In the realm of data analysis, understanding the distribution and characteristics of a dataset is paramount. While raw numbers offer a glimpse, it’s often through graphical representations and summarized statistics that true insights emerge. Among these tools, frequency distributions and histograms stand out for their ability to visually segment and present data. Central to the construction of these powerful tools is the concept of “class width.” This fundamental statistical measure dictates the size of each interval into which data is grouped, profoundly influencing the granularity and interpretability of the resulting analysis.
The class width, sometimes referred to as interval width, is a critical parameter in descriptive statistics, particularly when dealing with continuous or large discrete datasets. It defines the range of values encompassed by a single class or bin in a frequency distribution or histogram. Essentially, it determines how widely each group of data points spans. The choice of class width is not arbitrary; it involves a careful balance between providing sufficient detail and avoiding overwhelming complexity. A class width that is too small might result in too many classes, making the distribution appear erratic and difficult to discern underlying patterns. Conversely, a class width that is too large can obscure important nuances within the data, presenting a overly generalized picture.

The Importance of Class Width in Data Visualization
The efficacy of statistical visualizations like histograms hinges directly on the appropriate selection of class width. Histograms, in particular, offer a visual representation of the probability distribution of a continuous variable. They are constructed by dividing the entire range of data into a series of non-overlapping intervals, known as classes, and then plotting the frequency of data points falling into each class as a bar. The width of these bars, and consequently the width of the classes they represent, is determined by the class width.
Impact on Histogram Shape and Interpretation
The chosen class width directly shapes the appearance of a histogram. A narrow class width will lead to more, thinner bars, potentially highlighting minor fluctuations and local peaks within the data. This can be beneficial for identifying fine-grained patterns or outliers. However, it can also result in a “noisy” histogram, where the overall shape of the distribution becomes obscured by the sheer number of bars.
On the other hand, a wider class width will result in fewer, broader bars. This approach smooths out the distribution, making it easier to identify the general shape, central tendency, and overall spread of the data. It is effective for understanding the broad strokes of a dataset, such as identifying modes (peaks), skewness (asymmetry), and the general range of values. However, excessively wide classes can mask important features, such as multi-modal distributions or significant variations within apparent uniform regions.
The Art of Balancing Granularity and Smoothness
The goal in selecting a class width is to strike a balance between revealing sufficient detail and presenting a clear, interpretable overview. This balance is context-dependent and depends on the nature of the data and the analytical objective. For instance, if the objective is to detect subtle anomalies in sensor readings from a drone’s flight, a smaller class width might be preferred. Conversely, if the aim is to understand the overall flight duration distribution for a fleet of drones across a year, a larger class width would likely be more appropriate.
The number of classes is intrinsically linked to the class width. A common rule of thumb suggests aiming for between 5 and 20 classes for a histogram. However, this is a guideline, not a rigid rule. The optimal number of classes often emerges from experimenting with different class widths. If you calculate a class width and it results in an unusually high or low number of classes, it might be an indicator to adjust the width.
Calculating and Determining Class Width
The process of determining the class width typically begins with understanding the range of the dataset and the desired number of classes. The range is the difference between the maximum and minimum values in the dataset. Once the range is known, a formula can be applied to estimate an appropriate class width.
The Range-Based Formula
A straightforward and widely used method for calculating an initial estimate of the class width involves the following formula:
Class Width = (Maximum Value – Minimum Value) / Number of Classes
Let’s break down the components:
- Maximum Value: This is the highest observed value in your dataset.
- Minimum Value: This is the lowest observed value in your dataset.
- Range: The difference between the Maximum Value and the Minimum Value.
- Number of Classes (k): This is the desired number of intervals into which you want to divide your data. As mentioned, a common starting point is between 5 and 20 classes.
Example: Suppose you have a dataset of drone flight durations in minutes, with a minimum duration of 5 minutes and a maximum duration of 75 minutes. If you decide you want approximately 10 classes for your histogram, the calculation would be:
Class Width = (75 – 5) / 10 = 70 / 10 = 7 minutes.
This suggests that each class should span 7 minutes. The classes might then be: 5-12, 12-19, 19-26, and so on.
Sturges’ Rule and Other Heuristics

While the range-based formula is practical, other statistical heuristics can also guide the selection of the number of classes, which in turn influences the class width. One such heuristic is Sturges’ Rule, which provides an estimate for the optimal number of classes:
k = 1 + 3.322 * log10(n)
Where:
- k is the number of classes.
- n is the total number of data points in the dataset.
Example: If you have a dataset of 100 drone flight durations (n=100), Sturges’ Rule would suggest:
k = 1 + 3.322 * log10(100)
k = 1 + 3.322 * 2
k = 1 + 6.644
k ≈ 7.644
This suggests approximately 7 or 8 classes. If you opt for 8 classes, you would then use the range-based formula to calculate the class width.
Other heuristics, such as the square root rule (k = √n), also exist but are generally less precise than Sturges’ Rule for larger datasets. The key takeaway is that these rules provide starting points.
Rounding and Practical Considerations
In practice, it’s often beneficial to round the calculated class width to a convenient number, such as a whole number or a number ending in 0 or 5. This makes it easier to define the class boundaries and interpret the intervals. For instance, if the calculation yields a class width of 6.8, rounding up to 7 or down to 6 might be practical. If the calculation yields 7.1, rounding up to 8 might be preferable for cleaner intervals. The choice of rounding should still maintain a reasonable number of classes and not drastically alter the visualization’s effectiveness.
Once the class width is determined and rounded, the class intervals can be established, starting from the minimum value. For example, if the minimum value is 5 and the rounded class width is 7, the first class would be 5 to less than 12 (or 5-11 inclusive, depending on convention), the second class from 12 to less than 19, and so on. It is crucial to ensure that the classes are contiguous and cover the entire range of the data without any gaps or overlaps.
Adjusting Class Width for Optimal Analysis
The initial calculation of class width is often a starting point. True analytical insight often comes from iterating and adjusting this parameter to best reveal the underlying structure of the data. The process of refinement involves examining the resulting histogram or frequency table and considering whether it effectively communicates the data’s story.
Identifying Patterns and Anomalies
When constructing a histogram, one should look for clarity in the emerging shape. Are the peaks (modes) distinct? Is the distribution skewed or symmetric? Is there evidence of unusual clusters or gaps in the data? If the histogram appears too jagged and erratic, the class width might be too small, leading to too many classes. In such cases, increasing the class width can smooth out the distribution and reveal broader trends.
Conversely, if the histogram appears overly smooth, with only a few very wide bars, important details might be lost. This could indicate that the class width is too large. Decreasing the class width will create more, narrower classes, allowing for a closer examination of potential sub-patterns or outliers that were previously masked.
The Role of Domain Knowledge
The selection of class width should not be purely a mathematical exercise; it should also be informed by domain knowledge. For instance, if you are analyzing drone battery life in hours, and you know that battery performance often shows distinct differences at critical thresholds (e.g., near 30 minutes, near 1 hour), you might choose a class width that aligns with these known critical points, even if it deviates slightly from a purely mathematical calculation. This allows the visualization to highlight features that are meaningful within the specific context of drone operations.
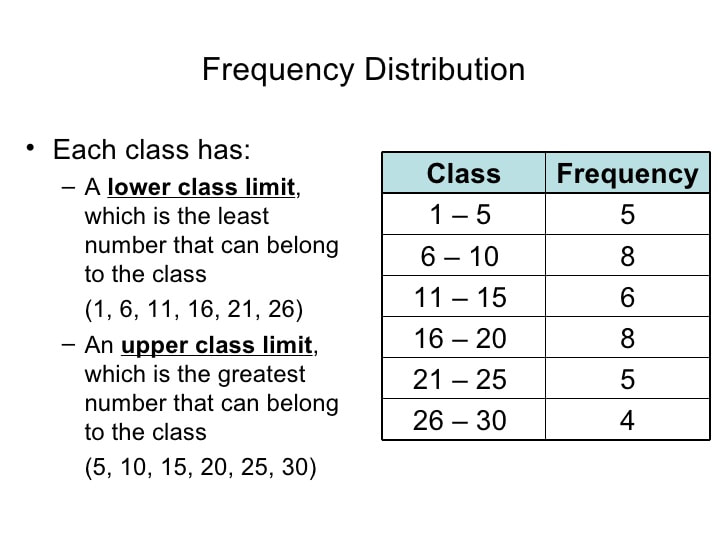
Iterative Refinement and Tools
Statistical software packages and spreadsheet programs offer powerful tools for generating histograms and experimenting with class width. Most of these tools allow users to specify the number of bins (classes) or the exact bin width. This enables a quick iterative process: generate a histogram with one class width, examine its output, adjust the width, and regenerate. This hands-on approach is invaluable for discovering the most informative representation of the data.
For instance, a data scientist analyzing aerial imagery acquisition patterns might initially set a class width based on typical flight times. Upon reviewing the histogram, they might notice a distinct bimodal distribution that was not immediately apparent. They might then adjust the class width to better delineate these two distinct flight patterns, perhaps identifying different operational modes or pilot behaviors that contribute to these variations. This iterative refinement, guided by both statistical principles and an understanding of the data’s context, is key to extracting meaningful insights.
In conclusion, the class width is far more than just a numerical parameter; it is a design choice that profoundly impacts our ability to understand and interpret statistical data. By carefully considering its calculation, its effect on visualizations, and through iterative refinement informed by domain knowledge, analysts can harness the power of class width to transform raw data into actionable insights, whether it pertains to the performance of cutting-edge drone technology, the intricacies of flight stabilization systems, or the creative possibilities of aerial filmmaking.