Data transformation is a fundamental process in the realm of data science, machine learning, and particularly in the context of extracting meaningful insights from complex datasets. At its core, data transformation refers to the process of converting data from one format or structure into another. This is not merely a cosmetic change; it’s a critical step that prepares raw data for analysis, modeling, and visualization, ensuring accuracy, consistency, and usability. In the rapidly evolving landscape of technology, where vast quantities of data are generated from diverse sources like sensors, imaging systems, and autonomous operations, understanding and mastering data transformation is paramount.
![]()
The necessity for data transformation arises from the inherent messiness and heterogeneity of real-world data. Raw data is often incomplete, inconsistent, contains errors, or is stored in formats that are incompatible with analytical tools. For instance, data collected by various sensors on a drone might be in different units, have missing values, or be in a format that requires significant manipulation before it can be fed into a machine learning algorithm for tasks like object detection or environmental mapping. Data transformation bridges this gap, making the data “fit for purpose.”
The overarching goal of data transformation is to enhance the quality and utility of data. This involves a range of techniques, from simple cleaning and normalization to more complex feature engineering. By applying these transformations, we can uncover hidden patterns, build more robust predictive models, and derive actionable intelligence. In the context of drone technology, for example, transforming aerial imagery into a format suitable for AI-driven analysis can unlock capabilities like precise crop health monitoring, infrastructure inspection, or advanced autonomous navigation.
The Purpose and Importance of Data Transformation
The significance of data transformation cannot be overstated. It acts as a crucial intermediary between raw data acquisition and meaningful insight generation. Without proper transformation, data can be misleading, leading to flawed conclusions and ineffective decisions.
Enhancing Data Quality and Consistency
Raw data is rarely perfect. It can suffer from a variety of issues:
- Incompleteness: Missing values are common in datasets. Transformations can involve imputing these missing values based on statistical methods or domain knowledge.
- Inaccuracy: Data entry errors, sensor malfunctions, or measurement inaccuracies can introduce incorrect values. Cleaning techniques within transformation aim to identify and rectify these errors.
- Inconsistency: Different sources may use varying formats for the same information (e.g., date formats, units of measurement, categorical labels). Transformation standardizes these variations. For example, drone altitude data might be collected in meters by one sensor and feet by another; transformation would ensure both are converted to a common unit.
- Duplication: Redundant data entries can skew analytical results. Deduplication is a common transformation step.
By addressing these quality issues, data transformation ensures that subsequent analysis and modeling are based on reliable and accurate information.
Optimizing Data for Analysis and Modeling
Many analytical algorithms and machine learning models have specific requirements regarding the input data format and characteristics. Data transformation plays a vital role in meeting these requirements:
- Normalization and Standardization: Many algorithms, especially those sensitive to the scale of features (like Support Vector Machines or principal component analysis), perform better when data is normalized or standardized. Normalization scales data to a fixed range (e.g., 0 to 1), while standardization scales data to have a mean of 0 and a standard deviation of 1. This is particularly relevant when combining data from different sensor types on a drone, which might have vastly different scales.
- Feature Engineering: This is a more advanced form of transformation where new features are created from existing ones. This can involve combining variables, creating interaction terms, or extracting specific characteristics from raw data. For instance, from raw GPS coordinates and flight path data, one might engineer features like flight speed, altitude changes over time, or distance from a designated point. In aerial imaging, transforming pixel values into features that represent texture, color histograms, or spectral indices can significantly improve object recognition accuracy.
- Dimensionality Reduction: Datasets can sometimes have a very large number of features (dimensions), which can lead to the “curse of dimensionality” and computational inefficiency. Transformations like Principal Component Analysis (PCA) or t-SNE can reduce the number of dimensions while preserving essential information, making models faster and more interpretable.
Enabling Data Integration
In many scenarios, data originates from multiple disparate sources. These sources may use different schemas, data types, or storage formats. Data transformation is essential for integrating these datasets into a unified view. This is crucial for applications like creating comprehensive environmental surveys from various drone sensor outputs, or combining flight logs with sensor readings for detailed performance analysis.
Common Data Transformation Techniques
A variety of techniques are employed in data transformation, each serving a specific purpose. The choice of technique depends heavily on the nature of the data and the objectives of the analysis.
Cleaning and Preprocessing
This initial phase focuses on addressing data quality issues.
- Handling Missing Values:
- Imputation: Replacing missing values with estimated values. Common methods include mean, median, mode imputation, or more sophisticated techniques like regression imputation or k-nearest neighbors imputation.
- Deletion: Removing rows or columns with a significant number of missing values. This is a simpler but potentially data-losing approach.
- Outlier Detection and Treatment: Identifying and addressing data points that deviate significantly from the norm. Outliers can be removed, transformed (e.g., Winsorization), or analyzed separately if they represent important anomalies.
- Noise Reduction: Smoothing out random variations in data that can obscure underlying patterns. Techniques like moving averages or low-pass filters can be used.

Structuring and Formatting
This involves changing the organization and presentation of data.
- Aggregation: Summarizing data by grouping it based on certain criteria. For example, aggregating flight data by day to get total flight time or distance flown.
- Discretization (Binning): Converting continuous numerical data into discrete categories or bins. This can be useful for simplifying data or for use in algorithms that require categorical inputs. For instance, converting continuous altitude readings into discrete “low,” “medium,” and “high” altitude categories.
- Data Type Conversion: Changing the data type of a variable (e.g., converting a string representing a date into a datetime object, or converting numerical strings into actual numbers).
- Reshaping Data: Transforming data from a wide format (many columns) to a long format (fewer columns, more rows) or vice-versa. This is often necessary for compatibility with certain analytical tools.
Normalization and Scaling
These techniques are crucial for preparing numerical data for algorithms that are sensitive to feature magnitudes.
- Min-Max Scaling (Normalization): Rescales features to a fixed range, usually [0, 1]. The formula is: $X{scaled} = frac{X – X{min}}{X{max} – X{min}}$. This is useful when the exact range of data is known or when dealing with algorithms like neural networks.
- Standardization (Z-score Scaling): Rescales features to have a mean of 0 and a standard deviation of 1. The formula is: $X_{scaled} = frac{X – mu}{sigma}$, where $mu$ is the mean and $sigma$ is the standard deviation. This is robust to outliers and is commonly used in algorithms like PCA and linear regression.
- Robust Scaling: Uses statistics that are robust to outliers, such as the median and interquartile range (IQR). This can be beneficial when dealing with datasets containing significant outliers.
Feature Engineering and Transformation
This category focuses on creating new, more informative features from existing data.
- Polynomial Features: Creating new features by raising existing features to a power (e.g., $x^2, x^3$) or by creating interaction terms between features (e.g., $x1 times x2$). This can help capture non-linear relationships.
- Logarithmic Transformation: Applying a logarithmic function (e.g., $log(x)$ or $log(1+x)$) to data. This can help reduce the skewness of a distribution, making it more amenable to linear models, and can stabilize variance. This is often useful for highly skewed sensor readings.
- Box-Cox Transformation: A family of power transformations that includes the logarithmic transformation as a special case. It is used to make data more normally distributed.
- Encoding Categorical Variables: Converting non-numerical categories into a numerical format that machine learning algorithms can process.
- One-Hot Encoding: Creates a new binary column for each unique category, with a 1 indicating the presence of that category and 0 otherwise.
- Label Encoding: Assigns a unique integer to each category. This should be used cautiously as it can imply an ordinal relationship where none exists.
- Target Encoding: Encodes categories based on the mean of the target variable for that category.
Practical Applications of Data Transformation in Drone Operations
The power of data transformation is vividly illustrated in various drone-related applications, where raw sensor data often needs extensive preparation to yield actionable insights.
Aerial Imagery Analysis
Drones equipped with high-resolution cameras, thermal sensors, or multispectral sensors generate vast amounts of imagery data. Before this data can be used for tasks like precision agriculture, infrastructure inspection, or environmental monitoring, it undergoes rigorous transformation.
- Georeferencing and Orthorectification: Raw aerial images are transformed to align with real-world geographic coordinates. Orthorectification corrects for geometric distortions caused by camera tilt and terrain relief, producing an image that is geometrically uniform and can be accurately measured.
- Image Enhancement: Techniques like contrast adjustment, color correction, and noise reduction are applied to improve the visual quality of images and highlight specific features of interest.
- Feature Extraction from Spectral Data: For multispectral or hyperspectral imagery, transformations are used to derive indices like the Normalized Difference Vegetation Index (NDVI) from different spectral bands. NDVI, for example, is a powerful indicator of plant health and can be calculated by transforming the red and near-infrared reflectance values.
- 3D Model Generation: Photogrammetry, a common drone application, involves transforming multiple overlapping 2D images into a 3D model or point cloud of the surveyed area. This requires complex transformations to stitch images together and reconstruct geometry.
Sensor Data Processing for Navigation and Autonomy
Drones rely on a suite of sensors – GPS, IMUs, LiDAR, ultrasonic sensors – to navigate and perform autonomous tasks. The data from these sensors often requires significant transformation.
- Sensor Fusion: Data from multiple sensors is combined to create a more accurate and robust understanding of the drone’s environment and state. For example, fusing GPS data with IMU data can provide more precise and smoother position and orientation estimates, especially when GPS signals are weak or intermittent. This involves transforming data into a common coordinate frame and timestamp alignment.
- Coordinate System Transformations: Data from different sensors might be in different local or global coordinate systems. Transformations are applied to align all sensor data into a unified reference frame.
- Filtering and Smoothing: Raw sensor readings, especially from accelerometers and gyroscopes, can be noisy. Filtering techniques like Kalman filters are applied to transform noisy measurements into smoother, more reliable estimates of motion and position.
- LiDAR Point Cloud Processing: LiDAR sensors generate a dense point cloud. Transformations are used to remove ground points, classify objects (e.g., buildings, trees), and extract features like elevation profiles or object dimensions.
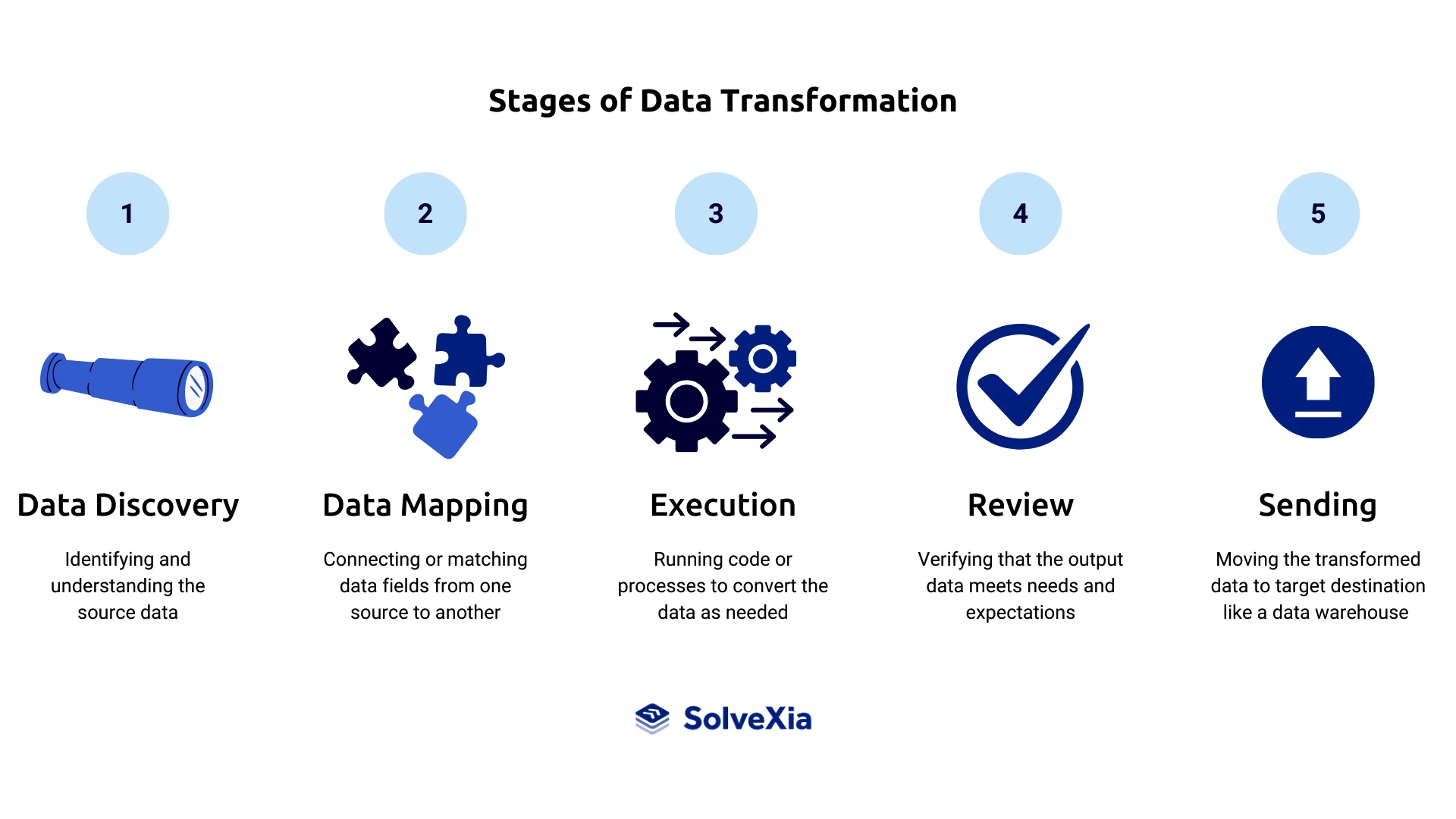
Predictive Maintenance and Performance Monitoring
For commercial drone operations, data from flight logs, motor performance, and battery health can be transformed to predict potential failures and optimize operational efficiency.
- Time Series Analysis: Transforming raw sensor readings over time into features suitable for time-series analysis. This might involve creating rolling averages, calculating rates of change, or identifying cyclical patterns in performance data.
- Anomaly Detection: Transforming flight parameters and sensor readings to identify deviations from normal operating conditions, which could indicate an impending mechanical issue.
- Feature Creation for Machine Learning: Engineering features from flight duration, battery cycle counts, temperature readings, and motor RPMs to train models that predict battery lifespan or motor wear.
In conclusion, data transformation is not just a technical step; it’s an indispensable enabler of advanced drone capabilities. By meticulously preparing and reshaping raw data, we unlock its true potential, leading to more accurate insights, smarter autonomous systems, and ultimately, a more powerful and versatile application of drone technology across numerous industries.