In the ever-evolving landscape of artificial intelligence and machine learning, a fundamental algorithm that underpins many sophisticated applications is K-Means clustering. While its name might sound technical, its core concept is remarkably intuitive and powerful. K-Means is an unsupervised machine learning algorithm, meaning it learns from data without explicit labels or predefined categories. Its primary function is to partition a dataset into a specified number of distinct groups, or “clusters,” such that data points within the same cluster are more similar to each other than to data points in other clusters. This ability to discover inherent structures and patterns within data makes K-Means an indispensable tool across a vast array of technological domains, including the advanced field of drone technology.
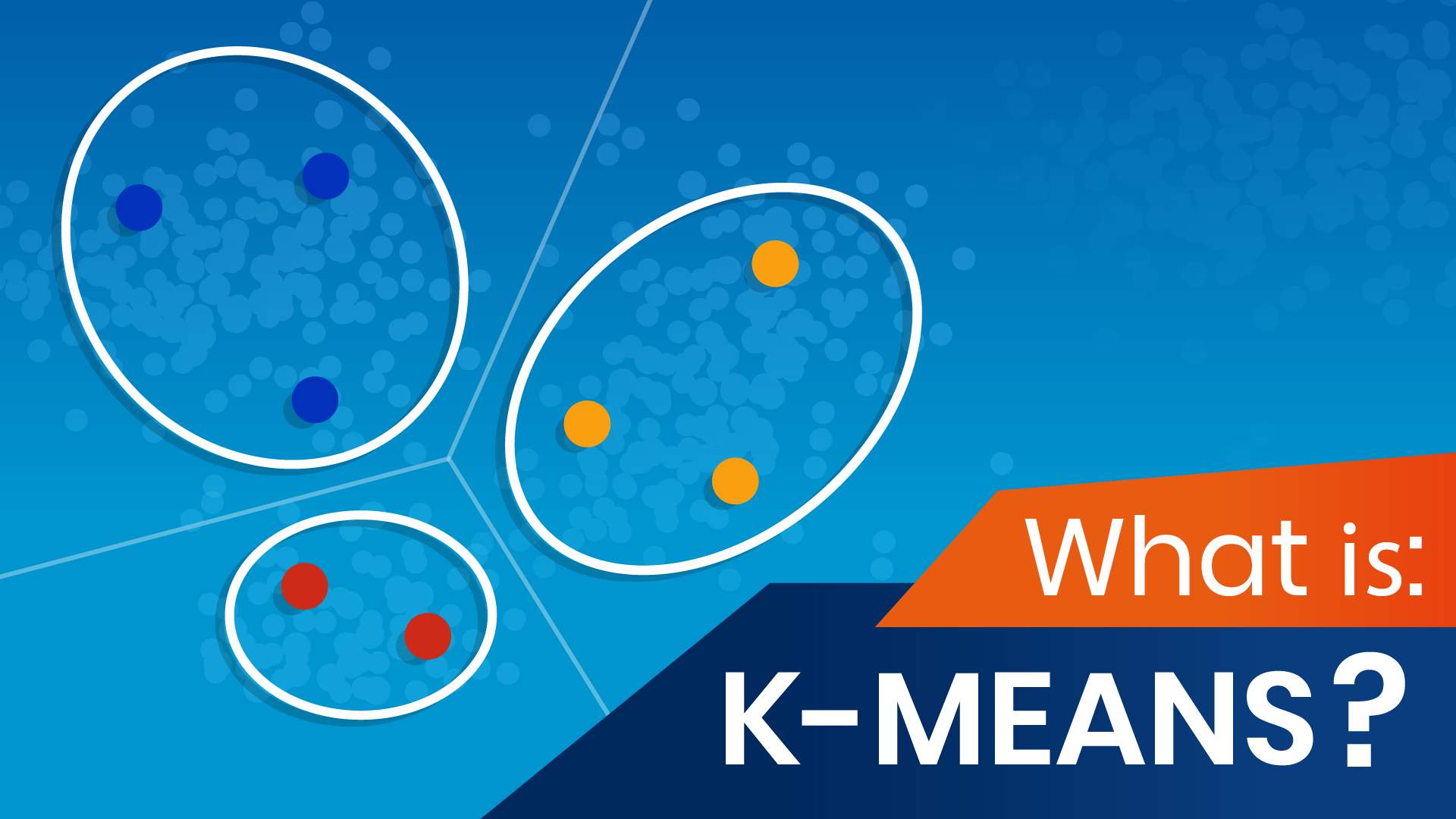
Understanding the Core Mechanics of K-Means Clustering
At its heart, K-Means clustering operates on a simple yet effective principle of iteratively assigning data points to centroids (cluster centers) and then recalculating those centroids based on the assigned points. This process is repeated until the assignments and centroids stabilize, indicating that the algorithm has converged to a satisfactory solution. The “K” in K-Means refers to the pre-defined number of clusters that the user specifies before the algorithm begins its execution. The choice of “K” is crucial and often requires domain knowledge or empirical testing to determine the optimal number of groupings for a given dataset.
The Iterative Assignment and Update Process
The K-Means algorithm commences by randomly initializing “K” centroids within the data space. These initial centroids serve as the starting points for each cluster. Subsequently, two primary steps are performed iteratively:
-
Assignment Step: Each data point in the dataset is assigned to the nearest centroid. The “nearest” is typically determined by calculating the Euclidean distance between the data point and each centroid. The data point is then associated with the centroid that has the minimum distance.
-
Update Step: Once all data points have been assigned to a centroid, the position of each centroid is recalculated. The new centroid position is the mean of all the data points that were assigned to that particular cluster. This step effectively moves the centroid to the center of its newly formed cluster.
These two steps are repeated. With each iteration, data points might shift their cluster assignments as the centroids move. This iterative refinement allows the algorithm to converge towards a state where the sum of squared distances between data points and their assigned centroids (often referred to as the within-cluster sum of squares, or inertia) is minimized. The algorithm terminates when either a maximum number of iterations is reached or when the centroids no longer move significantly between iterations, indicating convergence.
The Role of Centroids and Distance Metrics
Centroids are the defining points of each cluster. They represent the “average” location of all data points within that cluster. The quality of the clustering heavily relies on the accurate identification of these centroids. The choice of distance metric is also paramount. While Euclidean distance is the most commonly used, other distance metrics like Manhattan distance or cosine similarity can be employed depending on the nature of the data and the desired measure of similarity. For instance, if the data represents features where the absolute differences are not as important as the relative differences, cosine similarity might be more appropriate.
Determining the Optimal Value of ‘K’
One of the significant challenges in using K-Means is deciding on the optimal number of clusters, “K.” An inappropriate choice of “K” can lead to suboptimal clustering results, either by over-segmenting the data into too many small, insignificant clusters or by under-segmenting it into too few, overly broad clusters that fail to capture meaningful distinctions. Several methods are employed to address this:
-
The Elbow Method: This is a widely used heuristic. It involves running K-Means clustering for a range of “K” values and calculating the within-cluster sum of squares (inertia) for each “K.” The inertia generally decreases as “K” increases. The “elbow” in the plot of inertia versus “K” (where the rate of decrease sharply changes) is often considered the optimal value for “K,” as it represents a point of diminishing returns.
-
The Silhouette Score: This method measures how similar an object is to its own cluster (cohesion) compared to other clusters (separation). The silhouette score ranges from -1 to +1. A higher silhouette score indicates better-defined clusters. The “K” that yields the highest average silhouette score is often chosen.
-
Gap Statistic: This method compares the total within-cluster variation for different values of “K” with their expected values under a null reference distribution of data. The “K” that maximizes the gap statistic is considered the best choice.
K-Means Clustering in the Context of Drone Technology
The principles of K-Means clustering find profound applications within the realm of drone technology, particularly in enhancing their operational capabilities and data processing. Drones, as sophisticated aerial platforms, generate vast amounts of data from their sensors and cameras. Organizing, analyzing, and making sense of this data is critical for their efficient and intelligent deployment. K-Means plays a vital role in transforming raw data into actionable insights.
1. Environmental Mapping and Scene Understanding
Drones equipped with advanced sensors, such as LiDAR or high-resolution cameras, are increasingly used for detailed environmental mapping and scene understanding. K-Means clustering can be applied to the point cloud data generated by LiDAR or image features extracted from camera feeds to segment different objects or surfaces.
a. Object Segmentation and Classification
When a drone surveys an area, it might capture data that includes various entities like trees, buildings, vehicles, or even individuals. K-Means can cluster similar features in the data, allowing for the automatic identification and segmentation of these objects. For example, by clustering points with similar elevation and density from LiDAR data, distinct tree canopies can be separated from ground surfaces or building structures. Similarly, in image analysis, K-Means can group pixels with similar color and texture characteristics to identify and delineate objects. This is crucial for tasks like inventory management in agriculture, infrastructure inspection, or search and rescue operations, where precise identification of specific entities is required.

b. Land Cover Classification
In agricultural drones or those used for environmental monitoring, K-Means can facilitate land cover classification. By clustering spectral signatures from multispectral or hyperspectral imagery, areas of different crop types, soil types, or water bodies can be automatically distinguished. This allows for precise crop health monitoring, irrigation management, and the assessment of ecological changes over time. The algorithm groups pixels with similar spectral reflectance values, effectively creating thematic maps that differentiate between various land cover classes without prior labeling.
2. Flight Path Optimization and Autonomous Navigation
While not directly dictating the how of navigation (which involves complex control systems), K-Means can contribute to the strategic planning and optimization of drone flight paths, especially in complex environments or for specific mission objectives.
a. Identifying Navigation Zones and Waypoints
For missions requiring extensive coverage of an area, such as aerial surveys or inspections, K-Means can help identify distinct zones or areas of interest within the operational environment. By clustering spatial data points representing potential flight areas or operational requirements, the algorithm can help define optimal regions for drone activity. This can then inform the generation of efficient flight paths that cover these clustered zones systematically. For instance, in infrastructure inspection, K-Means could cluster areas of a bridge that require detailed examination, thereby informing a more focused and efficient flight plan.
b. Anomaly Detection for Navigation Adjustments
In dynamic environments, K-Means can be used in conjunction with sensor data to detect anomalies that might require navigation adjustments. For example, if a drone is performing autonomous flight in an urban setting, sensor data (e.g., radar, lidar) could be clustered to identify normal environmental patterns. Any deviation from these learned patterns, such as the unexpected appearance of an object or a change in ground elevation, could be flagged as an anomaly. This allows the drone to either adapt its path, trigger a safety protocol, or alert the operator, contributing to safer and more robust autonomous navigation.
3. Data Analysis and Feature Extraction for Drone Payloads
Drones often carry specialized payloads, such as thermal cameras or high-zoom optical cameras, which generate rich datasets. K-Means can be instrumental in processing and extracting meaningful features from this data.
a. Thermal Imaging Analysis
Thermal cameras on drones are used for applications like inspecting electrical equipment for hotspots, monitoring building insulation, or detecting wildlife. K-Means can cluster thermal signatures, allowing for the identification of areas with significantly different temperature profiles. This helps in pinpointing anomalies, such as overheating components in a power line or areas of heat loss in a building, by grouping pixels with similar temperature readings and then identifying clusters that deviate from the expected background temperature.
b. Visual Quality Assessment and Image Segmentation
For drones used in aerial photography or videography, K-Means can assist in analyzing image quality and segmenting scenes for post-processing. By clustering image regions based on color, brightness, or texture, it can help identify areas that might require specific editing techniques or that represent distinct elements within a scene. For instance, it could help in separating the sky, ground, and foreground elements in a cinematic shot, facilitating targeted color grading or effects. This capability aids in automated content analysis and can streamline the production pipeline for aerial footage.
Advantages and Limitations of K-Means in Drone Applications
Like any algorithm, K-Means clustering presents a set of benefits and drawbacks that are important to consider when applying it to drone-related tasks. Understanding these nuances ensures that the algorithm is used effectively and its limitations are mitigated.
Benefits of Using K-Means
The simplicity and efficiency of K-Means make it an attractive choice for real-time or near-real-time processing of data generated by drones. Its computational cost is relatively low, especially compared to more complex clustering algorithms, which is a significant advantage when dealing with the continuous stream of data from a flying platform. Furthermore, its interpretability is a strong point; the centroids provide clear representatives of each cluster, making the results of the clustering relatively easy to understand and validate. When the data exhibits clear, spherical, and well-separated clusters, K-Means tends to perform exceptionally well, providing accurate segmentation and grouping. This makes it ideal for tasks where distinct categories of data are expected.
Challenges and Considerations
Despite its advantages, K-Means is not without its challenges. A primary limitation is its sensitivity to the initial placement of centroids. Different initializations can lead to different clustering results, meaning that running the algorithm multiple times with different random seeds is often recommended to improve the chances of finding a globally optimal solution. As mentioned earlier, the need to pre-define the number of clusters (“K”) is a significant hurdle. If the underlying data does not naturally lend itself to a specific number of distinct groups, or if the optimal “K” is difficult to determine, the resulting clustering might not be meaningful. K-Means also assumes that clusters are spherical and equally sized, which may not always be the case with real-world drone data. Irregularly shaped clusters or clusters with varying densities can lead to poor performance. Outliers can also disproportionately influence the position of centroids, leading to biased cluster assignments. Therefore, preprocessing steps to handle outliers are often necessary.
Conclusion: The Enduring Relevance of K-Means for Smarter Drones
K-Means clustering, with its straightforward yet powerful approach to data segmentation, has cemented its place as a foundational algorithm in machine learning. Its ability to uncover latent structures and group similar data points makes it an exceptionally valuable tool in the rapidly advancing field of drone technology. From enhancing environmental mapping and scene understanding through object segmentation and land cover classification, to optimizing flight paths by identifying navigation zones, and extracting crucial insights from payload data like thermal imagery, K-Means is quietly powering many of the intelligent functionalities that define modern drones.
While its limitations, such as sensitivity to initialization and the need to pre-determine the number of clusters, require careful consideration and often complementary techniques, the inherent efficiency and interpretability of K-Means ensure its continued relevance. As drone capabilities expand, demanding more sophisticated data processing and autonomous decision-making, algorithms like K-Means will remain essential building blocks, contributing to the development of smarter, more capable, and more impactful unmanned aerial systems. Its role in transforming raw sensor and image data into actionable intelligence underscores its significance in unlocking the full potential of drone technology for a wide array of industries and applications.