In an age defined by an explosion of information, where data is generated at an unprecedented rate, the ability to find what you’re looking for quickly and accurately is not merely a convenience—it’s a fundamental necessity. From browsing the internet and sifting through corporate documents to analyzing vast datasets, the speed and precision with which we locate relevant information underpin nearly every digital interaction. At the heart of this capability lies a sophisticated, often invisible, technological process: search indexing.
Search indexing is the intricate mechanism that transforms disorganized oceans of data into highly structured, rapidly searchable repositories. It is the ingenious solution to the daunting challenge of instantaneously retrieving specific pieces of information from billions of documents, web pages, or data points. Without it, the digital landscape we navigate daily would be an unusable wilderness, and innovations ranging from AI-powered search to complex data analytics would be impossible. This article delves into the core concepts, architecture, and profound significance of search indexing in the realm of modern tech and innovation.
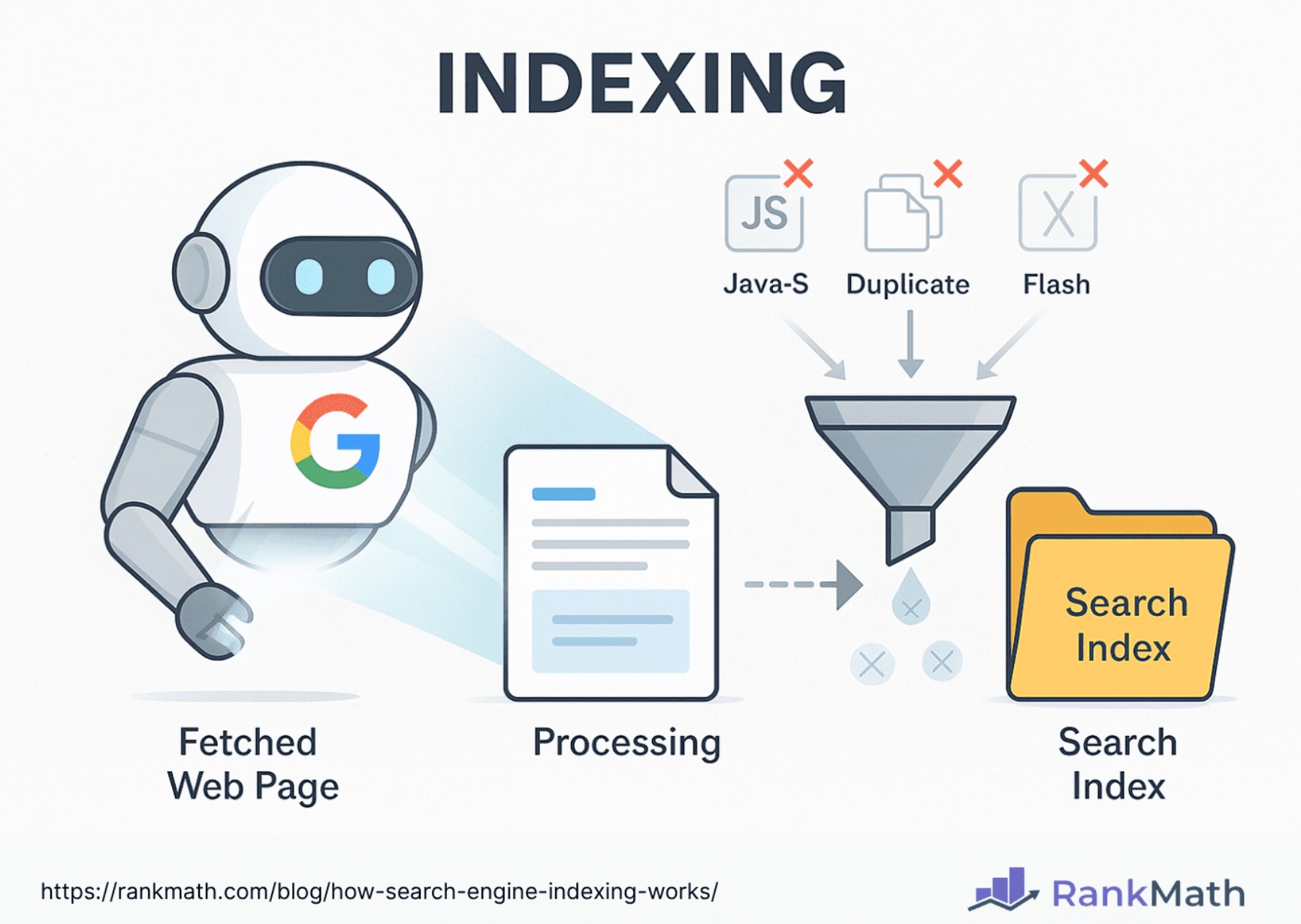
The Core Concept of Search Indexing
At its essence, search indexing is about creating an efficient map or a meticulously organized catalog of information. Imagine trying to find a specific phrase in every book in a massive library without an index; it would be a Sisyphean task. Search indexing provides that “index” for the digital world, but on an exponentially grander scale and with far greater complexity.
Beyond Simple Databases: The Need for Speed
Traditional databases are excellent for structured data queries, such as “find all customers in New York.” However, they become notoriously inefficient when faced with unstructured text search queries like “find all documents mentioning quantum computing breakthroughs and neural networks published last year.” Scanning every record sequentially for keywords in a massive collection of text is prohibitively slow, especially when dealing with the petabytes of data that define modern information systems.
This is where the concept of an inverted index emerges as the cornerstone of efficient search. Unlike a book’s index that maps topics to page numbers, an inverted index maps words or terms to the documents in which they appear. This inversion of the traditional document-to-term relationship is what makes near-instantaneous search possible.
How an Inverted Index Works
To grasp the inverted index, consider a simple analogy: imagine you have thousands of books, and you want to quickly find all books that contain the word “innovation.” Instead of reading every book, you could create a master list. This list would contain every unique word found across all books, and next to each word, you’d list all the books (and perhaps even page numbers) where that word appears.
In the digital realm, an inverted index works similarly:
- Terms: It first identifies all unique words or “terms” found within a collection of documents (e.g., web pages, articles, database entries).
- Document IDs: For each unique term, it creates a list of “document IDs” (unique identifiers for each document) where that term appears.
- Metadata: Often, the index stores additional metadata for each term-document pair, such as:
- Term Frequency: How many times the term appears in that document.
- Position: The exact locations (e.g., word 5, word 120) where the term appears within the document, crucial for phrase search and proximity queries.
- Field Information: If the term appeared in a specific field (e.g., title, body, author, tags).
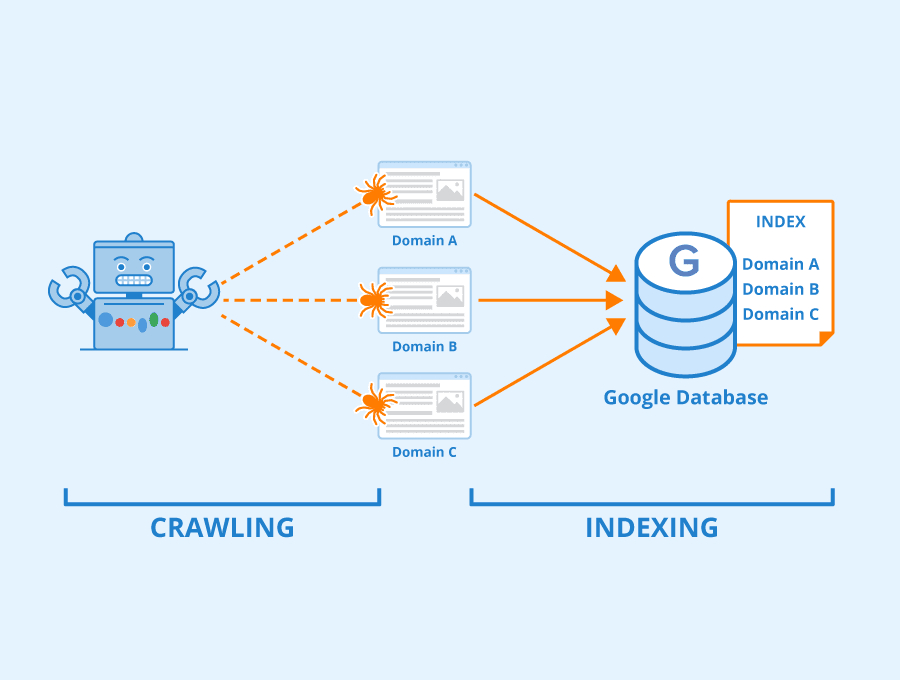
When you submit a search query, the search engine doesn’t scan the original documents. Instead, it consults this pre-built inverted index, which acts like a super-fast dictionary. It quickly finds the list of document IDs associated with your query terms, dramatically reducing the search time from minutes or hours to milliseconds.
The Indexing Pipeline: From Data to Discovery
Building and maintaining this sophisticated index is itself a multi-stage technological marvel, often referred to as the “indexing pipeline”:
- Crawling/Data Ingestion: The process begins by gathering raw data. For web search engines, this involves “crawlers” (or “spiders”) systematically exploring the internet, downloading web pages. For enterprise search, it might involve ingesting documents from file systems, databases, or content management systems.
- Parsing & Tokenization: Once the data is acquired, it’s parsed to extract the meaningful content, stripping away irrelevant formatting (HTML tags, menus, etc.). This content is then “tokenized,” breaking it down into individual words or terms.
- Linguistic Processing: To improve search relevance, linguistic analysis is applied. This includes:
- Stop Word Removal: Eliminating common, less meaningful words like “a,” “the,” “is” (unless they are part of a specific phrase).
- Stemming/Lemmatization: Reducing words to their root form (e.g., “running,” “ran,” “runs” all become “run”) to ensure that searches for related words yield consistent results.
- Index Construction: The processed terms and their associated metadata are then systematically added to the inverted index. This often involves complex algorithms to optimize storage and retrieval efficiency, handling updates, deletions, and additions without rebuilding the entire index from scratch.
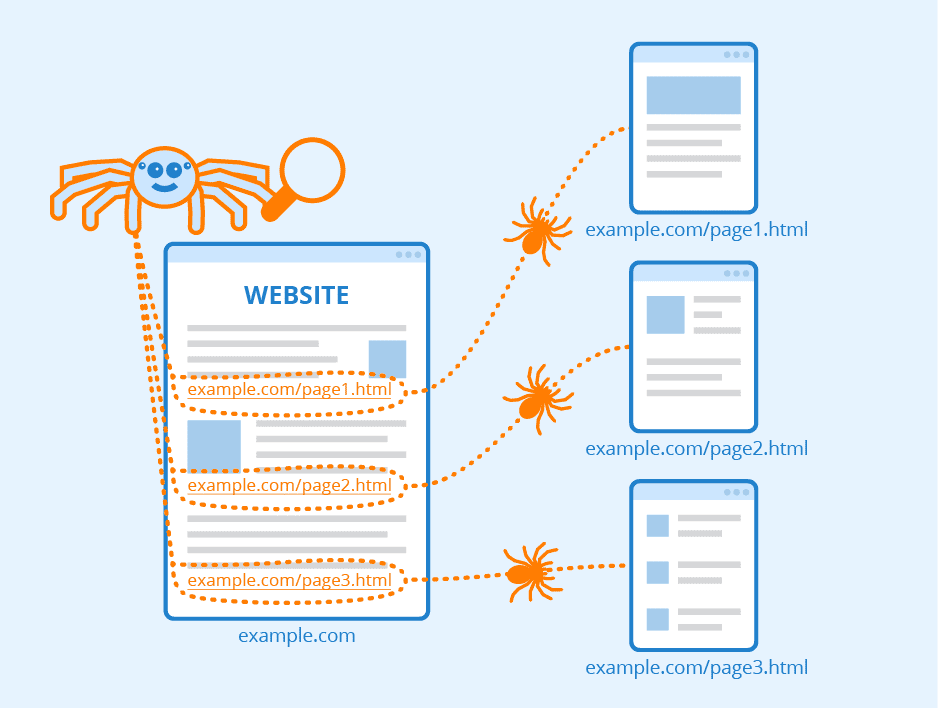
The Architecture of an Indexing System
The scale and complexity of modern information systems demand equally sophisticated indexing architectures. A single, monolithic index is impractical for the vastness of the internet or large enterprise data lakes.
Distributed Indexing: Handling Scale
To cope with billions of documents and trillions of terms, indexing systems employ distributed architectures. This involves:
- Sharding: The entire index is broken down into smaller, manageable partitions called “shards,” each stored on a separate server or cluster of servers. Each shard indexes a subset of the total document collection.
- Replication: To ensure high availability and fault tolerance, each shard is often replicated across multiple machines. If one server fails, a replica can seamlessly take over.
- Load Balancing: Incoming search queries are routed to the appropriate shards, and results from multiple shards are aggregated and presented to the user, creating the illusion of a single, unified search.
This distributed approach not only enables horizontal scalability—allowing systems to grow by simply adding more servers—but also enhances performance by parallelizing indexing and search operations.
Index Storage and Retrieval Mechanisms
The physical storage and retrieval of the index are critical for performance. Indexes can be stored:
- On Disk: Traditional method, leveraging hard drives or SSDs. Requires efficient disk I/O operations and optimized data structures (like B-trees or skip lists) to minimize seek times.
- In-Memory: For extremely high-performance scenarios, portions or even entire indexes can be loaded into RAM. This offers unparalleled speed but is limited by available memory and is more volatile. Hybrid approaches are common, using disk for persistence and memory for hot data.
Advanced techniques like compression, caching, and specialized file formats are employed to minimize storage footprint and maximize retrieval speed. The efficiency of these mechanisms directly impacts the responsiveness of any search-driven application.
Real-time vs. Batch Indexing
How frequently an index is updated is a critical design consideration, leading to two primary paradigms:
- Batch Indexing: Involves processing large volumes of data at scheduled intervals (e.g., nightly, weekly). This is resource-efficient as it can leverage periods of low system usage. It’s suitable for data that doesn’t require immediate searchability, such as historical archives or less frequently updated content.
- Real-time Indexing: Designed for data that needs to be searchable almost instantaneously after creation or modification. This involves continuous updates to the index as data streams in. It’s more complex to implement and resource-intensive but crucial for applications like news feeds, e-commerce product availability, or social media updates. Achieving real-time indexing often involves sophisticated queuing, distributed messaging, and incremental indexing techniques.
The Strategic Importance in Modern Tech & Innovation
Search indexing is far more than just the technology behind Google; it’s a foundational pillar supporting a vast ecosystem of technological innovation. Its principles and implementations permeate nearly every facet of the digital world.
Fueling Information Retrieval and Search Engines
The most obvious application of search indexing is in powering general-purpose search engines like Google, Bing, and DuckDuckGo. These engines rely on massive, constantly updated indexes of the entire public web to provide relevant search results within milliseconds. But beyond web search, indexing is critical for:
- Enterprise Search: Enabling employees to quickly find documents, emails, and data within an organization’s internal networks.
- E-commerce Product Search: Allowing shoppers to find specific products from millions of listings, often with complex filtering and attribute-based searches.
- Legal Discovery: Rapidly sifting through vast amounts of legal documents to find relevant evidence.
The quality of an index directly correlates with the accuracy and speed of search, influencing user experience and operational efficiency across countless applications.
Beyond Web Search: Specialized Applications
The utility of indexing extends far beyond traditional document search. Its core principle of mapping terms to locations is invaluable for various specialized tech applications:
- Log Analysis and Security Information and Event Management (SIEM): Indexing machine logs (from servers, networks, applications) allows security analysts to quickly search for patterns, anomalies, and potential threats across petabytes of event data, crucial for cybersecurity and operational monitoring.
- Data Analytics Platforms: While distinct from traditional databases, many modern big data analytics platforms leverage indexing-like structures to accelerate queries over large datasets, especially for full-text search within data fields or for rapidly filtering based on specific values.
- Recommendation Systems: Indexing user preferences, product attributes, and content features can help power personalized recommendations by quickly finding items similar to what a user has liked or viewed.
A Foundation for AI and Machine Learning
Search indexing plays an indirect but significant role in the advancement of AI and Machine Learning (ML), particularly in areas dealing with vast amounts of textual or semi-structured data:
- Natural Language Processing (NLP): Indexed data provides the raw material for training NLP models, allowing them to learn language patterns, semantics, and context. Search systems themselves often incorporate NLP techniques to understand queries better and retrieve more semantically relevant results.
- Knowledge Graphs and Semantic Search: As AI moves towards understanding meaning rather than just keywords, search indexing evolves. It is instrumental in building and querying knowledge graphs, which represent relationships between entities. Semantic search leverages these structures, often built upon sophisticated indexing of concepts and relationships, to provide answers rather than just documents.
- Vector Search: With the rise of deep learning, information can be represented as high-dimensional “vectors” (embeddings). Indexing techniques are being adapted to efficiently search these vector spaces for similarity, enabling new forms of search for images, audio, and highly contextual information that goes beyond simple keyword matching.
Challenges and Future Directions in Indexing
Despite its maturity, search indexing is a field of continuous innovation, driven by the relentless growth of data and the increasing demand for intelligence from information.
The Ever-Growing Data Volume and Velocity
The biggest ongoing challenge is simply scale. The amount of digital data is doubling every few years, and much of it is unstructured or semi-structured. Indexing systems must evolve to:
- Handle unprecedented volumes: Efficiently store and process exabytes of data.
- Cope with velocity: Process streaming data in real-time without compromising search freshness or performance.
- Manage diverse data types: Index not just text, but images (through metadata or visual features), videos (transcripts, scene detection), and complex sensor data.
Innovations in distributed computing, storage technologies, and streaming data architectures are crucial for meeting these demands.
Semantic Search and Understanding Context
The future of search is semantic. Users want answers, not just lists of documents. This requires indexing systems to move beyond simple keyword matching to genuinely understand the intent behind a query and the meaning within the content.
- Knowledge Graph Integration: Tightly integrating indexes with knowledge graphs will allow systems to reason about relationships between entities and provide more insightful results.
- AI-Powered Indexing: Using machine learning to automatically extract entities, topics, and sentiment during the indexing process will enrich the index with semantic information, enabling more intelligent search capabilities.
- Query Understanding: AI models are increasingly used to interpret ambiguous queries, correcting typos, expanding synonyms, and understanding context to retrieve more precise information.
Privacy, Security, and Ethical Indexing
As indexing becomes more powerful and pervasive, the ethical implications and security challenges grow. Ensuring that sensitive or proprietary information is only indexed and retrieved by authorized users is paramount. This involves:
- Access Control Integration: Tightly coupling indexing systems with enterprise access control mechanisms to enforce document-level security.
- Data Masking and Encryption: Protecting data at rest and in transit during the indexing process.
- Ethical Data Collection: Adhering to privacy regulations (like GDPR) and ethical guidelines regarding what data is collected, indexed, and made discoverable.
Quantum Computing and Future Indexing Paradigms
While speculative, advancements in quantum computing hold the potential to revolutionize search algorithms, potentially offering exponentially faster ways to search massive, complex datasets. While practical applications are still distant, the underlying mathematical principles could inspire entirely new indexing paradigms that address challenges currently deemed insurmountable. This represents the ultimate horizon for innovation in information retrieval.
Conclusion
Search indexing is an unsung hero of the digital age, a complex technological marvel that operates silently behind every successful search query, every intelligent recommendation, and every data-driven insight. It is the intricate bridge between a chaotic world of information and our innate human need for discovery. As the volume, velocity, and variety of data continue to explode, the field of search indexing will remain a fertile ground for innovation, evolving with advanced algorithms, distributed architectures, and sophisticated AI integrations. Its ongoing development is not just about making search faster, but about making information more accessible, more meaningful, and ultimately, more powerful for human progress in the vast landscape of tech and innovation.