Proteins are fundamental to life, acting as the workhorses of every biological system. From the enzymes that catalyze biochemical reactions to the structural components that provide cellular integrity, proteins are involved in virtually every process within an organism. Understanding their fundamental nature requires delving into the molecular architecture that gives them their diverse functions. At the heart of protein structure and function lie their fundamental building blocks: amino acids. These small organic molecules, when linked together in specific sequences and arrangements, assemble into the complex three-dimensional structures that define each unique protein.
The Monomeric Unit: Amino Acids
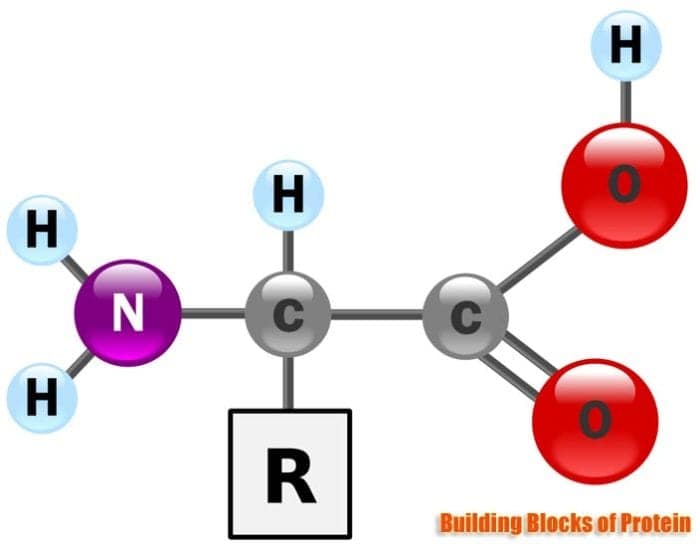
Amino acids are the indispensable monomers that polymerize to form proteins. There are twenty standard types of amino acids commonly found in proteins, each possessing a characteristic chemical structure that dictates its behavior and its contribution to the overall protein. The general structure of an amino acid consists of a central alpha-carbon atom bonded to four key groups:
The Core Structure
- An Amino Group (-NH2): This is a basic functional group that can accept a proton, making it positively charged at physiological pH.
- A Carboxyl Group (-COOH): This is an acidic functional group that can donate a proton, making it negatively charged at physiological pH.
- A Hydrogen Atom (-H): A simple hydrogen atom.
- A Side Chain (R-group): This is the defining feature of each amino acid. The R-group is a variable chemical substituent that distinguishes one amino acid from another. It can be as simple as a hydrogen atom (in glycine) or a complex aromatic ring system. The nature of the R-group is critical because it determines the amino acid’s chemical properties, such as its polarity, charge, size, and ability to participate in various chemical interactions.
Diversity of Amino Acid Side Chains
The R-groups are responsible for the vast diversity of amino acids and, consequently, the vast diversity of proteins. These side chains can be broadly categorized based on their chemical properties:
Nonpolar, Aliphatic Side Chains
These amino acids have R-groups that are hydrophobic (water-repelling). They tend to cluster together in the interior of a protein, away from the aqueous environment of the cell. Examples include:
- Glycine (Gly, G): The simplest amino acid, with an R-group of just a hydrogen atom. Its small size allows for flexibility in the protein backbone.
- Alanine (Ala, A): Has a methyl group (-CH3) as its R-group.
- Valine (Val, V): Features a branched aliphatic chain.
- Leucine (Leu, L) and Isoleucine (Ile, I): These are isomers with branched aliphatic side chains, larger and more hydrophobic than valine.
- Methionine (Met, M): Contains a sulfur atom in its side chain, making it relatively nonpolar and capable of participating in specific interactions.
- Proline (Pro, P): Unique among amino acids, proline’s side chain forms a cyclic structure that incorporates the alpha-amino group, creating a rigid bend in the polypeptide chain.
Polar, Uncharged Side Chains
These amino acids have R-groups that are hydrophilic (water-attracting) due to the presence of polar functional groups like hydroxyl (-OH), amide (-CONH2), or sulfhydryl (-SH). They can form hydrogen bonds with water and with other polar residues within a protein. Examples include:
- Serine (Ser, S): Contains a hydroxyl group.
- Threonine (Thr, T): Also possesses a hydroxyl group, but with a more complex branched structure.
- Cysteine (Cys, C): Has a sulfhydryl group (-SH) that can form disulfide bonds (-S-S-) with another cysteine residue. These covalent bonds are crucial for stabilizing protein structure.
- Tyrosine (Tyr, Y): Contains a phenolic hydroxyl group, making it slightly polar and capable of acting as a hydrogen bond donor and acceptor.
- Asparagine (Asn, N) and Glutamine (Gln, Q): These are the amides of aspartate and glutamate, respectively. Their amide groups can participate in hydrogen bonding.
Positively Charged (Basic) Side Chains
These amino acids have R-groups that are positively charged at physiological pH due to the presence of amino or guanidinium groups. Their positive charge allows them to interact with negatively charged molecules. Examples include:
- Lysine (Lys, K): Features an amino group in its side chain, which is protonated and positively charged at physiological pH.
- Arginine (Arg, R): Contains a guanidinium group, which is highly basic and always positively charged under physiological conditions.
- Histidine (His, H): Has an imidazole ring in its side chain. The pKa of the imidazole ring is close to physiological pH, meaning histidine can be either positively charged or neutral depending on its environment, making it a versatile residue in enzyme active sites.
Negatively Charged (Acidic) Side Chains
These amino acids have R-groups that are negatively charged at physiological pH due to the presence of carboxyl groups. Their negative charge allows them to interact with positively charged molecules. Examples include:
- Aspartate (Asp, D) and Glutamate (Glu, E): These are the deprotonated forms of aspartic acid and glutamic acid, respectively, each containing a carboxyl group that carries a negative charge at physiological pH.
The Polymerization Process: Peptide Bonds
Proteins are formed by linking amino acids together in a linear chain through a process called polymerization. This linkage occurs via a specific type of covalent bond called a peptide bond, formed between the carboxyl group of one amino acid and the amino group of another.

Formation of the Peptide Bond
The formation of a peptide bond is a dehydration synthesis reaction, meaning a molecule of water is released during the process. When the carboxyl group of amino acid A reacts with the amino group of amino acid B, a peptide bond forms between the alpha-carbon of A and the nitrogen of B, with the elimination of a water molecule.
- Amino Acid A (N-terminus): … – Cα – COOH
- Amino Acid B (C-terminus): H2N – Cα – …
Upon reaction:
- Dipeptide: … – Cα – CO – NH – Cα – … + H2O
The resulting molecule, composed of two amino acids linked by a peptide bond, is called a dipeptide. As more amino acids are added in this manner, a long chain called a polypeptide is formed. Each polypeptide chain has a designated N-terminus (the end with a free amino group) and a C-terminus (the end with a free carboxyl group). The sequence of amino acids in this polypeptide chain is called the primary structure of the protein and is absolutely critical for its final three-dimensional form and function.
The Polypeptide Backbone
The repeating sequence of atoms along the polypeptide chain, consisting of the nitrogen atom from the amino group, the alpha-carbon, and the carbonyl carbon from the carboxyl group, forms the polypeptide backbone. The R-groups of the amino acids project outwards from this backbone, dictating the protein’s higher-order structures and interactions. While the peptide bond itself is planar and has some partial double-bond character, leading to restricted rotation around it, there is rotation around the bonds connecting the alpha-carbon to the amino nitrogen and to the carboxyl carbon. This rotational freedom allows the polypeptide chain to fold into complex three-dimensional shapes.
From Chains to Functional Proteins: Levels of Protein Structure
The linear sequence of amino acids, the primary structure, is just the beginning. The inherent chemical properties of the amino acid side chains, coupled with the physical constraints of the polypeptide backbone, drive the folding of the protein into specific, functional three-dimensional structures. These structures are typically described at four hierarchical levels:
Primary Structure
As mentioned, this is the linear sequence of amino acids in a polypeptide chain, determined by the genetic code. Even a single amino acid change in this sequence can dramatically alter the protein’s properties, sometimes leading to disease (e.g., sickle cell anemia, caused by a single amino acid substitution in hemoglobin).
Secondary Structure
This level describes the local folding patterns of the polypeptide backbone, stabilized by hydrogen bonds formed between backbone atoms. The two most common types of secondary structure are:
- Alpha-helix (α-helix): A coiled, helical structure where the carbonyl oxygen of one amino acid forms a hydrogen bond with the amide hydrogen of an amino acid four residues further down the chain. This creates a stable, rod-like structure.
- Beta-sheet (β-sheet): Formed by segments of the polypeptide chain lying parallel or antiparallel to each other, with hydrogen bonds forming between the carbonyl oxygen of one strand and the amide hydrogen of an adjacent strand. This creates a pleated, sheet-like structure.
Tertiary Structure
This refers to the overall three-dimensional shape of a single polypeptide chain. It is determined by interactions between the R-groups of amino acids that may be far apart in the linear sequence. These interactions include:
- Hydrogen bonds: Between polar R-groups.
- Ionic bonds: Between oppositely charged R-groups.
- Hydrophobic interactions: Nonpolar R-groups cluster together to minimize contact with water.
- Disulfide bonds: Covalent bonds formed between the sulfur atoms of two cysteine residues, providing significant stability.
- Van der Waals forces: Weak, transient attractions between atoms.
The precise tertiary structure is crucial for a protein’s function, as it creates specific binding sites, active sites for enzymes, and surfaces for interaction with other molecules.

Quaternary Structure
This level applies only to proteins composed of more than one polypeptide chain (subunits). Quaternary structure describes the arrangement and interaction of these multiple subunits to form a functional protein complex. The same types of interactions that stabilize tertiary structure are involved in holding the subunits together. For example, hemoglobin, the oxygen-carrying protein in red blood cells, is a tetramer composed of four subunits.
In conclusion, proteins are intricately built from a diverse set of amino acid building blocks, linked together by peptide bonds. The sequence of these amino acids dictates how the polypeptide chain will fold, leading to complex three-dimensional structures essential for life’s myriad functions. Understanding the chemical nature of amino acids and the principles of protein folding is key to appreciating the elegance and power of biological molecular machinery.