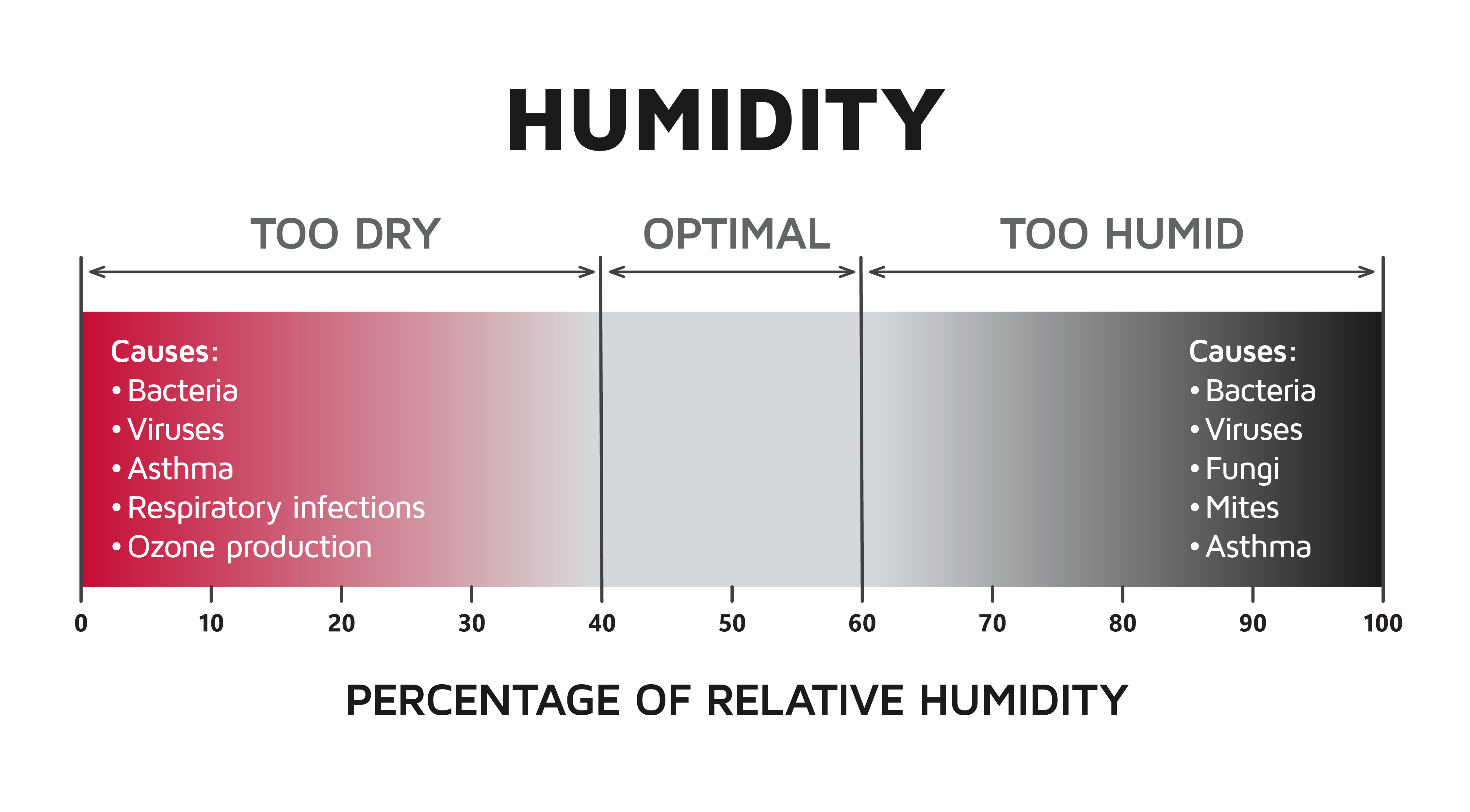
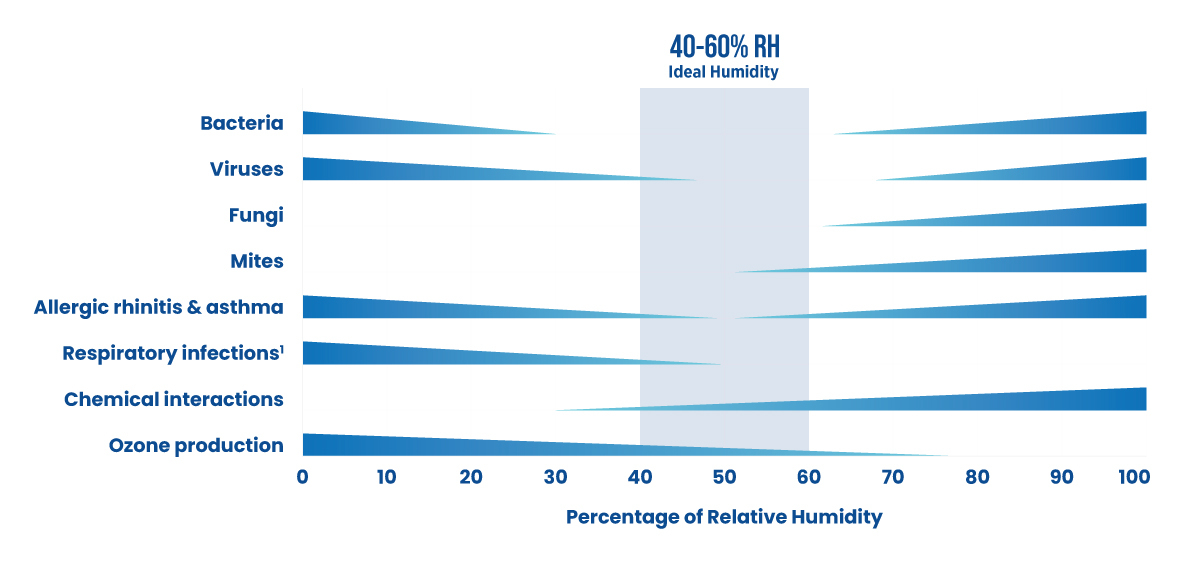
The concept of “normal” is a foundational pillar in human understanding, providing a baseline against which we measure, assess, and predict. In the context of a house, “normal humidity” refers to a well-understood range of atmospheric moisture that ensures comfort, health, and structural integrity. However, as we venture into the complex and rapidly evolving landscape of advanced technology and artificial intelligence, the very definition of “normal performance” becomes a far more nuanced and dynamic concept. Unlike the relatively stable environmental factors of a home, autonomous systems and AI operate in environments characterized by constant change, learning, and interaction. This article delves into what “normal” truly means for these cutting-edge systems, exploring the metrics, adaptive mechanisms, and inherent challenges in establishing such a critical benchmark.
The Evolving Definition of “Normal” in Autonomous Tech
The traditional notion of “normal” often implies a fixed, predictable state or a narrow range of acceptable parameters. For advanced tech and AI, particularly systems designed for autonomous operation, this static view quickly breaks down. Their inherent ability to learn, adapt, and operate in highly variable environments necessitates a flexible and dynamic understanding of what constitutes typical, expected, or optimal performance.
Beyond Static Benchmarks
Traditional benchmarking, while valuable for initial comparisons and validation, struggles to capture the full spectrum of “normal” for intelligent systems. A fixed benchmark might evaluate a system’s accuracy on a pre-defined dataset, but it rarely accounts for real-world environmental shifts, novel situations, or the system’s own learning over time. For an autonomous vehicle, “normal” performance isn’t just about consistently staying within lane markings in perfect weather; it encompasses safe navigation in diverse traffic, varying light conditions, and unexpected obstacles. The “normal state” is not a singular point but a probabilistic distribution of acceptable behaviors and outcomes across a vast array of scenarios. This requires a shift from fixed, pass/fail metrics to continuous performance monitoring against adaptive thresholds.
Contextual Normalcy
One of the most critical aspects of defining “normal” in advanced tech is its inherent contextual dependency. What is considered normal for a robotic arm on an assembly line – precise, repetitive movements with minimal deviation – is vastly different from “normal” for an AI-driven medical diagnostic tool, which might involve probabilistic reasoning and interaction with human experts. The operating environment plays a crucial role: an autonomous drone’s “normal” flight performance in a calm, open field is incomparable to its “normal” operation amidst urban canyons with GPS interference and dynamic wind patterns. Similarly, the “normal” data throughput for a cloud-based AI serving millions of users is different from that of an edge AI processing sensor data locally. Understanding the specific application, operational objectives, and environmental constraints is paramount to establishing relevant performance norms.

Baseline Establishment through Data
Before deployment, and continuously thereafter, the initial and evolving “normal” operating parameters for AI and autonomous systems are established through extensive data analysis. Vast datasets, often collected from simulations and real-world trials, are used to train machine learning models and define statistical baselines. This includes identifying typical sensor readings, control inputs, system responses, and expected outputs under various conditions. Statistical methods, such as mean and standard deviation, are applied to these data streams to delineate what falls within an acceptable range, forming the foundational understanding of the system’s initial “normal” behavior. As systems accumulate more operational data, these baselines are refined and updated, allowing for more precise definitions of normal and more accurate detection of deviations.
Key Performance Indicators (KPIs) for Autonomous System Evaluation
To objectively assess and manage “normal performance,” a robust set of Key Performance Indicators (KPIs) is indispensable. These metrics provide measurable insights into various facets of a system’s operation, allowing developers, operators, and regulators to understand if the system is behaving as expected within its designated “normal” parameters.
Accuracy and Precision
For many advanced tech systems, especially those involved in perception, classification, and control, accuracy and precision are paramount. Accuracy refers to how close a measurement or output is to its true value (e.g., an AI vision system correctly identifying an object), while precision refers to the consistency or repeatability of those measurements (e.g., the system consistently identifying the same object correctly under similar conditions). What constitutes “normal” accuracy varies significantly. A financial fraud detection AI might aim for 99.9% accuracy to minimize false positives and negatives, while a robotic vacuum cleaner might have a “normal” object avoidance accuracy of 90%. Understanding the acceptable error margins defines the boundaries of normal for these critical functions.
Latency and Responsiveness
The speed at which an autonomous system processes information and reacts to its environment is crucial, especially in real-time applications. Latency refers to the delay between an input and a corresponding output, while responsiveness measures the system’s ability to react quickly and appropriately. For critical systems like autonomous vehicles or surgical robots, “normal” latency must be in milliseconds to ensure safety and efficacy. In contrast, an AI analyzing long-term climate data might have a “normal” processing latency measured in hours. Defining normal responsiveness involves not just raw speed but also the appropriateness and timeliness of the action taken, ensuring the system operates within its temporal design constraints.
Reliability and Robustness
Reliability gauges a system’s ability to consistently perform its intended function without failure over a specified period. Robustness, on the other hand, measures its capacity to maintain performance despite perturbations, errors, or unexpected inputs. A “normal” level of reliability might be expressed as an uptime percentage (e.g., 99.999% for critical infrastructure AI) or a Mean Time Between Failures (MTBF). For robustness, “normal” entails the system’s ability to gracefully degrade performance rather than catastrophically fail, or its resilience to certain levels of noise or adversarial attacks. A system operating normally should exhibit predictable behavior even when pushed to the edge of its design limits.
Efficiency and Resource Utilization
As advanced tech systems become more complex, their efficiency in utilizing resources – computational power, energy, memory, and bandwidth – becomes a critical aspect of “normal” operation. An AI model that consumes excessive energy for a routine task or requires an unnecessarily large amount of memory might be considered operating abnormally, even if it produces correct outputs. “Normal” efficiency often translates to operating within predefined power envelopes, maintaining optimal CPU/GPU usage, and minimizing data transfer to reduce costs and environmental impact. For edge AI devices, strict efficiency metrics are often part of their fundamental design, and deviation signifies a problem.
Scalability and Adaptability
Scalability refers to a system’s ability to handle an increasing workload or expand its capacity without significant performance degradation. Adaptability describes its capability to adjust to new environments, data types, or operational requirements. A system performing “normally” should be able to scale up its operations (e.g., an AI-driven platform accommodating more users) or adapt to minor changes (e.g., a vision system handling new lighting conditions) without requiring a complete overhaul or experiencing a drop in its core KPIs. The ability to gracefully evolve and grow within expected parameters is a hallmark of robust, well-designed normal performance.
Adaptive Normalcy: Learning, Calibration, and Self-Correction
The true intelligence of advanced tech lies in its capacity to move beyond static definitions of “normal” and embrace an adaptive, dynamic understanding. This continuous evolution is critical for maintaining optimal performance in ever-changing real-world environments.
Machine Learning for Dynamic Baselines
Unlike fixed systems, AI-powered autonomous entities continuously learn from their interactions with the environment and their own operational data. This learning process dynamically refines and redefines their “normal” operational baselines. Machine learning algorithms, particularly those involved in anomaly detection, constantly analyze real-time data streams to identify patterns and statistical regularities. As the system accumulates experience, these algorithms can subtly shift the boundaries of what is considered “normal,” making the system more nuanced in its understanding of its own performance and environment. For instance, an AI managing energy consumption in a smart building might learn seasonal variations and adjust its “normal” energy profile accordingly.
Continuous Calibration and Fine-Tuning
Autonomous systems are often equipped with self-calibration mechanisms that allow them to make minor adjustments to their parameters to maintain optimal performance. This continuous fine-tuning ensures that they stay within their desired “normal” operating window. For example, a navigation system might continuously calibrate its sensors against known landmarks to correct for drift, or a robotic manipulator might adjust its grip strength based on feedback from tactile sensors. These ongoing, often imperceptible, adjustments are essential for preventing performance degradation and ensuring the system consistently operates within its expected normal range, even as components age or environments shift.
Anomaly Detection and Deviation from Normal
The ability to accurately detect when a system deviates from its established normal state is paramount for safety, security, and reliability. Anomaly detection systems are a core component of advanced tech, employing statistical models, machine learning, and rule-based logic to flag unusual patterns or events. These deviations can signal anything from a sensor malfunction, a software bug, an environmental anomaly (e.g., sudden weather change), or even a malicious attack. By identifying these departures from “normal,” autonomous systems or their human operators can trigger alarms, initiate diagnostic routines, or activate fail-safes. Thus, “normal” becomes not just a descriptive state but a critical diagnostic tool, highlighting when intervention is required to restore optimal operation.
Challenges in Standardizing “Normal” Performance
Despite the sophistication of modern AI and autonomous systems, establishing universal, standardized definitions of “normal performance” remains a formidable challenge. The inherent complexities of the technology and its diverse applications create significant hurdles.
Data Heterogeneity and Bias
The definition of “normal” for any AI system is fundamentally dependent on the data it is trained on. If the training data is heterogeneous – meaning it comes from various, often inconsistent sources – or contains inherent biases, the system’s learned “normal” behavior can be skewed. For instance, an AI trained predominantly on data from one demographic or geographic region might perform abnormally when deployed in another. Ensuring that datasets are comprehensive, representative, and free from biases is a monumental task, and the failure to do so can lead to systems whose “normal” operation is inequitable, inefficient, or even dangerous in certain contexts.
Environmental and Operational Variability
The real world is messy and unpredictable. Autonomous systems operate in a vast array of environments – from controlled factory floors to chaotic urban jungles, from the vacuum of space to the depths of the ocean. Each environment presents unique challenges, variables, and unforeseen circumstances that can impact performance. Weather conditions, network interference, unexpected human interaction, and dynamic obstacles are just a few examples. Establishing a “normal” that encompasses such immense variability, allowing for consistent performance across these diverse conditions, is incredibly complex. What might be an anomaly in one environment could be perfectly normal in another, making universal standardization difficult without extensive contextualization.
The “Black Box” Problem and Interpretability
Many advanced AI models, particularly deep neural networks, are often referred to as “black boxes” due to the difficulty in understanding their internal decision-making processes. While they can achieve impressive results, it can be challenging to ascertain why a particular decision was made or how a specific output was generated. This lack of interpretability poses a significant challenge when defining “normal” behavior. If we cannot fully explain the steps leading to an outcome, it becomes harder to verify if the “normal” operation aligns with ethical principles, safety requirements, or intended design. This opacity hinders trust and makes it difficult to diagnose subtle deviations from expected behavior.
Security and Adversarial Attacks
The “normal” operating parameters of advanced tech systems are constantly under threat from malicious actors. Adversarial attacks aim to subtly manipulate inputs to force an AI system to make incorrect classifications or behave abnormally, often without triggering standard anomaly detection. For instance, imperceptible changes to an image could cause a self-driving car’s vision system to misidentify a stop sign. Defining “normal” performance must therefore include resilience against such attacks. This requires continuous research into defensive measures and dynamic security protocols, as the nature of these threats is constantly evolving, challenging any static definition of a secure “normal.”
The Future of Performance Standards and AI Governance
As advanced tech and AI become increasingly ubiquitous and impactful, the need for robust, dynamic, and ethical definitions of “normal performance” becomes paramount. This future will involve a blend of technological innovation, industry collaboration, and thoughtful governance.
Towards Industry Standards and Regulations
The proliferation of AI across critical sectors – from healthcare and finance to transportation and defense – underscores the urgent need for industry-wide standards and regulatory frameworks. These efforts aim to define acceptable performance benchmarks, testing methodologies, and accountability mechanisms. Organizations globally are working to establish guidelines for AI safety, robustness, transparency, and fairness. While a universally static “normal” may never be fully achievable, these standards will help define a baseline of expected, responsible, and ethical performance, ensuring that AI systems contribute positively to society and operate within agreed-upon boundaries.
AI Explainability (XAI) and Trust
The “black box” problem is being actively addressed through the development of Explainable AI (XAI). XAI aims to create systems that can articulate their decision-making processes in a human-understandable way. By providing insights into the “why” behind an AI’s actions, XAI will significantly enhance trust and allow operators to verify if the system’s “normal” operation is indeed logical, ethical, and aligned with its objectives. Transparent “normal” behavior will enable quicker diagnosis of issues, facilitate regulatory compliance, and foster greater confidence in autonomous systems.
Human-in-the-Loop and Oversight
Despite the advancements in autonomy, the role of human oversight and intervention remains critical, particularly for high-stakes applications. A “human-in-the-loop” approach ensures that operators can monitor system performance, intervene when deviations from “normal” occur, and make executive decisions when faced with unprecedented situations. This collaborative model acknowledges that while AI can excel at complex tasks, human judgment, ethical reasoning, and adaptability are still indispensable. Defining “normal” performance in this context also means defining the appropriate level and timing of human intervention.
Proactive Performance Monitoring
The evolution of performance monitoring tools is moving beyond reactive anomaly detection towards proactive prediction. Future systems will leverage predictive analytics and advanced statistical modeling to anticipate potential deviations from “normal” before they manifest as critical failures. By identifying subtle trends or precursor indicators, systems can self-correct or alert operators to impending issues, thereby ensuring continuous “normal” operation and maximizing uptime. This proactive approach will be essential for managing the complexity and ensuring the reliability of future AI and autonomous deployments.
In conclusion, defining “normal performance” in advanced tech and AI systems is a dynamic, multi-faceted challenge, starkly contrasting the stable parameters of a “normal humidity in a house.” It requires a sophisticated understanding of adaptive baselines, comprehensive KPIs, continuous learning, and robust anomaly detection. While significant hurdles remain in standardizing this concept, ongoing innovation in AI explainability, coupled with collaborative efforts in establishing industry standards and integrating human oversight, is paving the way for a future where the “normal” operation of intelligent systems is synonymous with reliability, safety, efficiency, and ethical responsibility. As these technologies continue to evolve, so too must our understanding and management of what it means for them to perform “normally.”