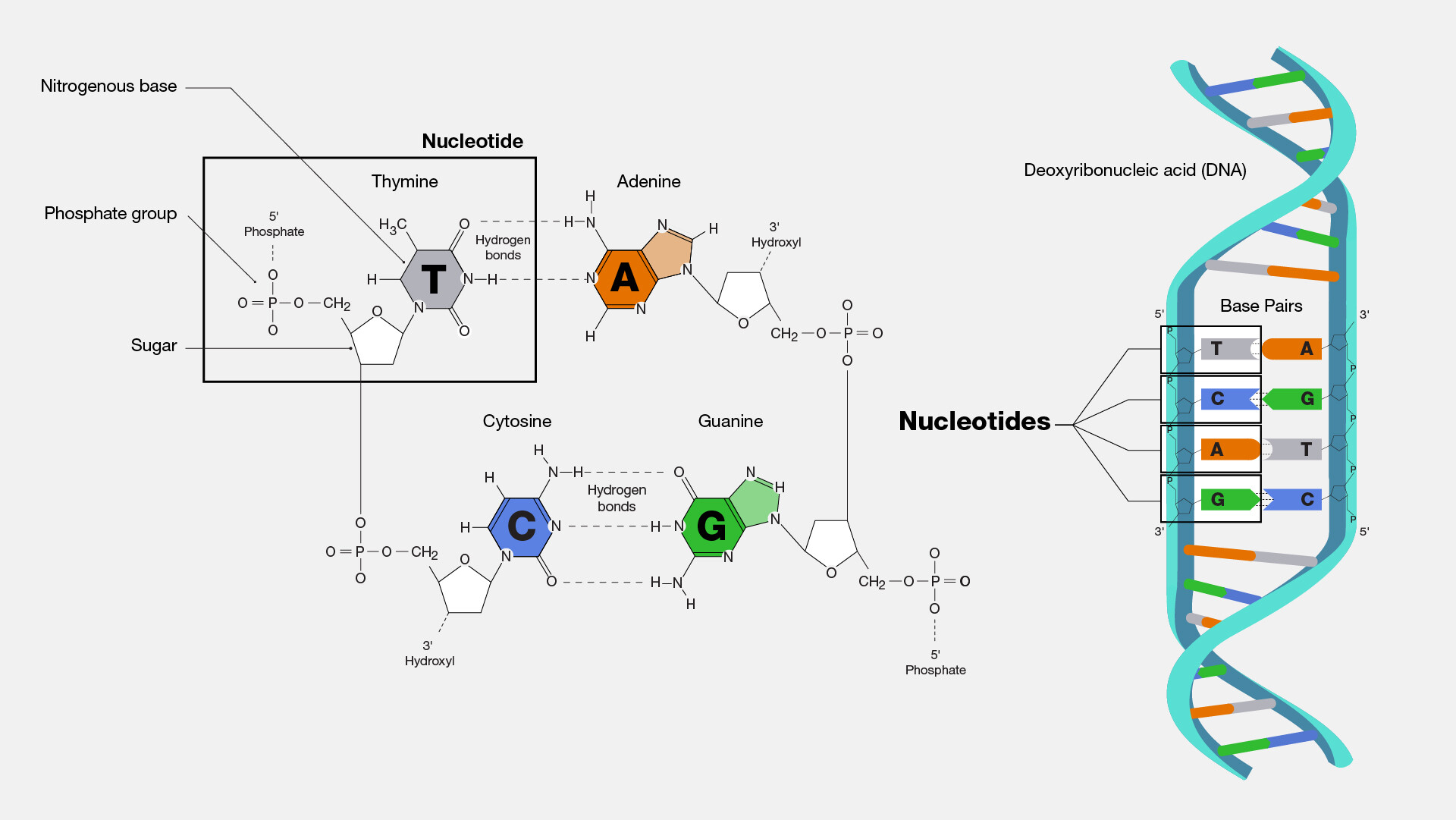
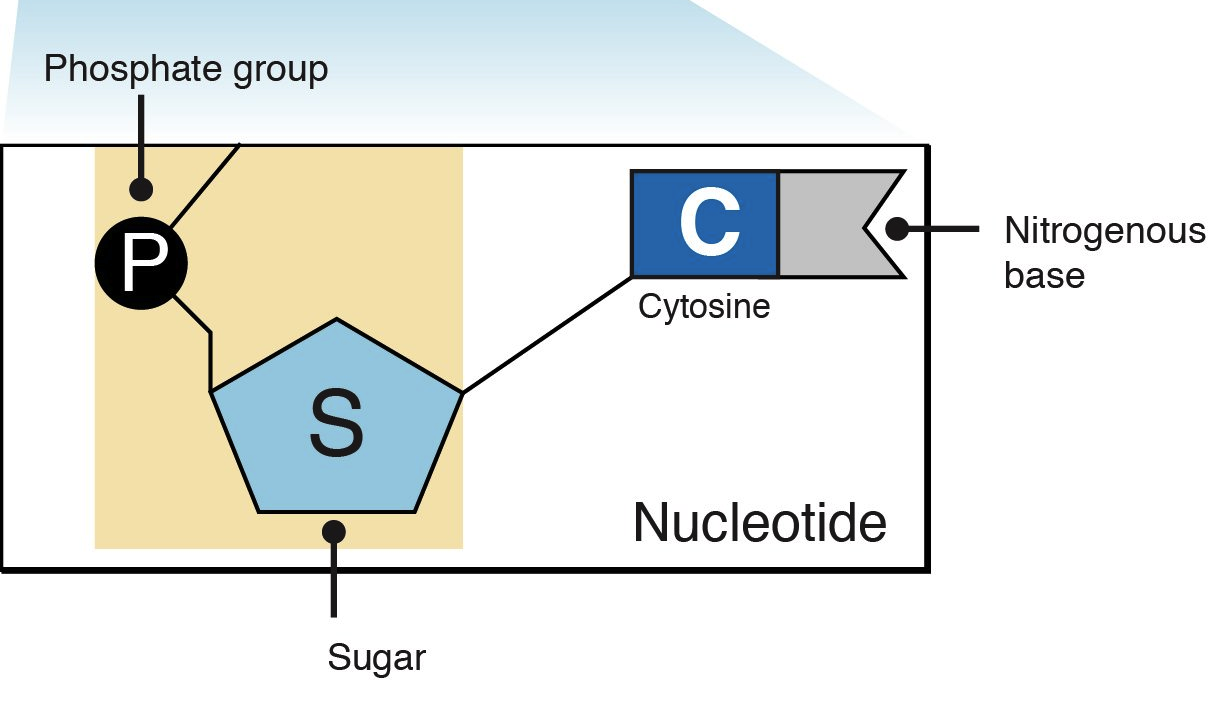
Each DNA nucleotide is a tripartite structure, meaning it is composed of three distinct parts covalently bonded together. These components are remarkably consistent across all life forms, underscoring their universal importance in biology.
The Phosphate Group
The first component is a phosphate group, derived from phosphoric acid. This group consists of a central phosphorus atom bonded to four oxygen atoms. It carries a negative charge, which contributes to the overall negative charge of the DNA molecule. In a DNA strand, the phosphate group of one nucleotide forms a critical link with the sugar of an adjacent nucleotide, creating the backbone of the DNA polymer. This phosphate linkage is vital for maintaining the structural integrity of the long DNA chains. The repetitive nature of the sugar-phosphate backbone provides a robust and stable framework for the delicate genetic code.
Deoxyribose Sugar
The second component is a five-carbon sugar called deoxyribose. The “deoxy-” prefix indicates that this sugar is missing an oxygen atom at the 2′ carbon position, distinguishing it from ribose sugar found in RNA (ribonucleic acid). This subtle difference has significant implications for the stability of DNA compared to RNA. The deoxyribose sugar acts as a central hub, connecting the phosphate group to one side (specifically, its 5′ carbon) and a nitrogenous base to the other (its 1′ carbon). It defines the “directionality” of a DNA strand, which is crucial for reading and synthesizing genetic information.
Nitrogenous Bases
The third and most variable component of a DNA nucleotide is a nitrogenous base. These are organic molecules that contain nitrogen atoms and have basic (alkaline) properties. The nitrogenous bases are the “coding” part of the nucleotide, as their specific sequence determines the genetic information. There are two main categories of nitrogenous bases based on their chemical structure: purines and pyrimidines.
Purines are larger molecules with a double-ring structure. The purine bases found in DNA are Adenine (A) and Guanine (G).
Pyrimidines are smaller molecules with a single-ring structure. The pyrimidine bases found in DNA are Cytosine (C) and Thymine (T). (In RNA, Thymine is replaced by Uracil (U)).
The specific pairing rules between purines and pyrimidines (Adenine with Thymine, Guanine with Cytosine) are fundamental to the double helix structure and accurate replication of DNA.
The Four Nitrogenous Bases
The identity of a DNA nucleotide is primarily defined by its nitrogenous base. These four bases act as the alphabet of the genetic code.
Adenine (A)
Adenine is a purine base, characterized by its double-ring structure. It always pairs with Thymine (T) in a DNA double helix via two hydrogen bonds. This specific pairing is one of the core principles of DNA structure and function, known as Chargaff’s rules. Adenine plays a critical role in various cellular processes beyond DNA structure, including energy transfer as part of ATP (adenosine triphosphate).
Guanine (G)
Guanine is also a purine base, distinct from adenine by its specific arrangement of atoms within its double-ring structure. Guanine forms a strong, triple hydrogen bond with Cytosine (C) in the DNA double helix. This stronger bond contributes to the overall stability of the DNA molecule in regions rich in G-C pairs. Like adenine, guanine is also involved in cellular signaling pathways.
Cytosine (C)
Cytosine is a pyrimidine base, featuring a single-ring structure. It exclusively pairs with Guanine (G) through three hydrogen bonds. The precision of this pairing mechanism is vital for maintaining the integrity and accuracy of the genetic code during DNA replication and repair. Errors in base pairing can lead to mutations, highlighting the importance of this specific interaction.
Thymine (T)
Thymine is the final nitrogenous base found in DNA, a pyrimidine with a single-ring structure. Its unique characteristic in DNA is its exclusive pairing with Adenine (A) via two hydrogen bonds. Thymine is replaced by Uracil (U) in RNA, which is a key distinguishing feature between the two nucleic acids. The stable A-T pairing is crucial for the overall architecture of the double helix and its ability to store genetic information reliably.
Nucleotides in Action: Forming the DNA Strand
The magic of nucleotides truly unfolds when they link together to form long polymer chains, which then intertwine to create the iconic DNA double helix.
Phosphodiester Bonds
Individual nucleotides are joined together by strong covalent bonds called phosphodiester bonds. These bonds form between the phosphate group of one nucleotide and the 3′ hydroxyl group of the deoxyribose sugar of an adjacent nucleotide. This repetitive linkage creates the sugar-phosphate backbone of the DNA strand, which is extremely stable and resistant to breakage. The directionality imparted by these linkages (a 5′ end with a free phosphate and a 3′ end with a free hydroxyl group) is fundamental to how DNA is read and synthesized. Each strand of DNA has a distinct 5′ to 3′ orientation.
Base Pairing and the Double Helix
Two such polynucleotide strands then associate to form the double helix. This association is driven by hydrogen bonds that form between complementary nitrogenous bases on opposite strands. As mentioned, Adenine (A) always pairs with Thymine (T), and Guanine (G) always pairs with Cytosine (C). These specific pairings are known as Chargaff’s rules and are critical for the consistent width and overall structure of the double helix. The hydrogen bonds, while individually weaker than covalent bonds, are collectively strong enough to hold the two strands together, yet weak enough to allow for strand separation during processes like replication and transcription. The helical arrangement not only provides compactness but also protects the genetic information encased within.
The Significance of Nucleotides
The intricate chemistry and arrangement of DNA nucleotides underpin life itself, enabling mechanisms that are essential for survival and evolution.
Genetic Information Storage
The primary role of DNA nucleotides is to store genetic information. The specific sequence of A, T, C, and G along a DNA strand constitutes the genetic code, dictating the sequence of amino acids in proteins, which in turn determine the structure and function of cells and organisms. This sequence holds instructions for everything from eye color to disease susceptibility. The immense diversity of life is a testament to the vast number of unique sequences that can be generated from just these four building blocks.
Replication and Repair
Nucleotides are the raw materials for DNA replication, the process by which a cell makes an exact copy of its DNA before cell division. During replication, the DNA double helix unwinds, and new complementary nucleotides are brought in and assembled onto each separated strand, ensuring that each new cell receives a complete and accurate set of genetic instructions. Similarly, in DNA repair mechanisms, damaged or incorrect nucleotides can be identified and replaced, maintaining the integrity of the genetic code throughout an organism’s life.
Evolution and Diversity
While replication is remarkably accurate, occasional errors (mutations) in nucleotide sequence can occur. These mutations, while sometimes harmful, are also a fundamental source of genetic variation. Over long periods, accumulated beneficial mutations, driven by natural selection, lead to evolution and the incredible diversity of species on Earth. Thus, the humble DNA nucleotide is not just a static building block but a dynamic component central to the ongoing story of life. The subtle shifts in nucleotide sequences over generations fuel adaptation, innovation, and the continuous unfolding of biological complexity.