The landscape of cloud computing is perpetually evolving, with new services and technologies emerging to address the ever-increasing demands for scalability, performance, and cost-efficiency. Among these advancements, Amazon Web Services (AWS) has consistently been at the forefront, introducing innovations that reshape how businesses and developers operate. One such significant innovation is Amazon Aurora, a relational database service that offers a compelling blend of speed, availability, and compatibility with popular database engines.
While the title “What is Aurora AWS?” might suggest a broad overview, delving into its core functionalities, architecture, and key advantages is crucial for understanding its impact. This article will explore Aurora’s essence, focusing on its technological underpinnings and how it empowers modern applications.

Understanding the Core of Amazon Aurora
Amazon Aurora is not just another database service; it’s a reimagining of relational database architecture designed for the cloud. It provides a fully managed service, meaning AWS handles the heavy lifting of database administration, such as patching, backups, and scaling, allowing users to concentrate on their applications. At its heart, Aurora aims to deliver performance and availability far exceeding that of standard MySQL and PostgreSQL databases, while maintaining compatibility with these widely used open-source engines.
Aurora’s Architectural Innovation: The Shared Storage Volume
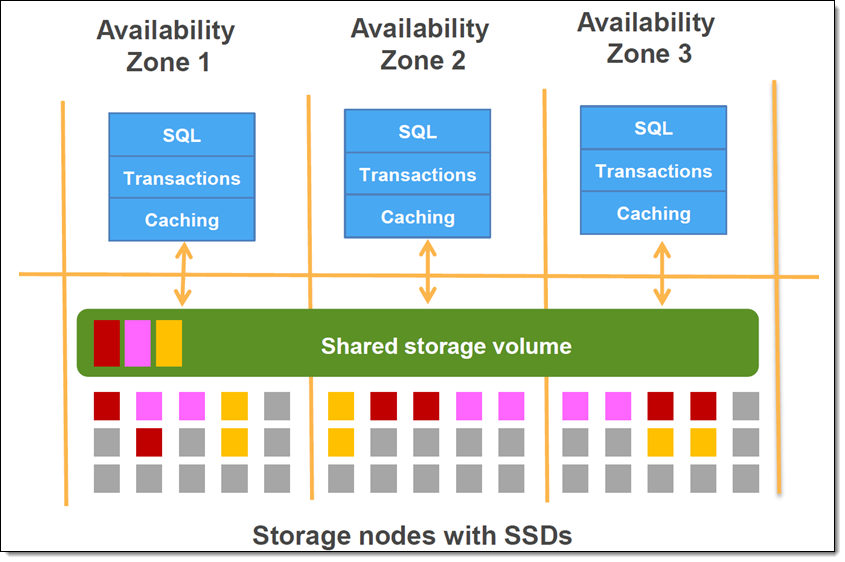
The secret sauce behind Aurora’s exceptional performance lies in its distributed, fault-tolerant, self-healing storage system. Unlike traditional databases that store data on individual instances, Aurora separates compute and storage. This separation is facilitated by a custom-built storage layer that spans multiple Availability Zones (AZs) within an AWS region.
Data Distribution and Replication
Aurora’s storage volume is comprised of 15 storage replicas, distributed across three Availability Zones. Each storage replica is an independent entity, meaning that the failure of one or even multiple replicas does not impact the availability of the database. Data is written to six of these replicas (three in each of two AZs) for durability. This approach ensures that data is highly available and durable, with a typical availability of 99.99%.
Performance Enhancements
This unique storage architecture significantly boosts performance. Writes are acknowledged once they are written to a majority of the six primary replicas, allowing for much faster transaction commit times. Reads, on the other hand, can be served by any of the 15 replicas, distributing the read load and preventing bottlenecks. Aurora’s storage also features automatic repair, where it detects and repairs corrupted data blocks without impacting database performance. Furthermore, it offers up to 10x higher throughput than standard MySQL and up to 3x higher throughput than standard PostgreSQL.
Engine Compatibility and Flexibility
A critical aspect of Aurora’s appeal is its compatibility with existing MySQL and PostgreSQL applications. This means that developers can migrate their existing applications to Aurora with minimal or no code changes. AWS provides Aurora compatible with MySQL and Aurora compatible with PostgreSQL, allowing users to choose the engine that best suits their needs or existing infrastructure. This compatibility significantly lowers the barrier to adoption for organizations looking to leverage the benefits of Aurora without undertaking extensive application rewrites.
Key Benefits and Use Cases of Aurora AWS
The architectural innovations of Aurora translate into tangible benefits for a wide range of applications. Its speed, availability, and managed nature make it an ideal choice for demanding workloads.
High Performance and Scalability
Aurora’s ability to deliver high throughput and low latency makes it suitable for applications requiring rapid data processing. Whether it’s an e-commerce platform experiencing peak traffic, a financial trading application, or a large-scale data analytics workload, Aurora can handle the load. The service also offers seamless horizontal scaling of read replicas to manage read-heavy workloads. For write scaling, Aurora provides features like Aurora Serverless, which automatically scales compute capacity up and down based on application demand, further optimizing costs and performance.
Read Scalability with Read Replicas
Aurora allows you to create up to 15 low-latency read replicas that share the same underlying storage as your primary database instance. This is a game-changer for read-heavy applications, as it distributes read traffic across multiple instances, improving overall performance and responsiveness. The replication lag between the primary instance and read replicas is typically less than 10 milliseconds.
Aurora Serverless: On-Demand Scaling
Aurora Serverless is a fully managed, auto-scaling configuration for Amazon Aurora. It automatically starts up, shuts down, and scales capacity up or down based on your application’s needs. This means you only pay for the database capacity you consume, making it highly cost-effective for applications with intermittent or unpredictable workloads. It’s particularly useful for development and testing environments, or for applications with variable demand.
Enhanced Availability and Durability
In today’s business environment, downtime can be incredibly costly. Aurora’s robust architecture is designed for high availability and data durability. The multi-AZ replication of its storage layer ensures that your database remains accessible even in the event of an Availability Zone outage.
Fault Tolerance and Self-Healing
The underlying storage system is designed to be fault-tolerant. It automatically detects and repairs storage failures, and data is replicated across multiple storage volumes. If a disk failure occurs, Aurora automatically repairs it by reading from other replicas without loss of availability. This self-healing capability minimizes the risk of data loss and ensures continuous operation.

Automated Backups and Point-in-Time Recovery
Aurora automatically performs continuous backups of your database to Amazon S3. These backups are incremental, meaning only the data that has changed since the last backup is stored, which is efficient and cost-effective. You can also perform point-in-time recovery, allowing you to restore your database to any second within your backup retention period (up to 35 days), providing an essential safety net for data recovery.
Cost-Effectiveness and Efficiency
While Aurora offers premium performance, it is also designed to be cost-effective. The separation of compute and storage, combined with features like Aurora Serverless, allows organizations to optimize their spending. By provisioning only the necessary compute resources and benefiting from automated scaling, businesses can avoid over-provisioning and reduce their overall database operational costs.
Pay-as-you-go Pricing
Aurora follows a pay-as-you-go pricing model, where you pay for the database instances you use, the amount of storage consumed, and I/O operations. Aurora Serverless further enhances cost efficiency by charging only for the compute capacity consumed, down to the second, with a minimum of one Aurora Capacity Unit (ACU) consumed per second.
Optimized for AWS Ecosystem
Being an AWS native service, Aurora integrates seamlessly with other AWS services. This integration simplifies the development and deployment of cloud-native applications, allowing for greater efficiency in building and managing complex systems. For instance, it integrates well with services like Amazon RDS, AWS Lambda, and Amazon EC2, providing a comprehensive suite of tools for building robust and scalable solutions.
Technical Deep Dive: How Aurora Achieves Its Performance
To truly appreciate Aurora, it’s beneficial to understand some of the underlying technical mechanisms that contribute to its exceptional performance and reliability.
Storage Engine Optimizations
Aurora’s storage engine is custom-built and optimized for cloud environments. It leverages techniques such as log-structured storage, which can improve write performance and durability. The system is designed to minimize I/O operations by efficiently managing data blocks and reducing the need for complex buffering and caching strategies found in traditional databases.
WAL Compression and Log-Structured Storage
Aurora employs techniques like Write-Ahead Logging (WAL) compression and a log-structured storage approach. This means that data modifications are written sequentially to a log, which is then used to update data pages. This approach can lead to higher write throughput and improved durability compared to traditional page-based storage systems.
I/O Efficiency
The storage architecture is designed to be highly I/O efficient. Data is transferred in 2MB chunks, and the system employs intelligent caching mechanisms to reduce the need for frequent disk reads. This efficiency is crucial for high-transaction workloads and contributes significantly to Aurora’s speed.
Compute Instances and Connections
Aurora supports a range of DB instance classes, allowing users to select the appropriate compute and memory resources for their workload. The service also supports a large number of connections, enabling it to handle concurrent access from numerous application instances.
Instance Sizing and Memory Management
Users can choose from various Aurora instance types, each offering different levels of CPU, memory, and network performance. Aurora’s memory management is optimized to ensure that frequently accessed data is readily available in memory, further reducing latency.
Connection Pooling and Management
Effective connection management is vital for database performance, especially under heavy load. Aurora, by design, is engineered to efficiently handle a large number of concurrent connections, ensuring that applications can access the database without performance degradation due to connection bottlenecks.
Conclusion: Aurora AWS as a Cloud Database Powerhouse
Amazon Aurora stands as a testament to AWS’s commitment to innovation in the database space. By fundamentally rethinking relational database architecture for the cloud, Aurora delivers unparalleled performance, availability, and durability, all while maintaining compatibility with familiar open-source engines.
Its distributed, self-healing storage system, coupled with optimized compute instances and flexible scaling options like Aurora Serverless, makes it an ideal choice for mission-critical applications that demand speed, reliability, and cost-efficiency. Whether you’re migrating an existing application or building a new cloud-native solution, Amazon Aurora offers a robust and powerful foundation for your data needs, solidifying its position as a leading relational database service in the cloud.