Observability, a concept gaining significant traction in the realm of DevOps, is often discussed alongside terms like monitoring and logging. While these are related, observability offers a more profound and proactive approach to understanding the inner workings of complex systems. In essence, observability is the ability to infer the internal state of a system by examining the external data it produces. For DevOps teams, this translates into a powerful toolkit for troubleshooting, performance optimization, and ultimately, delivering more reliable and resilient software.
The shift towards microservices architectures, containerization, serverless computing, and cloud-native environments has amplified the need for robust observability. These distributed systems are inherently more dynamic and complex than their monolithic predecessors. When something goes wrong, pinpointing the root cause can be like finding a needle in a haystack. Observability provides the crucial visibility required to navigate this complexity, enabling teams to not only detect issues but also to understand why they are happening and how to prevent them in the future.
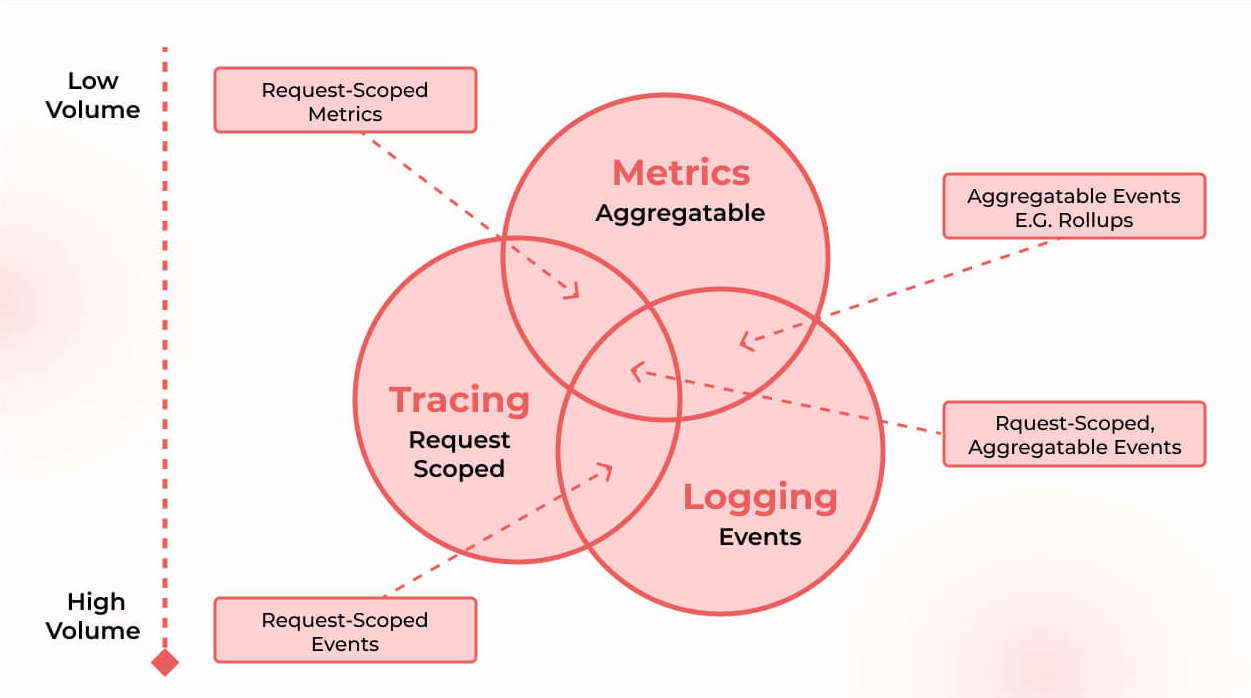
The Pillars of Observability: Logs, Metrics, and Traces
To truly grasp observability, it’s essential to understand its foundational components. While the term “observability” encompasses the broader capability, it is built upon the effective collection and analysis of three key types of data: logs, metrics, and traces. Each provides a unique lens through which to view system behavior, and when used in conjunction, they offer a comprehensive picture.
The Role of Logs in System Understanding
Logs are records of discrete events that occur within a system. They capture specific actions, errors, warnings, or informational messages generated by applications, servers, or infrastructure. In the context of DevOps, logs are invaluable for historical analysis and detailed investigation of individual occurrences.
Granular Event Recording
Each log entry typically contains a timestamp, the source of the event (e.g., a specific service or server), a severity level (e.g., INFO, WARN, ERROR), and a descriptive message. For instance, a web server might log a request being received, a database might log a successful query, or an application might log an exception being thrown. The granularity of logs allows engineers to reconstruct the sequence of events leading up to a problem.
Debugging and Root Cause Analysis
When an error occurs, developers and operators can sift through logs to identify the exact point of failure. By correlating log messages across different services, they can trace the flow of requests and pinpoint which component is misbehaving. For example, if a user reports a slow response time, logs might reveal that a particular microservice is experiencing high latency in its database queries.
Limitations and the Need for Context
While logs are indispensable for deep dives, they can become unwieldy and difficult to analyze in large-scale, distributed systems. The sheer volume of log data can make it challenging to extract meaningful insights without sophisticated tooling. Furthermore, logs often provide a snapshot of what happened but may not always reveal the performance implications or the overall impact on the system’s health. This is where metrics and traces come into play.
Leveraging Metrics for Performance Insights
Metrics are numerical representations of system performance and behavior over time. Unlike logs, which capture discrete events, metrics provide aggregated, quantifiable data points that illustrate trends and patterns. They are crucial for understanding the “health” of a system and for identifying performance bottlenecks.
Quantifying System Behavior
Metrics can capture a wide range of information, such as CPU utilization, memory consumption, network traffic, request latency, error rates, and queue lengths. These are typically collected at regular intervals and aggregated into time-series data. For example, a metric might track the average response time of an API endpoint over the last minute, or the number of failed login attempts in an hour.
Identifying Trends and Anomalies
By analyzing metrics, DevOps teams can establish baseline performance levels and detect deviations that might indicate an impending issue. Sudden spikes in error rates, a consistent increase in latency, or a depletion of available resources are all strong indicators that something needs attention. This allows for proactive intervention before a minor problem escalates into a major outage.
Performance Optimization and Capacity Planning
Metrics are fundamental to performance tuning. By observing which components are consuming the most resources or are experiencing the highest load, teams can identify areas for optimization. Furthermore, historical metric data is essential for capacity planning, helping organizations anticipate future resource needs and scale their infrastructure accordingly.
The Power of Traces for Understanding Request Flows
Distributed tracing is a technique that tracks the entire lifecycle of a request as it propagates through multiple services in a distributed system. This provides an end-to-end view of how requests are handled, allowing for the identification of performance bottlenecks and dependencies between services.
Mapping the Journey of a Request
When a request enters a system (e.g., a user clicks a button on a website), a unique trace ID is generated. As this request is processed by various microservices, each service adds its own span, which represents the work performed by that service. These spans are linked together by the trace ID, creating a visual representation of the request’s journey from origin to completion.
Pinpointing Latency and Dependencies
Traces are incredibly powerful for diagnosing performance issues in distributed environments. By examining a trace, an engineer can quickly see which service took the longest to respond, where delays were introduced, and how services depend on each other. This eliminates the guesswork involved in trying to identify the slowest link in a complex chain of operations.
Visualizing Service Interactions
Trace visualizations often present a waterfall-like diagram, where the width of each span indicates the time taken by a particular service. This visual clarity makes it easy to spot bottlenecks. Moreover, traces can reveal unexpected dependencies, such as a critical service waiting for a less critical one, which might indicate an architectural flaw or an inefficient design.
The Observability Loop: Detect, Diagnose, and Resolve
Observability is not merely about collecting data; it’s about fostering a continuous cycle of improvement. By integrating logs, metrics, and traces, DevOps teams can create a powerful feedback loop that enables them to proactively identify, deeply diagnose, and swiftly resolve issues, ultimately enhancing system reliability and user experience.
Proactive Detection and Alerting
The first step in the observability loop is to detect potential problems before they significantly impact users. This is achieved through intelligent alerting systems that are configured based on observed metrics and anomalies.
Setting Meaningful Thresholds
Rather than relying on simplistic static thresholds, modern observability platforms leverage machine learning and historical data to set more dynamic and context-aware alerts. This reduces alert fatigue and ensures that teams are notified of genuine issues.
Correlating Signals for Early Warning
By combining data from logs, metrics, and traces, teams can create sophisticated alerting rules. For instance, a spike in error rate (metric) coupled with specific error messages in logs and an increase in latency for a particular trace can trigger a high-priority alert. This correlation helps identify emergent issues that might be missed by monitoring individual signals in isolation.
Deep Diagnosis and Root Cause Identification
Once an issue is detected, the next critical phase is to diagnose its root cause. This is where the combined power of observability data truly shines.
Interactive Exploration of Data
Observability platforms provide interactive dashboards and query interfaces that allow engineers to explore logs, metrics, and traces simultaneously. They can pivot between different data types, zoom into specific timeframes, and filter data based on various dimensions (e.g., service name, user ID, request type).
Understanding Systemic Impact
By analyzing traces and correlating them with metrics and logs, teams can understand the broader impact of an issue across the system. For example, a single failing component might trigger a cascade of errors in dependent services, leading to a widespread outage. Observability helps visualize this systemic impact.
Identifying Performance Bottlenecks and Inefficiencies
Traces are instrumental in pinpointing performance bottlenecks. By examining the duration of spans within a trace, engineers can identify which services are contributing the most to latency. This information is invaluable for optimizing code, tuning database queries, or re-architecting inefficient service interactions.
Swift Resolution and Continuous Improvement
The ultimate goal of observability is to enable rapid resolution of issues and to leverage the insights gained to prevent recurrence.
Actionable Insights for Remediation
Observability platforms aim to provide actionable insights that guide engineers towards the solution. Instead of just flagging a problem, they help explain why it’s happening. This could involve recommending a specific configuration change, suggesting a code refactor, or highlighting a resource constraint.
Post-Mortem Analysis and Knowledge Sharing
The data collected through observability is invaluable for post-mortem analyses after an incident. By reviewing the logs, metrics, and traces associated with an event, teams can gain a deep understanding of what went wrong, how it was detected, and how it was resolved. This knowledge is crucial for refining incident response procedures and for driving continuous improvement in system design and operation.
Feedback for Development and Operations
The insights derived from observability data should feed back into both the development and operations processes. Developers can use this information to identify areas where their code might be causing performance issues or generating excessive errors. Operations teams can use it to refine their deployment strategies, optimize infrastructure, and improve their monitoring and alerting configurations.
Building an Observability Culture in DevOps
Implementing observability effectively goes beyond just adopting new tools; it requires fostering a culture that values transparency, collaboration, and a data-driven approach to system understanding. In a DevOps environment, where the lines between development and operations are blurred, observability acts as a unifying force, empowering teams to collectively own and improve the system’s performance and reliability.
Empowering Teams with Self-Service Insights
A key tenet of a strong observability culture is empowering teams with the ability to access and analyze system data themselves. This “self-service” approach reduces reliance on specialized SRE or operations teams for every data request.
Democratizing Access to Data
Observability platforms should provide intuitive interfaces and query languages that allow developers and operators across different teams to easily explore logs, metrics, and traces relevant to their services. This democratizes access to critical system information, fostering a sense of ownership.
Fostering a Culture of Inquiry
When teams have easy access to data, they are more likely to ask questions about their system’s behavior. This encourages a proactive culture of inquiry, where engineers are constantly seeking to understand the “why” behind observed phenomena, rather than just reacting to alarms.
Integrating Observability into the Development Lifecycle
Observability should not be an afterthought; it needs to be woven into the fabric of the entire development lifecycle, from design and development to deployment and ongoing operation.
Design for Observability
When designing new services or features, teams should consider how they will be observable. This involves instrumenting code to emit relevant logs, metrics, and traces from the outset. Thinking about observability during the design phase can prevent significant challenges later on.
Continuous Testing and Validation
Observability data can be used to continuously validate the performance and reliability of applications in pre-production environments. By observing the behavior of new deployments under load, teams can catch potential issues before they reach production.
Automated Remediation and Self-Healing Systems
Advanced observability can enable the development of self-healing systems. By automatically detecting anomalies and triggering predefined remediation actions (e.g., restarting a service, scaling up resources), systems can become more resilient and reduce the burden on human operators.
The Evolution of Observability: Beyond Traditional Monitoring
While observability builds upon the foundations of traditional monitoring, it represents a significant evolution in how we understand and manage complex systems. Traditional monitoring often focuses on predefined metrics and threshold-based alerting, aiming to answer “is the system up or down?” and “is it performing within acceptable limits?”. Observability, on the other hand, seeks to answer more nuanced questions: “why is the system behaving this way?”, “what is the impact of this change?”, and “how can we prevent this issue from happening again?”.
From “Can We See It?” to “Can We Understand It?”
The shift is from simply being able to “see” data to being able to “understand” it in context. This involves more sophisticated analysis, correlation of disparate data sources, and the ability to explore unknown unknowns.
The Role of AI and Machine Learning
Artificial intelligence and machine learning are playing an increasingly important role in advancing observability. These technologies can automate the detection of anomalies, predict potential failures, and even suggest optimal remediation steps, significantly reducing the cognitive load on human operators.
A Continuous Journey
Observability is not a static state but a continuous journey of improvement. As systems evolve and become more complex, so too must our approaches to understanding them. By embracing observability, DevOps teams can navigate the complexities of modern software development with greater confidence, ensuring the delivery of reliable, performant, and resilient applications.