Online recommendation engines have become an indispensable part of the digital landscape, silently shaping our online experiences across a vast array of platforms. From suggesting the next product to purchase on an e-commerce site to curating personalized news feeds and entertainment content, these sophisticated systems leverage data and algorithms to predict user preferences and deliver tailored suggestions. At their core, recommendation engines aim to enhance user engagement, drive conversions, and create a more personalized and satisfying digital journey.
The Core Mechanics of Recommendation Engines
At a fundamental level, recommendation engines operate by analyzing vast amounts of data to understand user behavior and item characteristics. This data can encompass a wide range of information, including past purchases, viewing history, search queries, ratings, demographic information, and even the behavior of similar users. The ultimate goal is to identify patterns and relationships that can be used to predict what a specific user might be interested in next.

Collaborative Filtering
One of the most prevalent and powerful techniques employed by recommendation engines is collaborative filtering. This approach operates on the principle that users who have agreed in the past will likely agree in the future. It can be broadly categorized into two main types:
User-Based Collaborative Filtering
In user-based collaborative filtering, the engine identifies users who share similar tastes or behaviors with the target user. It then recommends items that these similar users have liked or interacted with but that the target user has not yet encountered. For instance, if User A and User B both liked movies X, Y, and Z, and User A also liked movie W, the system might recommend movie W to User B. This method relies heavily on finding “neighbors” – users with overlapping preferences.
Item-Based Collaborative Filtering
Item-based collaborative filtering, on the other hand, focuses on the relationships between items. It analyzes user interaction data to determine which items are frequently liked or purchased together. If many users who liked Item P also liked Item Q, then when a new user shows interest in Item P, Item Q is recommended. This approach often proves more scalable and computationally efficient than user-based filtering, especially in systems with a large number of users.
Content-Based Filtering
Unlike collaborative filtering, which relies on the behavior of other users, content-based filtering makes recommendations based on the characteristics of the items themselves and the user’s past preferences for those characteristics. The system builds a profile for each user based on the attributes of items they have interacted with positively. For example, if a user frequently watches action movies with a specific actor, the engine will recommend other action movies starring that actor or movies with similar plot elements and themes.
Feature Extraction and Representation
The success of content-based filtering hinges on the ability to effectively extract and represent the relevant features of items. For movies, these features might include genre, actors, directors, plot keywords, and even directorial style. For products, it could be brand, color, material, price range, and technical specifications. Sophisticated natural language processing (NLP) techniques are often used to analyze textual descriptions and extract meaningful features.
User Profile Construction
Once item features are identified, a user profile is created. This profile dynamically updates as the user interacts with more items. It represents the user’s learned preferences, often as a weighted set of features. The recommendation engine then matches this user profile against the features of un-seen items to find the best matches.
Hybrid Approaches
Recognizing the limitations of purely collaborative or content-based methods, many modern recommendation engines employ hybrid approaches. These systems combine multiple techniques to leverage their respective strengths and mitigate their weaknesses.
Combining Strengths
A hybrid system might use collaborative filtering to discover new, unexpected interests, while content-based filtering ensures that recommendations remain relevant to the user’s known preferences. For example, if a user has a strong preference for science fiction movies, collaborative filtering might suggest a comedy movie that users with similar sci-fi tastes have also enjoyed. This can lead to more diverse and potentially more satisfying recommendations.
Addressing Cold-Start Problems
One of the significant challenges in recommendation systems is the “cold-start” problem. This occurs when there is insufficient data about a new user or a new item to make accurate recommendations. Hybrid models can effectively address this. For new users, content-based filtering can be used initially based on their stated preferences or demographic information. For new items, if their features are well-defined, content-based filtering can be applied to match them with relevant users.
The Role of Machine Learning and Data Science
The development and refinement of recommendation engines are deeply rooted in the principles of machine learning and data science. These fields provide the theoretical frameworks and practical tools necessary to build, train, and optimize these complex systems.
Algorithm Selection and Training
The choice of algorithms is critical and depends on the specific application, the nature of the data, and the desired outcome. Common machine learning algorithms used in recommendation engines include:
Matrix Factorization
Techniques like Singular Value Decomposition (SVD) and Non-negative Matrix Factorization (NMF) are popular for matrix factorization. These methods decompose the user-item interaction matrix into lower-dimensional latent factor matrices, representing users and items in a shared feature space. This allows for the prediction of missing ratings or interactions.
Deep Learning Models
More recently, deep learning architectures, such as Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), have shown remarkable success in recommendation systems. Deep learning can capture complex, non-linear relationships in data, leading to more nuanced and accurate predictions, especially for sequential data like user clickstreams or viewing histories.
Reinforcement Learning
Reinforcement learning approaches are also being explored, where the recommendation engine learns through trial and error, optimizing its strategies over time to maximize user engagement or other defined rewards.
Feature Engineering and Selection
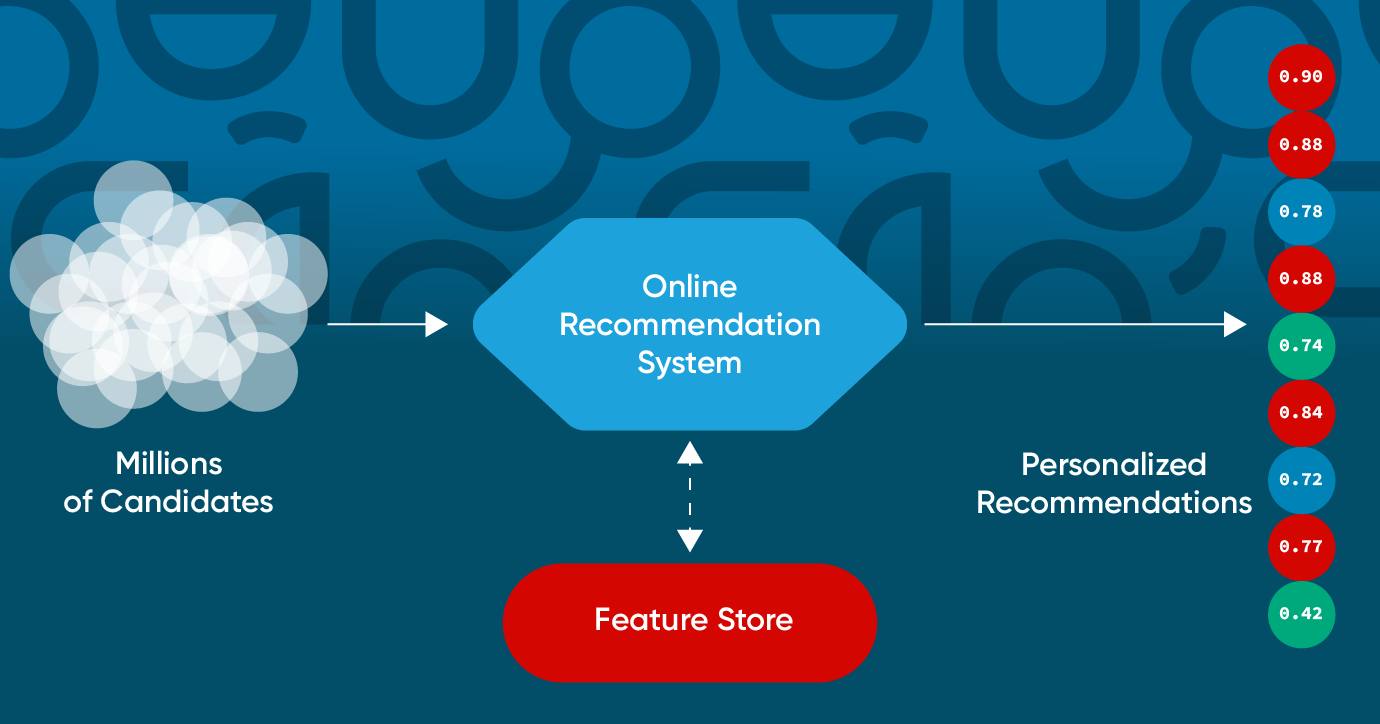
Beyond algorithm selection, feature engineering plays a crucial role. This involves transforming raw data into features that are more informative and predictive for the chosen algorithms. This can include creating interaction features, temporal features (e.g., time of day, seasonality), and contextual features (e.g., device type, location). Effective feature selection ensures that the most relevant data points are used, improving model performance and efficiency.
Evaluation Metrics
Measuring the performance of a recommendation engine is essential for iterative improvement. Various metrics are used, including:
Precision and Recall
These metrics evaluate the accuracy of the recommendations, measuring how many of the recommended items are relevant and how many relevant items are actually recommended.
Mean Average Precision (MAP)
MAP is a popular metric for ranking tasks, assessing the overall quality of the ranked list of recommendations.
Click-Through Rate (CTR) and Conversion Rate
In e-commerce and advertising contexts, metrics like CTR and conversion rate directly measure the effectiveness of recommendations in driving user actions.
Diversity and Novelty
Beyond accuracy, metrics that measure the diversity (variety of recommendations) and novelty (recommendations of items the user might not have found otherwise) are increasingly important for user satisfaction and long-term engagement.
Applications and Impact
The pervasive nature of recommendation engines means their impact is felt across numerous industries and aspects of our digital lives. Their ability to personalize experiences has revolutionized how we consume information, shop, and entertain ourselves.
E-commerce
In online retail, recommendation engines are paramount for driving sales. By suggesting relevant products based on browsing history, past purchases, and the behavior of similar shoppers, they help users discover items they might not have found otherwise. This not only increases the average order value but also significantly enhances the customer’s shopping experience, fostering loyalty.
Streaming Services
Platforms like Netflix, Spotify, and YouTube heavily rely on recommendation engines to keep users engaged. By analyzing viewing and listening habits, these systems curate personalized playlists, movie suggestions, and video recommendations, ensuring users always have something new and interesting to discover, thereby reducing churn.
Social Media
Social media platforms use recommendation engines to personalize user feeds, suggest friends, and highlight trending content. This helps maintain user interest by surfacing posts, articles, and people most likely to resonate with their individual preferences and social connections.
News and Content Platforms
News aggregators and content publishers employ recommendation engines to deliver articles, blog posts, and other forms of content tailored to a user’s interests. This increases reader engagement and time spent on the platform.
Beyond the Consumer Realm
Recommendation engines are also finding applications in less obvious areas. In healthcare, they can suggest personalized treatment plans or relevant research papers to physicians. In education, they can recommend learning resources to students based on their progress and learning style.
Challenges and Future Directions
Despite their widespread success, recommendation engines face ongoing challenges, and the field is continuously evolving.
Data Sparsity and Cold Start
As mentioned earlier, dealing with situations where there is limited data for new users or items remains a significant hurdle. Innovative approaches, including leveraging external data sources, more sophisticated user onboarding processes, and advanced transfer learning techniques, are being developed.
Privacy and Ethical Considerations
The extensive data collection required by recommendation engines raises significant privacy concerns. Ensuring transparency, user control over data, and ethical data handling practices are critical for maintaining user trust. The potential for filter bubbles and algorithmic bias, where users are only exposed to information that confirms their existing beliefs, is also a growing area of concern.
Real-time Recommendations and Dynamic Adaptation
The ability to provide real-time recommendations that adapt instantly to a user’s current context and evolving preferences is a key area of research and development. This requires highly efficient and scalable systems capable of processing streaming data and updating models on the fly.
Explainability and Transparency
Users often appreciate knowing why a particular recommendation was made. Developing more explainable AI models that can provide clear justifications for their suggestions is crucial for building user confidence and understanding.
The future of recommendation engines is bright, with continued advancements in AI, a deeper understanding of user behavior, and a growing emphasis on ethical and responsible AI development. As these systems become even more sophisticated, they will undoubtedly continue to shape our digital interactions in profound and personalized ways.