Data virtualization represents a significant evolution in how organizations access, manage, and leverage their information assets. It fundamentally changes the traditional approach to data integration, moving away from physical data movement and replication towards a unified, logical view of disparate data sources. In essence, data virtualization creates an abstraction layer that sits above the underlying data repositories, allowing users to query and access data as if it were all in one place, without the need for complex ETL (Extract, Transform, Load) processes or the creation of massive data warehouses.
The core concept revolves around providing real-time, unified access to data regardless of its location, format, or structure. This is achieved through a virtualization engine that intercepts data requests, queries the relevant source systems, retrieves the necessary data, and presents it in a consistent format to the requesting application or user. This agile and dynamic approach unlocks new possibilities for data-driven decision-making, analytics, and application development.
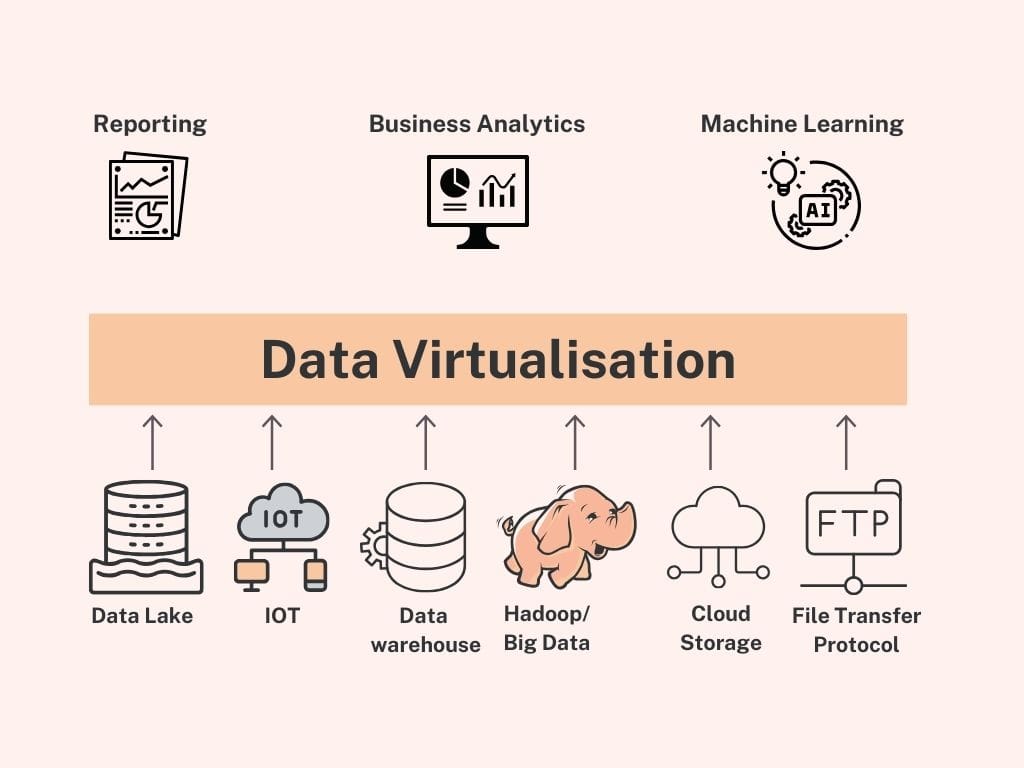
The Core Principles of Data Virtualization
At its heart, data virtualization is built upon several key principles that distinguish it from traditional data integration methods. Understanding these principles is crucial to appreciating its power and applicability in modern data architectures.
Logical Data Abstraction
The most fundamental principle is the creation of a logical data model that represents a unified view of all available data sources. This model is independent of the physical storage mechanisms. Instead of physically consolidating data into a central repository, data virtualization defines how data from various sources can be combined and presented. This abstraction layer allows business users and applications to interact with data through a single, consistent interface, shielding them from the complexities of underlying data structures and locations.
Real-Time Access
Unlike batch-oriented ETL processes that extract and transform data at scheduled intervals, data virtualization provides real-time or near-real-time access to information. When a query is made, the virtualization engine immediately connects to the relevant source systems, retrieves the required data, and returns it to the user. This is particularly valuable for scenarios where up-to-the-minute data is critical for operational decisions, such as fraud detection, customer service, or financial trading.
Decoupling of Data Consumers from Data Producers
Data virtualization decouples applications and users from the underlying data sources. This means that changes to source systems – such as upgrades, migrations, or schema modifications – have minimal impact on the applications that consume the data. As long as the logical data model remains consistent, the virtualization layer can adapt to changes in the physical infrastructure without requiring widespread application reconfigurations. This significantly reduces maintenance overhead and increases agility.
Federated Query Processing
When a query is issued against the virtualized data layer, the virtualization engine determines the most efficient way to retrieve and combine data from multiple sources. This often involves optimizing queries and pushing down processing logic to the source systems whenever possible to minimize data movement. This federated query processing capability ensures that data remains close to its origin, reducing latency and the strain on network resources.
Data Governance and Security
While data virtualization emphasizes ease of access, it does not compromise on governance and security. Robust security mechanisms can be implemented at the virtualization layer, ensuring that users only access the data they are authorized to see. This includes role-based access control, data masking, and auditing capabilities. Furthermore, the logical view can be used to enforce data policies and standards across the organization, promoting data quality and compliance.
Benefits and Advantages of Data Virtualization
The adoption of data virtualization offers a compelling set of benefits that can transform an organization’s data strategy and operational efficiency. These advantages address many of the pain points associated with traditional data integration approaches.
Agility and Faster Time-to-Insight
One of the most significant advantages is the increased agility it provides. By eliminating the need for lengthy ETL development cycles and the creation of physical data warehouses, organizations can gain access to data and derive insights much faster. This is critical in today’s fast-paced business environment, where the ability to react quickly to market changes and customer demands is a key differentiator. Analysts and data scientists can begin exploring data sets without waiting for IT to physically move and transform them.
Reduced Costs
Data virtualization can lead to substantial cost savings. It reduces the need for expensive data warehousing infrastructure, storage, and the complex development and maintenance of ETL processes. By leveraging existing data sources and only accessing data on demand, organizations can optimize their IT investments and reallocate resources to more strategic initiatives. The operational costs associated with managing redundant data copies are also eliminated.
Enhanced Data Democratization
Data virtualization promotes data democratization by providing a simplified and unified interface to data for a broader range of users. Business users, analysts, and developers can access the data they need without requiring deep technical expertise in the underlying systems. This empowers individuals across the organization to make data-driven decisions, fostering a more data-literate culture.
Improved Data Quality and Consistency
While data virtualization doesn’t physically cleanse data, it can enforce data quality and consistency through the logical model and access policies. By defining standardized views and applying transformation rules at the virtualization layer, organizations can present a consistent and reliable view of data, even if the underlying source systems have variations. This helps to avoid the “garbage in, garbage out” problem often associated with disparate data sources.
Support for Diverse Data Sources and Formats
Modern organizations deal with a vast array of data sources, including relational databases, NoSQL databases, cloud storage, flat files, APIs, and streaming data. Data virtualization excels at integrating these heterogeneous sources. The virtualization engine can connect to and query virtually any data source, abstracting away the differences in formats, protocols, and query languages.
Simplified Data Management and Maintenance
By providing a single point of access and control for data, virtualization simplifies data management. The maintenance efforts are concentrated on the virtualization layer and the connection to source systems, rather than on a multitude of physical data pipelines. Changes to source systems can be managed more efficiently, reducing the risk of breaking downstream applications.
Use Cases for Data Virtualization
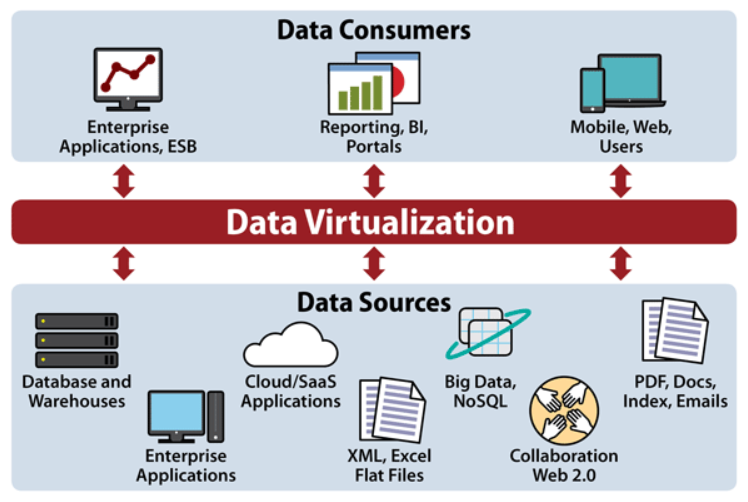
The versatility of data virtualization makes it applicable to a wide range of business scenarios and industries. Its ability to provide unified, real-time access to data unlocks value in numerous operational and analytical applications.
Customer 360 View
Creating a comprehensive view of the customer is a common challenge. Data virtualization can aggregate customer information from various touchpoints, such as CRM systems, sales databases, marketing platforms, and customer service logs, into a single, unified customer profile. This enables sales, marketing, and support teams to have a complete understanding of each customer, leading to more personalized interactions and improved service.
Real-Time Analytics and Business Intelligence
For organizations that require up-to-the-minute insights, data virtualization is a game-changer. It allows business intelligence tools and dashboards to query live data from operational systems, providing real-time performance monitoring, trend analysis, and decision support. This is crucial for industries like finance, retail, and manufacturing where immediate information is vital for competitive advantage.
Big Data Integration
When dealing with large volumes of data from diverse sources, integrating them into a traditional data warehouse can be prohibitively complex and expensive. Data virtualization offers a more agile approach by creating a logical view of big data assets, enabling analysts to explore and query them without the need for extensive data movement and preparation.
Data Governance and Compliance
Data virtualization can play a critical role in data governance initiatives. By providing a centralized point for enforcing access controls, data masking, and auditing, it helps organizations meet regulatory compliance requirements and ensure data security. The ability to define and manage data access policies at the virtualization layer simplifies governance processes.
Cloud Migration and Hybrid Cloud Strategies
As organizations move to the cloud, data virtualization can facilitate hybrid cloud strategies. It allows businesses to access and integrate data residing in both on-premises and cloud-based systems seamlessly. This eases the transition to the cloud and enables organizations to leverage data from both environments without the need for a complete data migration upfront.
Master Data Management (MDM) Support
Data virtualization can complement Master Data Management solutions by providing a virtualized layer that exposes the governed master data to consuming applications. This ensures that applications always access the single, authoritative version of key business entities, such as customers, products, or locations, without requiring physical data replication.
Implementing Data Virtualization
Successfully implementing data virtualization requires careful planning and consideration of various factors to maximize its benefits and avoid common pitfalls.
Define Business Requirements and Use Cases
The first step is to clearly define the business problems that data virtualization will solve and identify the specific use cases. Understanding who will use the virtualized data, what data they need, and how they will use it will guide the entire implementation process. This ensures that the solution is aligned with business objectives.
Select the Right Data Virtualization Platform
A wide range of data virtualization platforms are available, each with different features, capabilities, and pricing models. Factors to consider include the types of data sources supported, performance characteristics, scalability, security features, integration capabilities with existing BI and analytics tools, and the vendor’s support and roadmap.
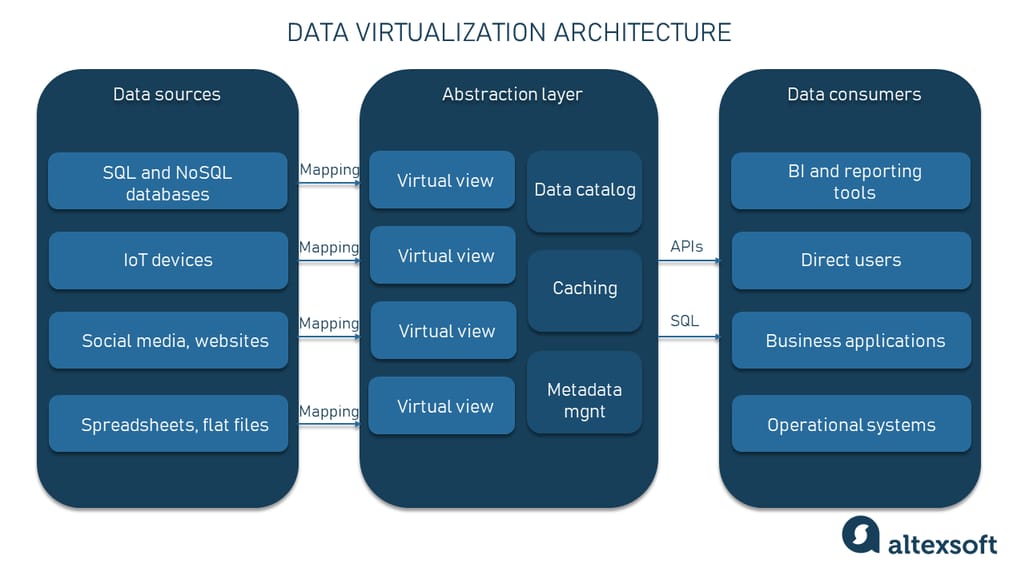
Design the Logical Data Model
The design of the logical data model is a critical aspect of data virtualization. This involves defining the virtual views, relationships, and transformations needed to present a unified and consistent view of the data. A well-designed logical model will simplify data access and minimize the complexity for end-users.
Establish Data Governance and Security Policies
Before going live, robust data governance and security policies must be established. This includes defining access roles and permissions, implementing data masking for sensitive information, and setting up auditing mechanisms to track data access and usage. These policies should be enforced at the virtualization layer.
Plan for Performance Optimization
While data virtualization offers many advantages, performance can be a concern, especially with complex queries or very large datasets. Performance optimization strategies may include query optimization, caching, data source tuning, and intelligent data placement or federation. It’s essential to monitor performance and make adjustments as needed.
Change Management and User Training
Adopting data virtualization often represents a shift in how users access and interact with data. Effective change management strategies and comprehensive user training are crucial for successful adoption. Users need to understand how to leverage the new capabilities and the benefits they offer.
The Future of Data Virtualization
Data virtualization is not a static technology; it is continuously evolving to meet the growing demands of data-intensive organizations. As the volume, velocity, and variety of data continue to increase, data virtualization is poised to play an even more significant role in enabling agile, flexible, and cost-effective data access.
The integration of AI and machine learning within data virtualization platforms is a key area of development. AI can be leveraged for intelligent query optimization, automated data cataloging, and proactive identification of data quality issues. Furthermore, the convergence of data virtualization with data fabric and data mesh architectures is likely to lead to more decentralized and self-service data management paradigms.
As organizations strive to become more data-driven, the ability to access and integrate information quickly and efficiently will remain paramount. Data virtualization offers a powerful and adaptable solution to unlock the full potential of an organization’s data assets, fostering innovation and driving competitive advantage in the digital age.