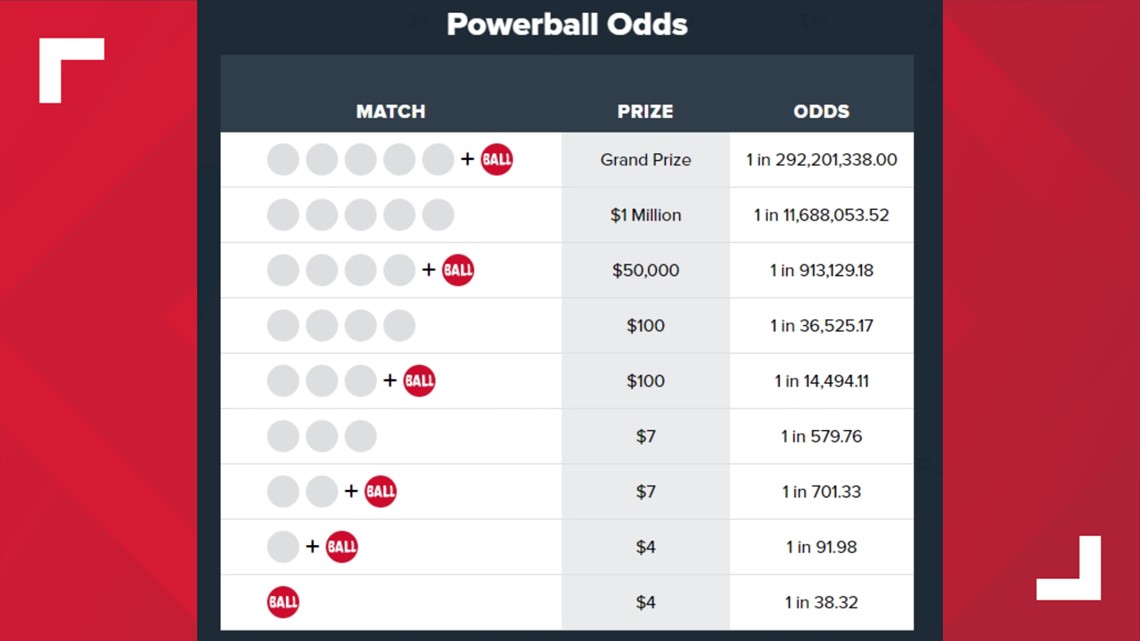
The allure of the Powerball lottery, with its astronomical jackpots, often leads enthusiasts and statisticians alike to ponder the ultimate question: are there certain numbers that appear more frequently than others? In an age dominated by data, algorithms, and advanced analytical tools, the quest to identify patterns in seemingly random events has never been more intense. While the essence of a lottery is pure chance, our innate human desire to find order drives innovative approaches to understand, if not predict, such systems. This exploration delves into the technological and analytical lens through which we can examine Powerball’s historical data, dissecting the true nature of randomness and the powerful, yet often limited, capabilities of data science in games of chance.

The Intricacies of Randomness and Probability
At its core, Powerball is a game designed around random selection. Understanding this fundamental principle is crucial before applying any advanced technological analysis. Each Powerball drawing is an independent event, meaning the outcome of previous draws has absolutely no bearing on the outcome of the next. The balls are identical in weight and size, mixed thoroughly, and drawn without human intervention, all designed to ensure maximum randomness. Yet, the human mind struggles with true randomness, often seeking patterns where none exist.
Dissecting True Randomness in Lottery Systems
True randomness implies that every possible combination of numbers has an equal probability of being drawn in any given event. For Powerball, this means that drawing 1-2-3-4-5 and Powerball 6 has the exact same probability as any other sequence, no matter how “unlikely” it might seem intuitively. The mechanics of the drawing process, using physical balls and a randomized selection machine, are engineered precisely to uphold this principle. Technologically, assessing true randomness involves rigorous statistical tests, such as chi-squared tests or runs tests, to ensure the observed frequencies of numbers do not significantly deviate from theoretical expectations over a large sample size. Any system or software claiming to find a “bias” in a properly functioning lottery mechanism is fundamentally misunderstanding or misrepresenting these statistical truths. Innovation in lottery analysis, therefore, lies not in predicting outcomes, but in precisely quantifying the absence of predictability and educating players on the underlying probabilities.
Human Biases: The Illusion of Pattern
The human brain is wired to detect patterns, a survival mechanism that has served us well throughout evolution. However, this same trait can lead to cognitive biases when confronted with random sequences. The “gambler’s fallacy” is a prime example, where individuals mistakenly believe that if a number hasn’t appeared recently, it’s “due” to come up, or conversely, if a number has appeared frequently, it’s “hot.” Similarly, people tend to avoid “overdue” or “cold” numbers, or gravitate towards “hot” ones, based on a flawed perception of probability. These biases influence number selection, leading many to pick combinations based on perceived trends rather than pure random choice. Leveraging technology in this domain means not just analyzing data, but also developing user interfaces and educational tools that present probabilistic information clearly, helping players overcome these ingrained psychological tendencies and make informed, rational decisions based on statistical realities, not superstition.
Harnessing Technology for Probabilistic Insights
While technology cannot predict truly random lottery draws, it can provide invaluable insights into historical data, helping us understand past frequencies and dispel common misconceptions. The application of big data analytics, sophisticated algorithms, and even machine learning techniques allows for comprehensive analysis of drawing histories, revealing patterns of past occurrences and confirming the persistent reign of randomness.
Big Data Analytics in Games of Chance
The Powerball lottery has a rich history of draws, generating a substantial dataset. This “big data” can be meticulously collected, stored, and processed using modern database management systems and cloud computing platforms. Advanced analytical tools, often found in business intelligence suites, can then be employed to query this data for various statistical metrics: frequency counts of individual numbers, pairs, triplets, sums, and even sequences. These tools allow for visualization of historical performance, making complex statistical information accessible. For instance, a data scientist might build a dashboard showing the exact count of each white ball and Powerball drawn since the lottery’s inception, comparing these observed frequencies against the expected theoretical probability. This data-driven approach doesn’t aim to predict the future, but rather to rigorously verify the fairness and randomness of the drawing process itself, reassuring players that the system is operating as intended and revealing any potential, albeit unlikely, mechanical biases.
Algorithmic Approaches to Frequency Analysis
Algorithms are at the heart of any systematic data analysis. For Powerball, simple frequency counting algorithms can quickly tabulate how many times each number (1-69 for white balls, 1-26 for the Powerball) has appeared. More complex algorithms can identify streaks, calculate standard deviations from expected frequencies, and even simulate millions of hypothetical future draws to demonstrate the long-term convergence to theoretical probabilities. These algorithms can be implemented in various programming languages, such as Python or R, leveraging statistical libraries to perform calculations efficiently on large datasets. The output might include charts ranking numbers from most to least frequent, or showing how their frequencies have evolved over time. This technological approach offers transparency, allowing anyone with the right tools to independently verify historical statistics rather than relying on anecdotal evidence or biased reporting.
Machine Learning: Predicting the Unpredictable?
The application of Machine Learning (ML) to lottery numbers presents an intriguing, yet often misunderstood, frontier. While ML excels at finding complex patterns in data to make predictions (e.g., in stock markets or customer behavior), its effectiveness hinges on the assumption that underlying patterns exist and are somewhat persistent. In a truly random system like Powerball, such patterns are deliberately absent. An ML model trained on historical Powerball data would essentially learn that past draws are independent of future draws. It might identify spurious correlations or temporary fluctuations, but it cannot genuinely predict the next random draw with any accuracy beyond pure chance. Nevertheless, ML could be innovatively used to:
- Detect anomalies: Identify if a drawing machine might be exhibiting a subtle mechanical bias over extended periods, an unlikely but technically possible scenario that rigorous testing would reveal.
- Model player behavior: Analyze common number choices (birthdays, anniversaries, perceived “lucky” numbers) to understand how human psychology influences ticket sales and potential prize splits, rather than predicting winning numbers.
- Educational simulations: Create ML-driven simulations that visually demonstrate the convergence of observed frequencies to theoretical probabilities over millions of draws, thereby educating players about randomness more effectively than static charts.
Thus, while ML won’t pick your winning numbers, it can serve as a powerful tool for deeper understanding and educational outreach regarding random processes.
Deep Dive into Powerball’s Historical Data
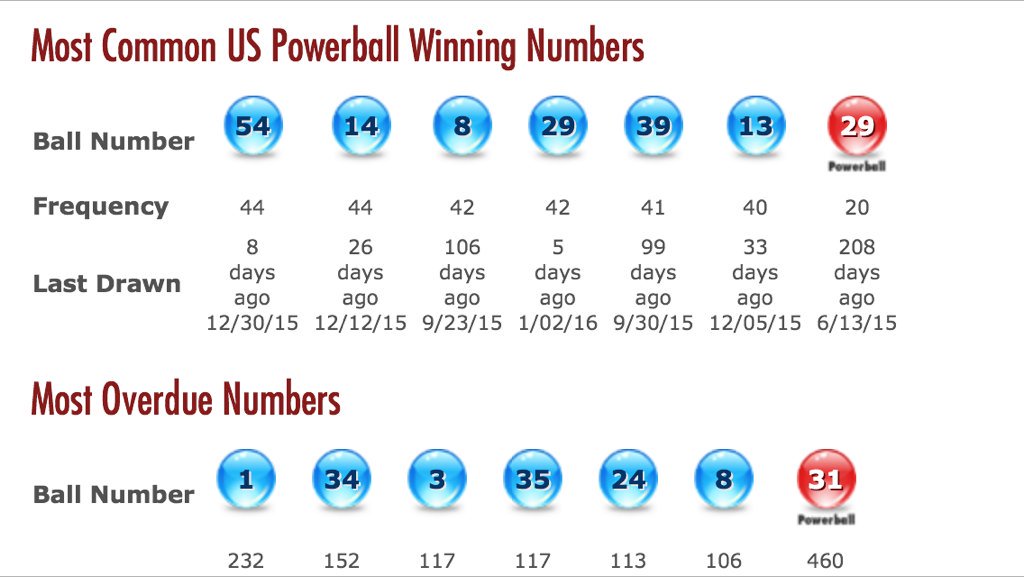
Analyzing historical Powerball data with tech tools provides fascinating insights, primarily confirming the robust randomness of the system. While no numbers are “more likely” to be drawn in the future, looking at past frequencies does show which numbers have appeared more often in previous draws. This distinction is crucial for understanding the data without falling prey to predictive fallacies.
White Ball Frequencies: A Closer Examination
When scrutinizing the white ball numbers (1 through 69), sophisticated data analytics platforms allow us to compile precise frequency counts over the entire history of Powerball. While individual numbers might show minor deviations from the perfectly even distribution expected over a finite number of draws, these are typically within the bounds of statistical noise for a truly random process. For example, a comprehensive dataset might reveal that, historically, “26” has been drawn slightly more often than “13,” but this observed difference is almost always statistically insignificant for prediction. Any number that appears “most common” is simply a temporary leader in a dynamic race where all numbers eventually tend towards an equal frequency over an infinite number of draws. This observation, confirmed by millions of simulated draws, underscores that these observed historical variations are simply artifacts of finite sampling, not indicators of future bias. Our analytical tools allow us to pinpoint these historical highs and lows, but crucially, also to perform statistical tests that confirm their randomness.
The Powerball Red Ball: Its Own Statistical Landscape
The red Powerball (1 through 26) is drawn from a separate drum, making its statistical analysis distinct from the white balls. Similarly, rigorous data analysis of its historical draws also reveals frequencies that, while showing temporary highs and lows for specific numbers, consistently adhere to the principles of randomness over the long term. A number like “24” might have appeared marginally more frequently than “1” over the past five years, but this doesn’t imbue “24” with any special predictive power for the next draw. Advanced visualization techniques can illustrate these historical distributions, showing how each Powerball number’s frequency ebbs and flows around the theoretical average over different time periods. This visual evidence, powered by robust data processing, helps demystify the draw process and reinforces the equal probability of all numbers being selected for the red ball in any given draw.
The Persistent Myth of “Hot” and “Cold” Numbers
One of the most enduring myths in lottery play is the concept of “hot” (frequently drawn) and “cold” (infrequently drawn) numbers. Our deep dive into historical data, powered by advanced statistical computing, systematically debunks this myth. Data models can quantify the deviation of observed frequencies from the expected average for all numbers. While some numbers will naturally appear more often and others less often in any finite set of drawings, these fluctuations are entirely consistent with random chance. There’s no statistical evidence to suggest that a “hot” number is more likely to be drawn again, nor that a “cold” number is “due” to appear. In fact, relying on such notions is an example of the gambler’s fallacy. The innovative application of data analytics here is not to find these “hot” or “cold” numbers for prediction, but to precisely measure their historical performance and statistically prove that their past frequency has no predictive power whatsoever for future draws, thereby guiding players away from misleading biases.
The Innovative Pursuit of Lottery Understanding
The technological exploration of Powerball numbers transcends mere curiosity; it’s an exercise in understanding complex systems, applying advanced data science to real-world phenomena, and promoting data literacy. This pursuit doesn’t aim to crack the code of randomness but to illuminate its mechanisms and implications.
Beyond Pure Chance: Strategic Number Selection (from a tech perspective)
While the probability of winning the Powerball jackpot remains astronomically low, and all number combinations have an equal chance of being drawn, technology can still inform strategic number selection—not to increase winning odds, but to potentially maximize payout if you do win. This innovation shifts focus from predicting the draw to analyzing human behavior. By processing large datasets of commonly picked numbers (e.g., birthdays, sequential numbers, previous winning combinations), algorithms can identify patterns of player selection. For example, if a significant number of players choose dates (numbers 1-31), selecting numbers outside this range could slightly reduce the chance of splitting a jackpot if those less common numbers are drawn. This isn’t about beating the lottery system, but about using data to play “smarter” in terms of potential prize distribution. Advanced demographic analysis tools could even segment player choices by region or age, offering deeper insights into collective human biases in number selection.
Ethical Considerations in Lottery Analysis
The ability to analyze vast amounts of lottery data with powerful technology brings with it ethical considerations. There’s a fine line between providing insightful statistical information and fostering false hope or encouraging excessive gambling. Developers of lottery analysis tools and content creators must prioritize transparency, clearly stating the limitations of statistical analysis in predicting random events. Innovation in this space means creating algorithms that robustly calculate probabilities and present them in an unbiased, educational manner, emphasizing that the lottery remains a game of chance. Ethical data practices also involve ensuring privacy if any player-specific data were ever to be collected for behavioral analysis, and preventing the misuse of data insights to exploit vulnerable individuals. The goal should always be to enhance understanding, not to mislead or manipulate.
The Future of Data-Driven Game Analysis
The landscape of data-driven analysis for games of chance is continuously evolving. As computing power increases and AI/ML models become more sophisticated, we can expect even more nuanced approaches to understanding complex probabilistic systems. This includes:
- Real-time anomaly detection: Advanced AI systems could monitor live draws for any micro-deviations from expected random patterns in real-time, although modern lottery machines are already highly secure and tested.
- Personalized educational dashboards: AI-powered platforms could offer tailored insights into how individual players’ number selection biases compare to broader trends, providing personalized feedback on probability and randomness.
- Cross-game statistical comparisons: Analyzing and comparing outcomes across various lotteries and games of chance worldwide to identify universal principles of randomness versus unique operational characteristics.
Ultimately, the innovative application of technology to Powerball numbers reaffirms the foundational principles of probability. While we can use powerful tools to analyze what has happened, the beauty and challenge of a truly random lottery system lie in the fact that its future remains impervious to even the most advanced technological prediction. The most common numbers for Powerball, historically, are simply a reflection of finite random samples, not a blueprint for future success.