In the vast and ever-evolving landscape of technology and innovation, the ability to store, retrieve, and manage data efficiently is paramount. From the lightning-fast operations of modern databases to the intricate logic powering artificial intelligence and machine learning algorithms, the underlying data structures play a critical role in determining performance, scalability, and overall system responsiveness. Among these foundational elements, the hashmap stands out as an indispensable tool, a workhorse for developers and a cornerstone of efficient data management. At its core, a hashmap (also known as a hash table, dictionary, or associative array) is a data structure that implements an associative array abstract data type, mapping keys to values. It offers a highly efficient way to retrieve a value associated with a given key, making it fundamental to countless applications across the digital spectrum. Understanding what a hashmap is, how it functions, and why it’s so widely adopted is essential for anyone diving deep into the mechanics of modern software and systems.
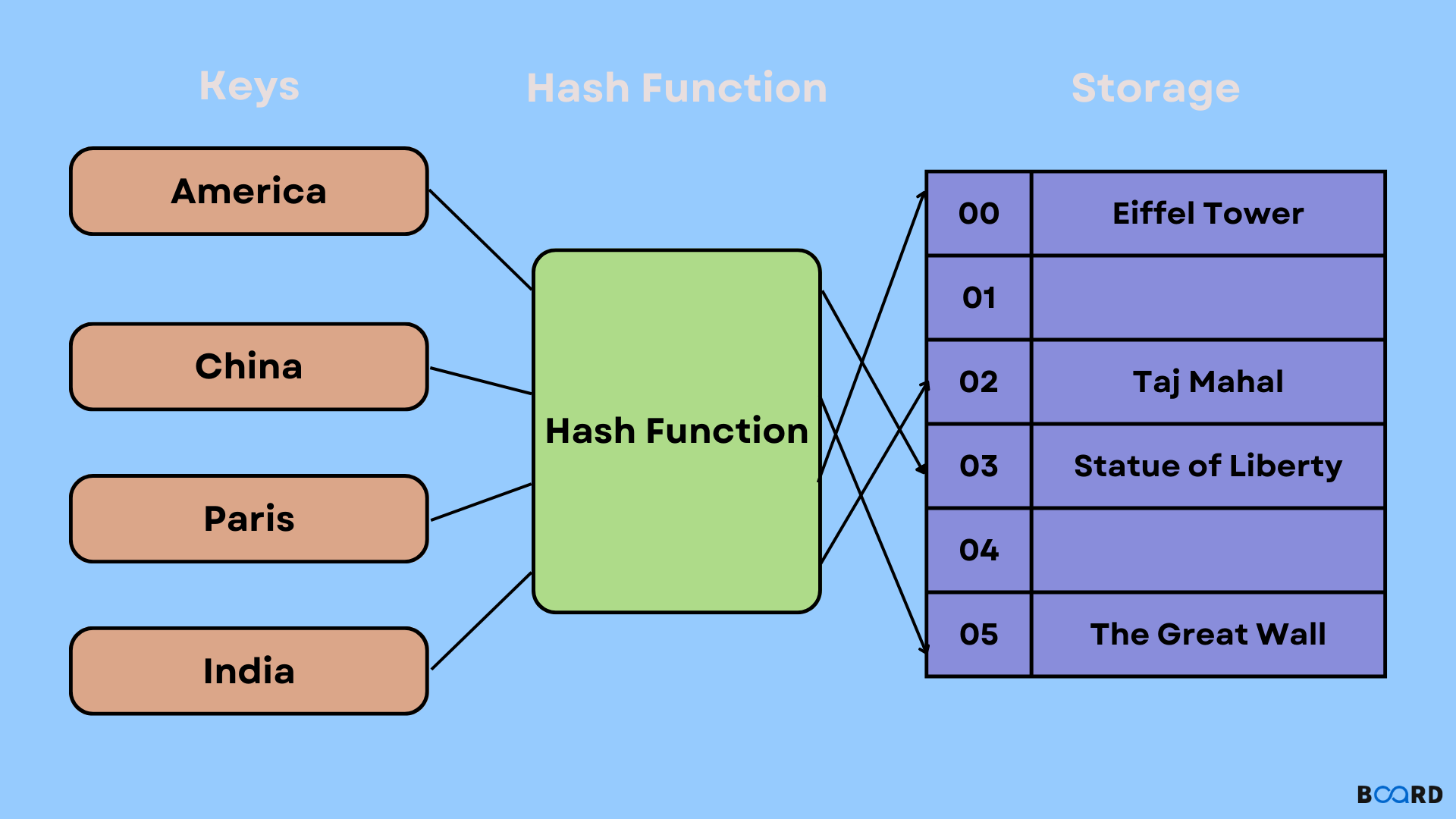
The Core Concept: Understanding Key-Value Storage
At the heart of every hashmap lies the principle of key-value storage. This paradigm is remarkably intuitive yet incredibly powerful, forming the basis for how data is organized and accessed within the structure.
What are Key-Value Pairs?
Imagine you have a collection of information where each piece of data (a “value”) is uniquely identified by a label (a “key”). For example, in a list of students, a student’s ID number (the key) might correspond to their full name, age, and grade (the value). In a hashmap, this relationship is formalized: every piece of data is stored as a key-value pair. The key must be unique, allowing for direct and unambiguous access to its associated value. This uniqueness is crucial; it ensures that when you ask the hashmap for the value associated with a specific key, there’s only one possible result. Keys can be of various data types, such as strings, integers, or even complex objects, as long as they can be uniquely hashed. Values, similarly, can be any data type, from simple numbers and strings to complex data structures themselves. This flexibility makes hashmaps incredibly versatile for storing diverse types of information.
The Analogy of a Dictionary
To further grasp the concept, consider the analogy of a physical dictionary or an encyclopedia. When you want to find the definition of a word, you don’t scan every page from beginning to end. Instead, you locate the word (the “key”) and then immediately find its definition (the “value”) next to it. The dictionary is organized in such a way that finding a word is very fast. A hashmap operates on a similar principle, but instead of alphabetical order, it uses a clever computational trick called “hashing” to directly jump to the location of the desired value. This direct access, facilitated by the key, is what gives hashmaps their characteristic speed and efficiency, distinguishing them from sequential search methods that might have to iterate through many items to find what they’re looking for.
How Hashmaps Work Under the Hood
The magic of a hashmap’s efficiency stems from its internal mechanics, particularly the role of the hash function and its strategies for handling data collisions. These components are what allow for near-instantaneous data retrieval, regardless of the hashmap’s size.
The Role of the Hash Function
The cornerstone of a hashmap’s operation is the hash function. When you provide a key to the hashmap (either to store or retrieve a value), the hash function takes that key as input and processes it to produce an integer, known as the hash code or hash value. This hash code is then typically mapped to an index within an underlying array (often called “buckets” or “slots”). The value associated with the key is then stored at this array index.
The goal of a good hash function is to distribute keys as evenly as possible across the array indices. An ideal hash function would generate a unique index for every unique key, thus avoiding “collisions” where two different keys produce the same hash code. In reality, perfect hash functions are rare and often impractical for dynamic data sets, leading to the necessity of collision resolution strategies. Despite this, a well-designed hash function aims to minimize collisions, ensuring that operations remain fast on average. Factors like key distribution, computational efficiency of the hash function itself, and sensitivity to small changes in input (avalanche effect) are critical considerations in its design.

Managing Collisions: Chaining vs. Open Addressing
Since collisions are an inherent part of hashmap operations, effective strategies are needed to resolve them. The two most common approaches are chaining and open addressing.
Chaining: Linked Lists in Buckets
Chaining is perhaps the most straightforward and widely used method for collision resolution. When two different keys hash to the same index (bucket), instead of overwriting existing data, a data structure capable of holding multiple items is placed at that index. Typically, this is a linked list. So, each bucket in the underlying array points to the head of a linked list. When a collision occurs, the new key-value pair is simply appended to the linked list at that bucket’s index.
To retrieve a value, the key is first hashed to find the correct bucket. Then, the linked list at that bucket is traversed until the specific key is found. While this introduces a linear search within the linked list, if the hash function distributes keys well, these linked lists remain short, keeping retrieval times very low on average. Chaining is relatively easy to implement and handles a high load factor gracefully.
Open Addressing: Probing for Space
Open addressing takes a different approach. Instead of storing multiple items at a single index, it attempts to find an alternative empty slot within the array itself when a collision occurs. This involves “probing” for the next available slot. There are several probing techniques:
- Linear Probing: If a slot is occupied, the algorithm simply checks the next consecutive slot (index + 1), then the next (index + 2), and so on, until an empty slot is found. This can lead to “primary clustering,” where long runs of occupied slots form, increasing search times.
- Quadratic Probing: To mitigate clustering, quadratic probing checks slots at increasingly larger quadratic offsets (index + 1^2, index + 2^2, index + 3^2, etc.). This helps distribute elements more evenly.
- Double Hashing: This sophisticated method uses a second hash function to determine the step size for probing. If the first hash function results in a collision, the second hash function generates an offset, which is repeatedly added to the initial index until an empty slot is found. This helps spread out elements even more effectively and reduces clustering.
The main advantage of open addressing is that it avoids the overhead of pointers associated with linked lists, which can lead to better cache performance. However, deleting items can be more complex, and it can suffer from performance degradation if the load factor (the ratio of occupied slots to total slots) becomes too high.
The Importance of Load Factor and Rehashing
The “load factor” is a critical metric for any hashmap. It is defined as the number of stored items divided by the total number of buckets. As the load factor increases, the probability of collisions rises, and the average length of linked lists (in chaining) or the probing sequence (in open addressing) grows. This directly impacts performance, shifting operations away from the desired O(1) constant time towards O(N) linear time in the worst-case scenario.
To maintain optimal performance, hashmaps often employ a mechanism called “rehashing” or “resizing.” When the load factor exceeds a certain threshold (e.g., 0.7 or 0.75), the hashmap creates a new, larger array of buckets (typically double the size). All existing key-value pairs are then rehashed using the same hash function and reinserted into the new, larger array. This process, while temporarily expensive (O(N) operation), ensures that the hashmap maintains a low average load factor, thus preserving its fast average-case performance for subsequent operations. Intelligent rehashing strategies are vital for building scalable and performant systems.
The Power of Efficiency: Why Hashmaps are Indispensable
The combination of an effective hash function and robust collision resolution strategies endows hashmaps with unparalleled efficiency for certain operations, making them a cornerstone of modern technological infrastructure.
Blazing Fast Operations: Average O(1) Performance
The primary appeal of hashmaps lies in their exceptional time complexity for fundamental operations: insertion, deletion, and retrieval. On average, these operations take O(1) constant time. This means that, regardless of whether the hashmap contains 10 items or 10 million items, the time required to perform these actions remains roughly the same. This constant-time performance is a game-changer for applications that demand quick data access, such as caches, databases, and real-time processing systems. While worst-case scenarios (e.g., all keys colliding due to a poor hash function or malicious input) can degrade performance to O(N), a well-implemented hashmap in typical scenarios provides near-instantaneous access, making it incredibly powerful for large datasets.
When Performance Matters: Real-World Applications
The theoretical efficiency of hashmaps translates into tangible performance benefits across a myriad of real-world applications within the tech and innovation sphere.
Caching Mechanisms for Speed
Caches are temporary storage areas that hold frequently accessed data to speed up subsequent requests. Hashmaps are perfectly suited for implementing caches because they allow for extremely fast lookups of cached items using a key (e.g., a URL, a user ID, or a database query). When a system needs data, it first checks the hashmap-backed cache. If the data is present (a “cache hit”), it’s retrieved in O(1) time, avoiding the slower process of fetching it from the original source (like a database or network request). This is critical for web servers, content delivery networks (CDNs), and application performance.
Database Indexing and Quick Lookups
Databases rely heavily on indexes to quickly locate specific records without scanning entire tables. Hash-based indexes are one form of indexing where a hashmap structure is used to map a column’s value (the key) to the physical location of the corresponding record in storage (the value). This allows for rapid retrieval of records based on exact match queries, significantly boosting query performance, especially in scenarios where unique identifiers are used for lookups.
Implementing Symbol Tables and Dictionaries
In programming languages, compilers, and interpreters, symbol tables are crucial data structures that store information about identifiers (like variable names, function names) and their attributes (like data type, scope). Hashmaps are the ideal choice for implementing symbol tables due to their fast lookup capabilities. When a compiler encounters an identifier, it can quickly check the symbol table (a hashmap) to retrieve its associated information. Similarly, the “dictionary” or “map” data types available in most modern programming languages (Python dict, Java HashMap, C++ std::unordered_map) are directly implemented using hashmaps, providing programmers with an efficient way to store and retrieve data by key.
Trade-offs and Considerations in Hashmap Design
While immensely powerful, hashmaps are not a one-size-fits-all solution. Their effective deployment requires careful consideration of various design choices and inherent trade-offs.
The Impact of a Poor Hash Function
The quality of the hash function is arguably the most critical factor influencing a hashmap’s performance. A poorly designed hash function that produces many collisions or distributes keys unevenly will severely degrade performance. In the worst case, all keys might hash to the same bucket, effectively turning the hashmap into a slow linked list (if chaining is used) or requiring extensive probing (if open addressing is used), thus losing the O(1) average-case benefit and falling back to O(N) performance. This vulnerability is also why hashmaps can be susceptible to “hash collision attacks” in security contexts, where an attacker intentionally crafts keys to cause many collisions, slowing down a server. Designing a robust, efficient, and collision-resistant hash function is a complex task requiring expertise in algorithm design and number theory.
Balancing Space and Time Complexity
Hashmaps inherently involve a trade-off between space and time complexity. To achieve their characteristic O(1) average-time performance, hashmaps typically require more memory space than some other data structures, such as sorted arrays or balanced binary search trees, which might offer O(log N) lookup times but use less memory. A larger array of buckets, while reducing collision probability and improving speed, consumes more memory. Conversely, a smaller array, while memory-efficient, increases collisions and degrades time performance. The optimal balance depends on the specific application’s requirements regarding memory constraints and performance demands. Rehashing, while crucial for performance, also introduces temporary peaks in memory usage and computational cost.
Memory Footprint and Overhead
Beyond the space for the buckets themselves, hashmaps incur additional memory overhead. In chaining, each node in the linked list requires memory for the key, value, and a pointer to the next node. In open addressing, while pointers are avoided, the array must often be significantly larger than the number of stored items to maintain low collision rates, leading to unused “empty” slots. This overhead can be substantial, especially for hashmaps storing a large number of small key-value pairs. Developers must consider this memory footprint, particularly in resource-constrained environments like embedded systems or mobile applications, where opting for a more memory-conservative data structure might be preferable, even if it means slightly slower average access times.
Hashmaps in the Broader Tech & Innovation Landscape
Hashmaps are not just theoretical constructs; they are fundamental building blocks that enable a vast array of modern technological advancements. Their efficiency and adaptability make them indispensable across various domains.
Enabling Efficient Data Management in AI and ML
In the fields of Artificial Intelligence and Machine Learning, where large datasets are the norm, hashmaps play a crucial role in efficient data management. They are used for:
- Feature Engineering: Mapping raw features to processed numerical representations.
- Vocabulary Management: In Natural Language Processing (NLP), mapping words to unique integer IDs for embedding layers, or storing word frequencies.
- Memoization: Caching the results of expensive function calls to avoid recomputing them, a common optimization technique in dynamic programming algorithms that are often at the core of AI systems.
- Graph Processing: Representing adjacency lists for sparse graphs, where fast lookups for connected nodes are essential.
The ability to quickly access and update vast amounts of data is critical for the performance of AI models, from training to inference, making hashmaps an invisible but vital component.
Foundation for Modern Software Systems
Beyond specialized AI applications, hashmaps underpin countless general-purpose software systems:
- Operating Systems: Managing process tables, file system caches, and resource allocation.
- Web Servers: Storing session data, user preferences, and routing information.
- Networking: Implementing routing tables, DNS caches, and protocol state.
- Version Control Systems: Indexing file content and metadata for fast lookups during operations like commit and diff.
- Compilers and Interpreters: As discussed, for symbol tables and optimizing code generation.
Essentially, any system that requires quick retrieval of data based on an identifier likely leverages a hashmap or a similar hash-based structure, solidifying its status as a foundational element of modern computing.
Looking Ahead: Optimizations and Quantum Computing Implications
The journey of hashmaps continues with ongoing research and optimization. Techniques like concurrent hashmaps are being developed to improve performance in multi-threaded environments, crucial for today’s parallel processing architectures. Furthermore, as quantum computing emerges, the principles of efficient data access and management, which hashmaps embody, will likely find new interpretations and challenges. While quantum algorithms might offer exponential speedups for certain problems, the need for effective data structuring to support these algorithms will remain, potentially leading to quantum-resistant hashing schemes or novel quantum-specific associative arrays. The fundamental concept of quickly mapping keys to values will endure, adapting to new computational paradigms and remaining a critical component in the technological innovations of the future.
In conclusion, the hashmap is far more than just an academic data structure; it is a powerful, efficient, and ubiquitous tool that silently fuels much of the modern digital world. Its elegant design for key-value storage, coupled with sophisticated hashing and collision resolution, provides the necessary speed and scalability for everything from the simplest programming tasks to the most complex AI systems. Understanding its intricacies is key to building robust, performant, and innovative technological solutions.