Case-controlled studies represent a fundamental and widely utilized design in epidemiological research, particularly valuable when investigating rare diseases or exposures. This retrospective observational study design allows researchers to examine potential risk factors by comparing individuals who have a specific outcome (cases) with individuals who do not (controls). Unlike cohort studies, which follow a group forward in time to see who develops an outcome, case-controlled studies look backward to identify past exposures that might have contributed to the outcome. This retrospective nature makes them efficient for studying infrequent events, as a large number of participants would need to be followed over a long period in a prospective study to observe enough cases.
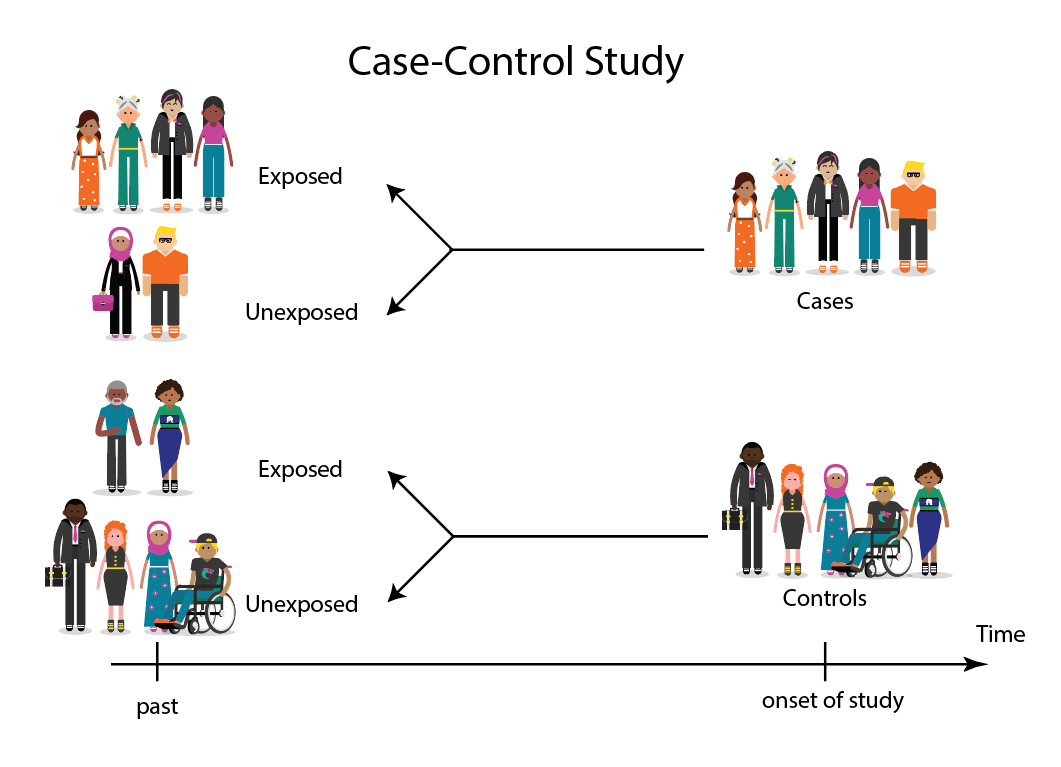
The core principle of a case-controlled study lies in its selection of participants. Researchers begin by identifying a group of individuals who have the disease or condition of interest – these are the “cases.” Simultaneously, they identify a comparable group of individuals who do not have the disease or condition – these are the “controls.” The crucial aspect here is that the controls should be representative of the population from which the cases arose, meaning they should have had a similar probability of being exposed to the risk factors being investigated. Once these groups are established, the researcher then looks back in time to assess the frequency of exposure to various potential risk factors in both the case and control groups.
The Foundation: Identifying Cases and Controls
Defining the Cases
The first and arguably most critical step in a case-controlled study is the precise definition and selection of cases. The clarity and accuracy of this definition directly impact the validity of the study’s findings. Cases should be individuals who have a confirmed diagnosis of the disease or condition under investigation, according to well-established and objective criteria. This might involve specific diagnostic tests, clinical examinations, or pathological findings. Ambiguity in case definition can lead to misclassification, where individuals who do not truly have the disease are included as cases, or vice versa.
There are several approaches to selecting cases:
- Newly Diagnosed (Incident) Cases: These are individuals who have recently been diagnosed with the disease. Using incident cases is generally preferred because it minimizes the potential for recall bias (where individuals with the disease may remember past events differently than those without) and ensures that the exposure occurred before the disease onset.
- Existing (Prevalent) Cases: These are individuals who already have the disease at the time of the study. While easier to recruit, prevalent cases may have different exposure histories than incident cases, as their disease has been present for a longer duration. This can introduce bias.
Selecting the Controls
The selection of appropriate controls is equally paramount. The control group should be a sample of the population from which the cases were drawn, and they should be free from the disease under study. The goal is to ensure that the distribution of potential risk factors in the control group reflects the distribution of these factors in the population at risk for the disease. If the controls are not representative, the comparison between cases and controls will be biased, leading to erroneous conclusions about the association between exposure and disease.
Common sources for control selection include:
- Population-Based Controls: These are individuals selected randomly from the general population, often from registries or census data. This is considered the ideal source for controls as it best represents the underlying population at risk.
- Hospital-Based Controls: Individuals who are patients in the same hospital as the cases but have a different condition. While convenient to recruit, this can introduce bias if the hospital admission itself is related to the exposure being studied. For instance, if a particular exposure leads to a variety of ailments, the hospital-based control group might be disproportionately exposed compared to the general population.
- Family Members or Friends of Cases: While seemingly intuitive, this can also introduce bias, as individuals with similar genetic predispositions or living environments may be more likely to be selected as controls, potentially masking or exaggerating the true association with the exposure.
The number of controls chosen relative to the number of cases can vary. While a 1:1 ratio is common, using more controls per case (e.g., 2:1 or 4:1) can increase the statistical power of the study, especially when the number of cases is limited.
Designing the Study: Matching and Data Collection
The Importance of Matching
Matching is a technique used in case-controlled studies to reduce confounding. Confounding occurs when a third variable (a confounder) is associated with both the exposure and the outcome, distorting the apparent relationship between them. Matching involves selecting controls who are similar to cases with respect to certain characteristics that are known or suspected to be confounders.
Common matching variables include:
- Age: Older individuals are more prone to certain diseases, and exposure patterns can also change with age.
- Sex: Some diseases and exposures are more prevalent in one sex than the other.
- Socioeconomic Status: This can influence both lifestyle and access to healthcare, potentially affecting disease risk and exposure.
- Geographic Location: Environmental factors and lifestyle can vary by location.
There are two main types of matching:
- Individual Matching: Each control is matched to a specific case based on a set of criteria (e.g., an age- and sex-matched control).
- Frequency Matching: The distribution of matching variables in the control group is made similar to that in the case group, without requiring individual pairings.
While matching can be effective in controlling for specific confounders, it also has drawbacks. It can be difficult to match on multiple variables, and if a potential confounder is not identified and matched for, it can still introduce bias. Furthermore, matching can sometimes reduce the efficiency of the study if the matched variables are not strongly related to the outcome.
Gathering Exposure Information
Once cases and controls are selected and potentially matched, the next step is to collect data on past exposures. This is where the retrospective nature of the study becomes evident. Researchers typically employ various methods to ascertain exposure history:
- Interviews and Questionnaires: This is the most common method. Participants are asked about their past exposures to specific substances, behaviors, environmental factors, or medical history. This can be done through face-to-face interviews, telephone surveys, or self-administered questionnaires.
- Medical Records Review: Information on medical history, diagnoses, treatments, and laboratory results can be extracted from existing medical records.
- Biological Samples: Stored biological samples (e.g., blood, urine, tissue) can be analyzed for biomarkers of past exposure.
- Environmental Data: Information from public health records, occupational exposure databases, or geographical surveys can be used to assess environmental exposures.

The accuracy of exposure information is a critical concern in case-controlled studies. Recall bias can be a significant issue, particularly when interviewing individuals about events that occurred long ago. Cases, being ill, may be more motivated to recall or search for potential causes of their illness, leading to an overestimation of exposure. Conversely, controls may have less incentive to remember past exposures. Researchers often employ strategies to mitigate recall bias, such as using objective sources of information (e.g., medical records) whenever possible or blinding interviewers to the case or control status of participants.
Analyzing the Data: Odds Ratios and Interpretation
Calculating the Odds Ratio
The primary measure of association in a case-controlled study is the odds ratio (OR). The odds ratio quantifies how much more likely it is that cases were exposed to a particular factor compared to controls. It is calculated using the data from a 2×2 contingency table that displays the number of exposed cases, unexposed cases, exposed controls, and unexposed controls.
The formula for the odds ratio is:
$OR = (a * d) / (b * c)$
Where:
- a = Number of exposed cases
- b = Number of unexposed cases
- c = Number of exposed controls
- d = Number of unexposed controls
The odds ratio provides an estimate of the relative risk of developing the disease associated with the exposure.
- OR = 1: Indicates no association between the exposure and the disease.
- OR > 1: Suggests that the exposure is associated with an increased risk of the disease.
- OR < 1: Suggests that the exposure is associated with a decreased risk of the disease (i.e., a protective factor).
Interpreting the Odds Ratio
Interpreting the odds ratio requires careful consideration of several factors. A statistically significant odds ratio (determined by a p-value and confidence interval) suggests that the observed association is unlikely to be due to random chance. However, statistical significance does not equate to causality.
Key considerations for interpretation include:
- Causality: Case-controlled studies are observational and cannot prove causation. They can only demonstrate association. Establishing causality requires evidence from multiple studies, biological plausibility, and consideration of other criteria (e.g., Bradford Hill criteria).
- Bias: The potential for bias in case selection, control selection, and exposure assessment must be thoroughly considered. If bias is present, the odds ratio may overestimate or underestimate the true association.
- Confounding: Even with matching, residual confounding might exist. Statistical methods can be used to adjust for potential confounders during the analysis.
- Generalizability: The findings of a case-controlled study are generalizable to the population from which the cases and controls were selected.
Strengths and Limitations of Case-Controlled Studies
Advantages
Case-controlled studies offer several significant advantages, making them a valuable tool in epidemiological research:
- Efficiency for Rare Diseases: They are particularly well-suited for studying rare diseases because it is not necessary to follow a large cohort over time to identify a sufficient number of cases.
- Efficiency for Long Latency Periods: When the time between exposure and disease onset is long, case-controlled studies are more practical than prospective cohort studies, as they do not require prolonged follow-up.
- Cost-Effective: Compared to cohort studies, case-controlled studies are generally less expensive and quicker to conduct.
- Study Multiple Exposures: A single case-controlled study can investigate the association between a disease and multiple potential exposures simultaneously.
- Can Investigate Rare Exposures: While primarily known for rare diseases, they can also be used to study rare exposures.

Disadvantages
Despite their strengths, case-controlled studies also have inherent limitations:
- Potential for Bias: As previously discussed, recall bias, selection bias, and information bias are significant concerns that can compromise the validity of the findings.
- Difficulty in Establishing Temporal Sequence: Because the study is retrospective, it can sometimes be challenging to definitively establish that the exposure preceded the disease, although careful study design aims to mitigate this.
- Not Suitable for Rare Exposures: If an exposure is very rare, it may be difficult to find enough exposed individuals in either the case or control group to make meaningful comparisons, particularly if the disease is not extremely rare.
- Inefficient for Studying Multiple Outcomes: If the goal is to study multiple different diseases, a separate case-controlled study would be needed for each outcome.
- Selection of Appropriate Controls: Finding a suitable control group that accurately represents the source population can be challenging.
In conclusion, the case-controlled study is a powerful and versatile research design that plays a crucial role in understanding the etiology of diseases, particularly those that are rare or have long latency periods. While prone to certain biases, meticulous attention to design, data collection, and analysis can yield valuable insights into the factors that influence health and disease.