In the realm of programming, the concept of a “float” refers to a fundamental data type used to represent numbers that have a decimal point, also known as floating-point numbers. Unlike integers, which can only store whole numbers, floats allow for the representation of fractional values, making them indispensable for a wide range of computational tasks. Understanding floats is crucial for any programmer, as they underpin many calculations, from scientific simulations to financial modeling.
The Nature of Floating-Point Representation
At its core, a float in programming is an approximation of a real number. Computers store numbers in a binary format, and not all decimal numbers can be precisely represented in binary. This leads to the concept of floating-point arithmetic, which is governed by specific standards, most notably the IEEE 754 standard. This standard defines how floating-point numbers are stored and manipulated in computer memory.

Binary Representation and Precision
A floating-point number is typically stored using a fixed number of bits. This representation usually involves three components: a sign bit, an exponent, and a significand (or mantissa). The sign bit indicates whether the number is positive or negative. The exponent determines the magnitude of the number, essentially dictating where the decimal point is placed. The significand represents the significant digits of the number.
For example, a common 32-bit single-precision float uses 1 bit for the sign, 8 bits for the exponent, and 23 bits for the significand. A 64-bit double-precision float offers more bits for both the exponent and significand, allowing for a wider range of values and greater precision.
The trade-off for representing a wide range of numbers, including very small and very large ones, is inherent imprecision. Many decimal fractions, such as 0.1, cannot be represented exactly in binary. When these numbers are converted, small rounding errors can occur. While these errors are often negligible for everyday calculations, they can become significant in applications requiring high accuracy, such as scientific computing or financial transactions where even tiny discrepancies can have substantial consequences.
Single vs. Double Precision
Programming languages typically offer at least two types of floating-point precision: single and double.
-
Single-Precision Floats: These are usually 32 bits in size. They offer a good balance between memory usage and numerical range. They are suitable for many general-purpose applications where extreme precision is not paramount. However, their precision is limited, and they can accumulate errors more quickly than double-precision floats.
-
Double-Precision Floats: These are typically 64 bits in size. They provide a much wider range of values and significantly higher precision compared to single-precision floats. They are the preferred choice for scientific calculations, engineering simulations, and any application where accuracy is critical. The increased precision comes at the cost of using more memory and potentially slightly slower computations on some hardware.
Operations and Considerations with Floats
Working with floats involves understanding how arithmetic operations are performed and the potential pitfalls associated with them.
Arithmetic Operations
Basic arithmetic operations like addition, subtraction, multiplication, and division can be performed on float variables. However, the results are subject to the inherent precision limitations of floating-point representation.
-
Addition and Subtraction: When adding or subtracting two floats, the numbers are first aligned based on their exponents. This alignment process can sometimes introduce rounding errors, especially if the numbers have vastly different magnitudes.
-
Multiplication and Division: Multiplication involves multiplying the significands and adding the exponents. Division involves dividing the significands and subtracting the exponents. These operations can also lead to precision loss.
Comparison of Floats
Comparing two floating-point numbers for exact equality can be problematic due to the potential for small representation errors. Directly using the equality operator (==) might return false even if the numbers are mathematically intended to be equal.
For example, 0.1 + 0.2 might not be exactly equal to 0.3 in floating-point arithmetic. Instead of direct equality checks, it’s common practice to compare floats within a small tolerance, often referred to as an epsilon. This involves checking if the absolute difference between the two numbers is less than a predefined small value.
if abs(a - b) < epsilon:
# Consider a and b to be equal
The choice of epsilon depends on the specific application and the acceptable margin of error.
Potential Pitfalls

Several common issues arise when working with floats:
-
Rounding Errors: As discussed, the inability to perfectly represent all decimal numbers in binary leads to rounding errors that can accumulate over a series of operations.
-
Overflow and Underflow: Floating-point types have a limited range. If a calculation results in a number too large to be represented, it leads to an overflow error, often resulting in a special value like infinity. Conversely, if a calculation results in a number too small (close to zero) to be represented with the available precision, it causes an underflow error, which might result in zero or a denormalized number.
-
Division by Zero: Similar to integers, dividing a float by zero will result in an error, typically producing a special value like positive or negative infinity, or a NaN (Not a Number) depending on the context and programming language.
When to Use Floats
Floats are the go-to data type for any scenario involving fractional numbers. Their applications are vast and span numerous fields:
Scientific and Engineering Calculations
- Physics simulations: Modeling trajectories, forces, and energy levels often requires high-precision floating-point numbers.
- Engineering design: Calculations for structural integrity, fluid dynamics, and electrical circuits rely heavily on float precision.
- Data analysis: Statistical calculations, regression analysis, and machine learning models frequently use floats to represent data points and model parameters.
Financial Applications
- Currency calculations: While often stored as fixed-point or integer types to avoid precision issues with currency, many intermediate calculations in financial modeling may use floats.
- Algorithmic trading: Complex algorithms that execute trades based on real-time market data utilize floats for price fluctuations and calculations.
Graphics and Game Development
- 3D rendering: Coordinates, transformations, lighting calculations, and vertex positions in 3D graphics are typically represented using floats.
- Physics engines in games: Simulating object motion, collisions, and environmental interactions in video games demands the use of floats.
General Programming Tasks
- Measurements: Representing distances, temperatures, weights, and other measurable quantities that are not always whole numbers.
- Averages: Calculating the average of a set of numbers, which often results in a fractional value.
- Percentages and Ratios: Expressing proportions and relationships that involve non-integer values.
Alternatives and Best Practices
While floats are powerful, their limitations necessitate careful consideration and sometimes the use of alternative approaches.
Fixed-Point Arithmetic
For applications where exact decimal representation is critical, such as financial calculations involving currency, fixed-point arithmetic is often preferred. In fixed-point representation, the position of the decimal point is fixed, meaning a certain number of digits are always assumed to be after the decimal. This avoids the rounding errors associated with binary floating-point representations but limits the range of representable numbers.
Integer Arithmetic for Specific Cases
In some cases, it’s possible to represent fractional values using integers. For example, if you’re dealing with cents, you could store the value as an integer representing the total number of cents, avoiding the need for floats altogether for currency.
Libraries for High Precision
For highly specialized applications requiring extreme precision beyond what standard double-precision floats offer, libraries exist that provide arbitrary-precision arithmetic. These libraries allow for computations with a virtually unlimited number of digits, but they come with a significant performance overhead.
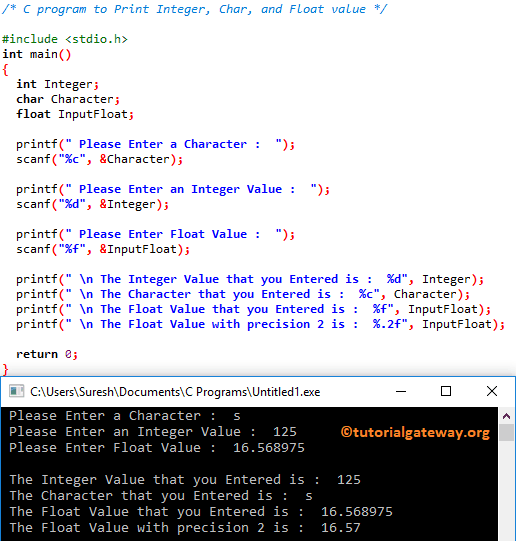
Best Practices for Using Floats
- Understand Precision Limits: Always be aware of the precision limitations of your chosen float type (single vs. double).
- Avoid Direct Equality Comparisons: Use a tolerance (epsilon) when comparing floats for equality.
- Be Mindful of Error Accumulation: In iterative calculations, small errors can compound. Consider strategies to mitigate this if precision is critical.
- Choose the Right Type: Select single-precision for general use when memory or speed is a concern and extreme precision isn’t vital. Opt for double-precision when accuracy is paramount.
- Consider Alternatives: If exact decimal representation is essential, explore fixed-point arithmetic or integer-based solutions.
In conclusion, the float data type is a cornerstone of modern programming, enabling the representation and manipulation of a vast spectrum of numerical values. By understanding its underlying mechanics, inherent limitations, and best practices, developers can leverage floats effectively to build robust and accurate applications across diverse domains.