Firestore, a NoSQL cloud database offered by Google, stands as a powerful and flexible solution for modern application development. Its design prioritizes scalability, real-time data synchronization, and ease of use, making it a compelling choice for developers working across a wide spectrum of applications, from mobile and web to IoT and enterprise solutions. Unlike traditional relational databases, Firestore operates on a document-oriented model, offering a more dynamic and adaptable approach to data storage and retrieval.
The core of Firestore lies in its hierarchical data structure. Instead of tables and rows, Firestore utilizes collections and documents. Collections act as containers for documents, and documents themselves are JSON-like structures that hold fields and values. This organization allows for intuitive representation of complex data relationships, mirroring the way information is often structured in application logic. Furthermore, Firestore introduces the concept of subcollections, enabling nested data structures within documents, further enhancing the flexibility and expressiveness of the database. This tiered approach to organization is crucial for managing increasingly complex data sets efficiently.
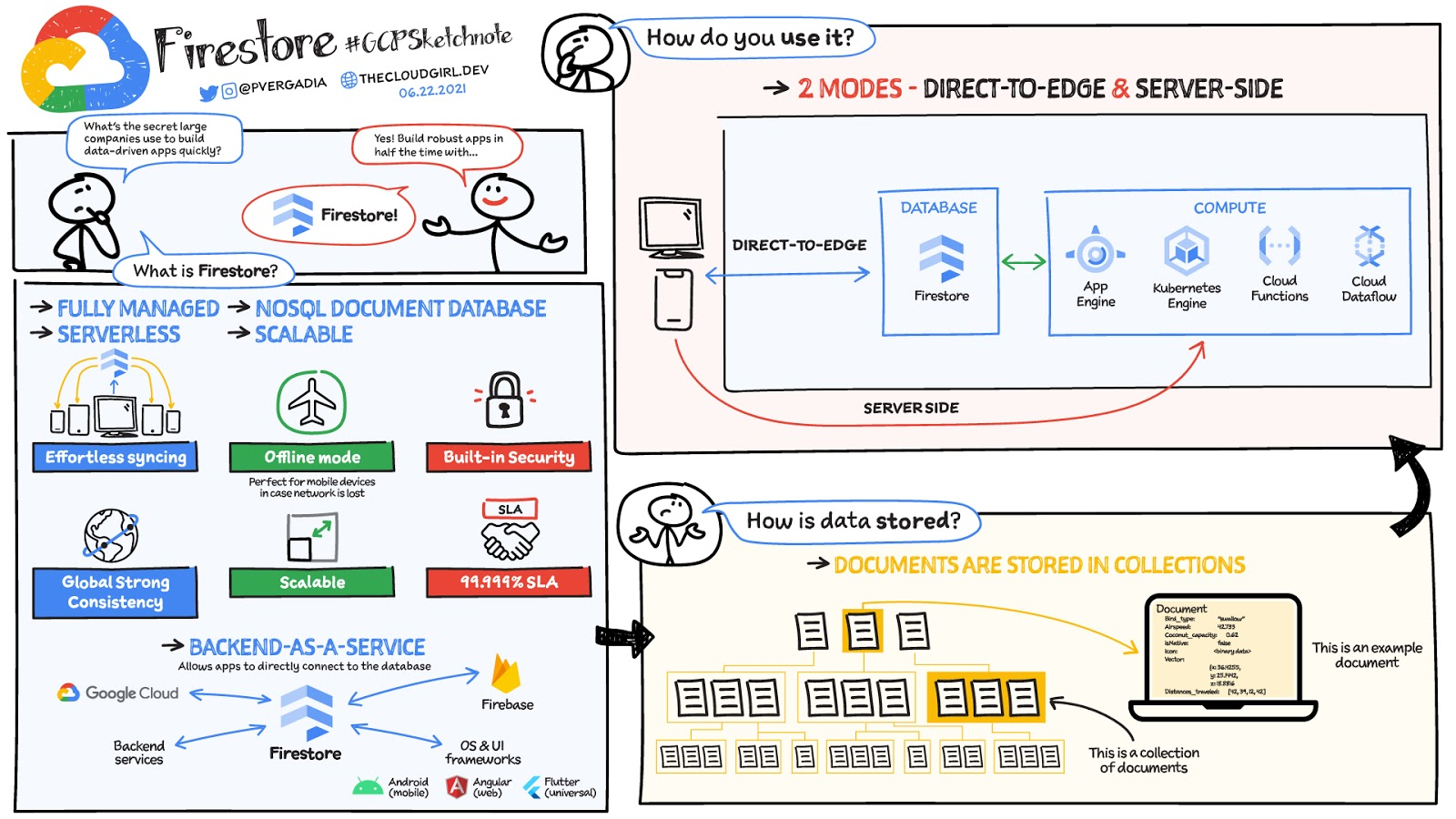
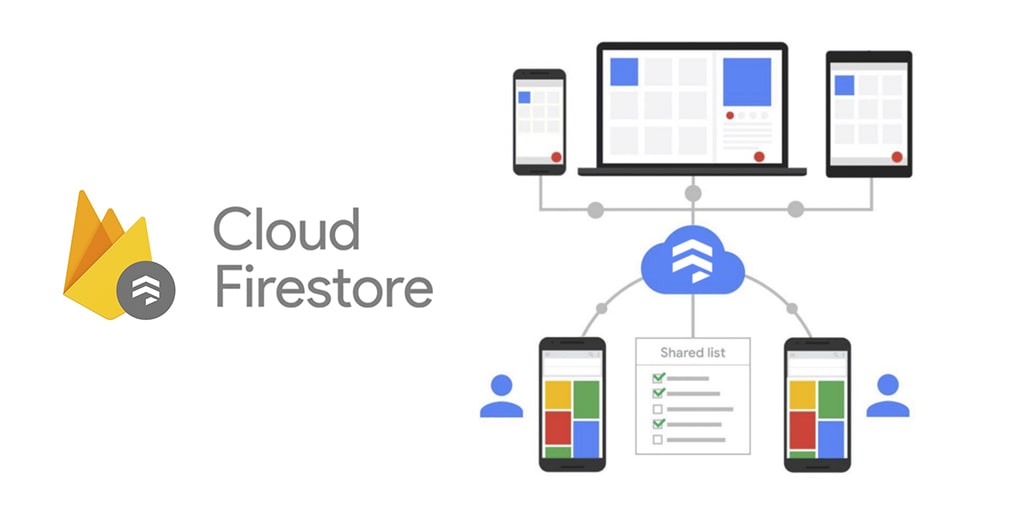
One of Firestore’s most significant advantages is its real-time synchronization capabilities. When data in Firestore changes, all connected clients that are actively listening to that data are automatically updated in real-time. This feature is a game-changer for applications requiring immediate feedback and dynamic user experiences, such as collaborative editing tools, live dashboards, or chat applications. Developers can leverage listeners to subscribe to changes in specific documents or collections, receiving instant updates without the need for constant polling, which significantly reduces server load and improves user responsiveness. This inherent real-time nature is a cornerstone of modern, interactive applications.
The platform’s scalability is another key differentiator. Firestore is built on Google Cloud’s infrastructure, designed to handle massive amounts of data and millions of concurrent users with seamless performance. It automatically scales to meet demand, eliminating the need for manual infrastructure management. This auto-scaling capability ensures that applications remain performant and available, even during periods of high traffic or rapid growth. Developers can focus on building features rather than worrying about database infrastructure, a significant boon for agile development teams.
Data Modeling in Firestore
The flexibility of Firestore’s data model is a primary driver of its adoption. Understanding how to effectively structure data is crucial for maximizing performance and minimizing costs.
Documents and Collections
At the most fundamental level, Firestore organizes data into documents. Each document is a unique record containing a set of key-value pairs, similar to a JSON object. Documents reside within collections, which are groups of related documents. For instance, a “users” collection might contain individual user documents, each with fields like “name,” “email,” and “creationDate.”
Subcollections
To further refine data organization and avoid overly large or complex documents, Firestore supports subcollections. A subcollection is a collection nested within a document. This allows for a more granular representation of relationships. For example, within a “user” document, you might have a “posts” subcollection, where each document in the “posts” subcollection represents a post created by that user. This hierarchical structure promotes better data partitioning and can improve query performance by allowing you to fetch specific subsets of related data.
Fields and Data Types
Firestore supports a variety of data types, including strings, numbers, booleans, timestamps, geo-points, arrays, and maps. This rich set of types allows for detailed and accurate representation of application data. For complex or nested data structures within a document, maps (similar to JSON objects) can be used. Arrays are suitable for lists of values. The choice of data type directly impacts how data is stored, queried, and indexed, making thoughtful schema design essential.
Denormalization and Performance
A key consideration when modeling data in Firestore is the concept of denormalization. While relational databases often emphasize normalization to reduce redundancy, Firestore encourages denormalization for performance gains, especially in read-heavy applications. This involves duplicating data across multiple documents or collections to enable faster, single-document reads. For example, if a user frequently needs to see a list of their recent posts along with their username, you might denormalize the username into each post document rather than requiring a separate lookup to the user document every time. This trade-off between data redundancy and read performance is a critical aspect of Firestore data modeling.
Real-time Data Synchronization and Listeners
The real-time capabilities of Firestore are arguably its most revolutionary feature, transforming how applications can interact with data.
How Real-time Works
Firestore establishes persistent, bidirectional connections with clients. When a change occurs to data that a client is “listening” to, Firestore pushes that update to the client almost instantaneously. This eliminates the need for clients to repeatedly poll the server for new data, significantly reducing latency and improving the user experience. This push-based model is central to building dynamic and responsive applications.
Implementing Listeners
Developers can implement listeners using client SDKs for various platforms (web, iOS, Android, etc.). These listeners can be attached to specific documents, queries, or even collections. When the data relevant to the listener is modified, deleted, or added, a callback function is invoked, providing the updated data or a snapshot of the current state. This allows applications to react dynamically to data changes, updating the UI or triggering other actions accordingly.
Offline Support
An essential companion to real-time synchronization is Firestore’s robust offline support. When a device goes offline, Firestore caches data locally. Applications can continue to read from and write to this cached data. Once the device regains connectivity, Firestore automatically synchronizes the local changes with the cloud, resolving any potential conflicts. This feature is critical for mobile applications and environments with intermittent network connectivity, ensuring a seamless user experience regardless of network status.
Use Cases for Real-time Data
The real-time nature of Firestore unlocks a wide array of application possibilities:
- Collaborative Editing: Multiple users can simultaneously edit a document, with changes reflected for everyone in real-time.
- Live Chat: Messages appear instantly for all participants in a conversation.
- Real-time Dashboards: Displaying live analytics, stock tickers, or sensor data that updates as it changes.
- Gaming: Synchronizing game states and player actions across multiple clients.
- Location-Based Services: Sharing and tracking real-time location data.
Scalability and Performance
Firestore’s architecture is engineered for extreme scalability and consistently high performance, crucial for applications expecting significant user growth or handling large datasets.
Google Cloud Infrastructure
Firestore is built upon Google Cloud’s robust and globally distributed infrastructure. This foundation provides inherent resilience, fault tolerance, and massive scalability. Google manages the underlying hardware and network, allowing developers to focus on their applications.
Automatic Scaling
One of Firestore’s key strengths is its automatic scaling. It can effortlessly handle billions of documents and millions of concurrent users without requiring manual intervention from developers. Whether your application experiences a sudden surge in traffic or a steady growth trajectory, Firestore adjusts its resources dynamically to maintain optimal performance. This eliminates performance bottlenecks and the complexities of manual scaling operations.
Read and Write Operations
Firestore is optimized for high-volume read and write operations. The document-oriented model, coupled with smart indexing, enables efficient data retrieval. Queries are indexed by default, and developers can create custom indexes to further optimize query performance for specific access patterns. Understanding these indexing mechanisms is vital for achieving peak performance.
Pricing and Cost Optimization
Firestore’s pricing is based on a consumption model, primarily driven by reads, writes, and data storage. To optimize costs, developers should carefully consider their data modeling and query strategies. Efficient data retrieval, minimizing unnecessary reads, and strategic use of denormalization can significantly impact the overall cost. Furthermore, utilizing Firestore’s query capabilities effectively and designing data structures that align with anticipated access patterns are essential for cost-effective operation. For instance, fetching only the necessary fields within a document rather than the entire document can lead to substantial savings in read operations.
Security and Access Control
Ensuring data security and controlling access to sensitive information is paramount in any application, and Firestore provides robust mechanisms to achieve this.
Security Rules
Firestore Security Rules are the cornerstone of its security model. These are declarative rules written in a custom rules language that specify how your data should be read, written, and deleted. They run on Google’s servers, ensuring that security is enforced at the database level, not just on the client. Rules can be configured to allow or deny access based on various conditions, including user authentication status, data within the document being accessed, or even the current time.
User Authentication
Firestore seamlessly integrates with Firebase Authentication, allowing you to secure your data based on authenticated user identities. You can define rules that grant different levels of access to authenticated users versus anonymous users, or even grant specific permissions based on user roles or attributes stored in their user profile documents.
Role-Based Access Control (RBAC)
By leveraging user authentication and custom data fields (e.g., a “role” field in user documents), you can implement sophisticated role-based access control. For example, an “admin” role might have full read/write access to all data, while a “regular user” might only be able to read and write their own data. This granular control ensures that users can only access the information they are authorized to see and modify.
Best Practices for Security
When designing Firestore security rules, it’s crucial to follow best practices:
- Principle of Least Privilege: Grant only the necessary permissions required for each user or role.
- Secure Against Common Vulnerabilities: Validate data inputs and ensure rules prevent unauthorized modifications.
- Iterative Development: Start with basic rules and progressively add complexity as your application’s security needs evolve.
- Testing: Thoroughly test your security rules in development and staging environments before deploying to production.
Use Cases and Integration
Firestore’s versatility makes it suitable for a broad range of applications and integrations.
Mobile Applications
Its real-time synchronization and offline support are particularly well-suited for building engaging and resilient mobile experiences across iOS and Android. Developers can easily build features like user profiles, content feeds, and real-time messaging.
Web Applications
For single-page applications (SPAs) and progressive web apps (PWAs), Firestore provides a dynamic backend that can power interactive UIs and real-time data updates, offering a fluid user experience comparable to native applications.
Internet of Things (IoT)
Firestore’s ability to handle a high volume of writes and its real-time nature make it an excellent choice for collecting and processing data from IoT devices. Sensor readings can be streamed to Firestore, and applications can react to this data in real-time.
Gaming
Game developers can leverage Firestore for synchronizing game states, player data, leaderboards, and multiplayer interactions. The real-time capabilities ensure a synchronized experience for all players.
Enterprise Applications
From internal dashboards to customer-facing portals, Firestore can serve as a scalable and flexible database for enterprise solutions, enabling real-time data visibility and collaborative workflows.

Integration with Firebase Ecosystem
Firestore is a core component of the Firebase platform, working seamlessly with other Firebase services like Firebase Authentication, Cloud Functions, Firebase Hosting, and Firebase ML. This integrated ecosystem allows developers to build complex, full-stack applications more efficiently, leveraging the power of a unified backend-as-a-service (BaaS) platform. For example, Cloud Functions can be triggered by Firestore events, enabling serverless backend logic that responds to data changes, such as sending email notifications when a new order is placed.
In conclusion, Firestore represents a modern, scalable, and real-time NoSQL database solution that empowers developers to build sophisticated applications with enhanced user experiences and robust data management capabilities. Its flexible data model, powerful real-time features, and strong security controls make it a compelling choice for a wide array of development projects.