Data scrubbing, also known as data cleansing or data cleaning, is a critical process within the realm of data management and analysis. It involves identifying and correcting or removing inaccurate, incomplete, improperly formatted, or redundant data from datasets. While the concept itself isn’t inherently tied to any single technological domain, its application is paramount in fields that rely heavily on precise and reliable information. For the purpose of this discussion, we will explore data scrubbing through the lens of Tech & Innovation, specifically how it underpins advancements in areas like autonomous systems, AI-driven decision-making, and sophisticated data analysis.

The increasing reliance on technology for complex tasks means that the quality of the underlying data directly impacts the efficacy and safety of these innovations. Inaccurate data can lead to flawed algorithms, incorrect predictions, operational failures, and even significant financial losses or safety hazards. Therefore, understanding and implementing robust data scrubbing techniques is not merely a best practice; it’s a foundational requirement for building trustworthy and effective technological solutions.
The Imperative of Data Quality in Tech & Innovation
In the rapidly evolving landscape of tech and innovation, data is the lifeblood. From machine learning models that power smart devices to the vast datasets required for scientific research and development, the integrity of information is non-negotiable. Poor data quality can manifest in numerous ways, each with detrimental consequences for technological progress.
Sources of Data Imperfection
Data rarely enters a system in a perfectly pristine state. Its journey from origin to analysis is fraught with potential for errors:
- Human Error: Manual data entry is prone to typos, misinterpretations, and inconsistencies. This is especially prevalent in legacy systems or during initial data collection phases. For instance, a surveyor might mistype a GPS coordinate, or a user might enter an incorrect parameter in a configuration file for an autonomous system.
- System Malfunctions and Data Corruption: Technical glitches during data transmission, storage, or processing can lead to corrupted or incomplete records. This can range from a sensor intermittently failing to transmit data to a database error corrupting entire entries.
- Inconsistent Formatting: Data collected from disparate sources often adheres to different standards. Dates might be in varying formats (MM/DD/YYYY, DD-MM-YYYY, YYYY/MM/DD), units of measurement might differ (metric vs. imperial), or categorical data might use different labels for the same concept (e.g., “USA,” “United States,” “U.S.A.”).
- Outdated Information: In dynamic environments, data can quickly become obsolete. Information about object positions, environmental conditions, or user preferences needs to be current for systems to function correctly.
- Duplicate Records: The same piece of information might be entered multiple times, leading to inflated counts and skewed analyses. This is common in CRM systems or sensor logs where multiple instances of an event might be recorded.
- Missing Values: Incomplete records, where certain fields are left blank, can significantly hinder analysis. The absence of a critical data point, such as a sensor reading or a crucial parameter, can render an entire record unusable for certain algorithms.
The Cascading Effects of Poor Data
The consequences of neglecting data quality are far-reaching, particularly in technologically advanced fields:
- Flawed AI and Machine Learning Models: Machine learning algorithms are trained on data. If the training data is inaccurate or biased, the resulting model will inherit these flaws. This can lead to incorrect predictions, biased decision-making, and a failure to generalize to new, unseen data. Imagine an autonomous vehicle trained on improperly scrubbed sensor data; it might misinterpret road signs or fail to detect obstacles.
- Ineffective Autonomous Systems: Systems designed to operate autonomously, whether in robotics, aviation, or logistics, rely on real-time, accurate data for navigation, decision-making, and control. Corrupted or inconsistent data can lead to navigational errors, collisions, or a complete system failure.
- Misleading Analytics and Insights: Business intelligence, scientific research, and operational monitoring all depend on analytical insights derived from data. If the data is flawed, the insights will be too, leading to poor strategic decisions, misdirected research efforts, and inefficient operations.
- Reduced Efficiency and Increased Costs: Remedying errors after they have impacted a system or analysis is far more costly and time-consuming than implementing robust data scrubbing from the outset. Repeatedly identifying and correcting issues in production environments can disrupt operations and incur significant financial penalties.
- Compromised Security: In data-sensitive applications, such as cybersecurity or secure communication, data integrity is crucial for maintaining system security. Inconsistencies or corruption can create vulnerabilities or lead to false alarms.
The Process of Data Scrubbing
Data scrubbing is not a single, monolithic activity but rather a multi-stage process that requires careful planning and execution. It typically involves several key steps, often iteratively applied, to ensure data accuracy and consistency.
Data Profiling and Assessment
Before any scrubbing can occur, a thorough understanding of the data is required. Data profiling involves examining the data to identify its structure, content, and quality. This step helps in understanding the nature of the errors present.
- Column Analysis: Examining each column for data types, value ranges, frequency distributions, and the presence of outliers.
- Relationship Analysis: Understanding how different data fields relate to each other and identifying potential inconsistencies across related fields. For example, checking if a shipping address is consistent with a billing address.
- Pattern Recognition: Identifying common formats and patterns within the data to establish a baseline for expected structure.
- Error Identification: Pinpointing specific instances of errors, such as missing values, invalid formats, or duplicate entries, based on predefined rules or discovered patterns.
Data Cleansing Techniques
Once the data has been profiled, various techniques are employed to rectify the identified issues. The specific methods chosen depend on the type of error and the desired outcome.
Handling Missing Values
- Imputation: Replacing missing values with estimated values. Common imputation methods include:
- Mean/Median/Mode Imputation: Replacing missing numerical values with the mean or median of the column, or missing categorical values with the mode.
- Regression Imputation: Using regression models to predict missing values based on other variables in the dataset.
- K-Nearest Neighbors (KNN) Imputation: Estimating missing values based on the values of their nearest neighbors in the dataset.
- Deletion: Removing records with missing values. This is often done when the number of missing values is small or when the missingness is systematic and cannot be reliably imputed.
- Row Deletion: Removing entire records with missing critical data points.
- Column Deletion: Removing entire columns if they contain a very high percentage of missing values and are not deemed critical.
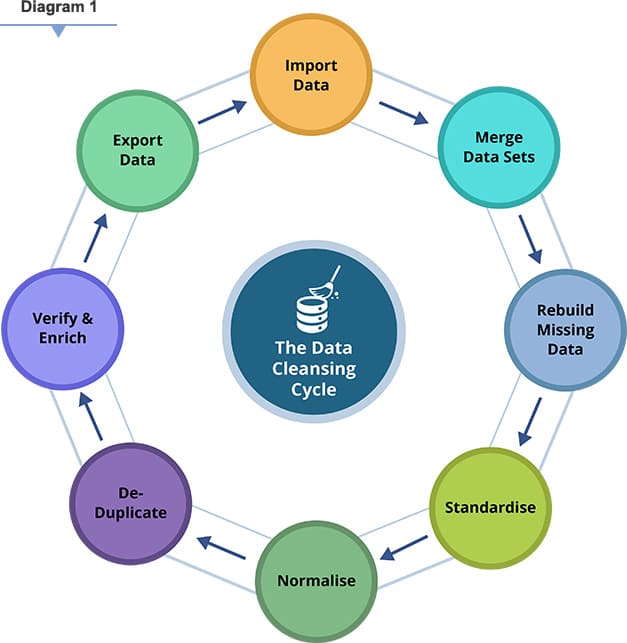
Standardizing and Formatting Data
- Format Correction: Ensuring data conforms to a consistent format. This includes:
- Date Standardization: Converting all dates to a uniform format (e.g., YYYY-MM-DD).
- Unit Conversion: Converting measurements to a common unit of measure.
- Case Standardization: Converting text to a consistent case (e.g., all lowercase or all uppercase).
- Text Normalization: Applying techniques like stemming (reducing words to their root form) or lemmatization (reducing words to their dictionary form) to normalize text data for better comparison and analysis.
- Address Standardization: Using tools to correct and standardize postal addresses to ensure accuracy for logistics and delivery systems.
Correcting Inaccuracies and Inconsistencies
- Outlier Detection and Treatment: Identifying data points that deviate significantly from the expected range. Outliers can be:
- Erroneous: Data entry mistakes that need to be corrected or removed.
- Genuine: Valid data points that represent extreme but real observations. These might be retained or analyzed separately depending on the context.
- Deduplication: Identifying and merging or removing duplicate records based on matching criteria. This is crucial for avoiding redundant information and ensuring accurate counts.
- Validation Rules: Applying business logic or predefined rules to check data integrity. For example, ensuring that a product code exists in a product catalog or that a discount percentage is within an acceptable range.
Data Validation and Verification
After the cleansing process, it’s essential to validate the results to ensure that the scrubbing has achieved its objectives without introducing new errors.
- Re-profiling: Performing data profiling again on the scrubbed dataset to confirm that the identified issues have been resolved.
- Auditing: Manually reviewing a sample of the scrubbed data to verify the accuracy and appropriateness of the cleansing operations.
- Comparison with Source Data: Where feasible, comparing the scrubbed data with its original source to identify any discrepancies introduced during the cleaning process.
- Monitoring: Implementing ongoing monitoring processes to detect and address data quality issues as they arise in the future.
Data Scrubbing Tools and Technologies
The complexity of data scrubbing has led to the development of a wide range of tools and technologies, from simple scripting solutions to sophisticated enterprise-level platforms. The choice of tool often depends on the volume of data, the complexity of the cleansing required, and the existing technological infrastructure.
Scripting and Programming Languages
For smaller datasets or highly specific cleansing tasks, scripting languages are often employed.
- Python: With libraries like Pandas, NumPy, and Scikit-learn, Python offers powerful capabilities for data manipulation, statistical analysis, and machine learning, making it a popular choice for data scrubbing.
- R: Another robust language for statistical computing and graphics, R provides extensive packages for data cleaning and transformation.
- SQL: For data residing in relational databases, SQL queries can be used to identify and correct inconsistencies, handle missing values, and enforce data integrity constraints.
Dedicated Data Quality Tools
A growing number of commercial and open-source tools are specifically designed for data quality management, including scrubbing. These tools often provide a more user-friendly interface, pre-built functionalities, and advanced features.
- ETL (Extract, Transform, Load) Tools: Many ETL platforms, such as Informatica, Talend, and Microsoft SSIS, incorporate data cleansing and transformation capabilities as part of their data integration workflows.
- Data Quality Platforms: Specialized software suites, like Trifacta, Alteryx, and IBM InfoSphere QualityStage, offer comprehensive solutions for data profiling, cleansing, standardization, and enrichment. These platforms often leverage AI and machine learning to automate aspects of the scrubbing process.
- Master Data Management (MDM) Solutions: MDM systems are designed to create and maintain a single, authoritative view of key business entities (e.g., customers, products). Data scrubbing is an integral part of MDM, ensuring that the master data is accurate and consistent.
AI and Machine Learning in Data Scrubbing
Artificial intelligence and machine learning are increasingly being integrated into data scrubbing processes to enhance efficiency and accuracy.
- Anomaly Detection: ML algorithms can be trained to identify unusual patterns or outliers that might indicate errors, often with greater precision than rule-based systems.
- Pattern Recognition for Standardization: ML can learn complex data patterns to automate standardization and formatting, even for semi-structured or unstructured text.
- Predictive Imputation: Advanced ML models can provide more sophisticated imputation for missing values, leading to less biased results.
- Entity Resolution: AI-powered tools can effectively identify and link records that refer to the same real-world entity, even if they are not exact matches, which is crucial for deduplication.
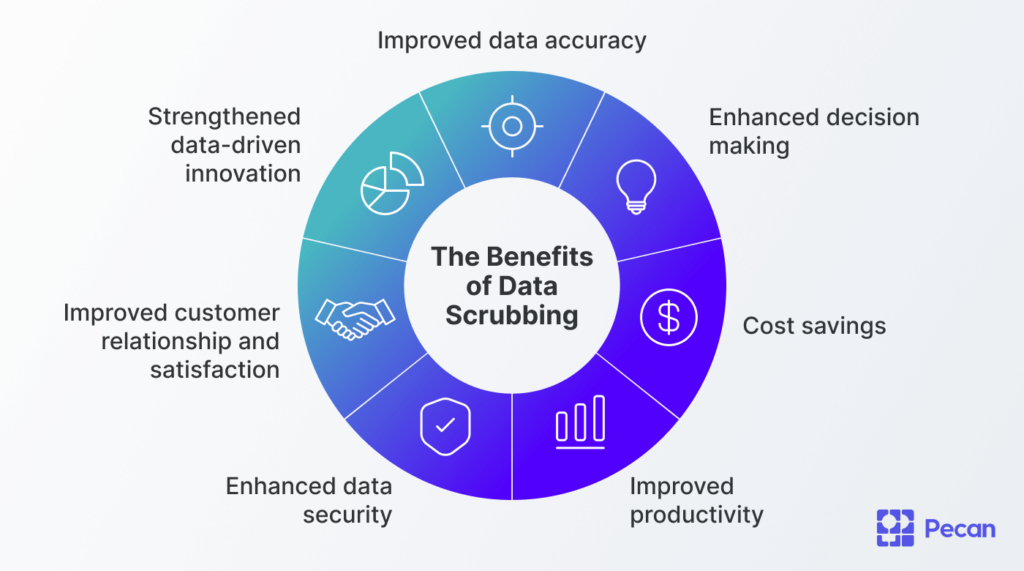
Conclusion: The Foundation of Trustworthy Technology
In the domain of tech and innovation, data scrubbing is not an optional add-on; it is a fundamental pillar upon which the reliability and success of advanced technologies are built. From the autonomous systems that navigate our world to the AI models that shape our digital experiences, the integrity of the underlying data is paramount. By systematically identifying and rectifying inaccuracies, inconsistencies, and redundancies, data scrubbing ensures that the information fueling these innovations is accurate, complete, and fit for purpose.
Investing in robust data scrubbing processes, utilizing appropriate tools, and fostering a culture of data quality are essential for any organization aiming to leverage the full potential of technological advancements. As data volumes continue to grow and the complexity of technological applications increases, the importance of meticulous data scrubbing will only escalate, solidifying its role as an indispensable component of modern technological progress.