Python’s elegant design and rich ecosystem of data structures make it a powerhouse for developing cutting-edge technologies, from artificial intelligence to autonomous systems. Among its fundamental data types, the set stands out as a powerful, yet often underutilized, tool for managing collections of unique items efficiently. Understanding the intricacies of Python sets is crucial for any developer aiming to build robust, performant, and intelligent applications, particularly in fields demanding high data integrity and quick operations, such as those within advanced tech and innovation.
The Foundation of Uniqueness: Introducing Python Sets
At its core, a Python set is an unordered collection of unique elements. This simple definition belies its profound utility. Imagine a mathematical set: a collection of distinct objects where the order in which they are listed doesn’t matter, and no object appears more than once. Python’s set type directly mirrors this mathematical concept, providing a highly optimized way to store and manipulate such collections within a program.
Unlike lists or tuples, which can contain duplicate values and maintain an explicit order, sets are inherently designed for membership testing, removing duplicates, and performing standard mathematical set operations like unions, intersections, and differences with remarkable speed. This makes them indispensable when the primary concern is the presence or absence of a specific item, or when ensuring data integrity by eliminating redundancy. For developers working on systems that process large volumes of sensor data, manage unique identifiers for networked devices, or filter distinct features for machine learning models, the efficiency offered by sets can translate directly into more responsive and reliable applications. Their underlying implementation, typically using hash tables, grants them average-case O(1) time complexity for many common operations, a significant advantage over sequence types when dealing with large datasets.
Core Characteristics and Essential Operations
To harness the full potential of Python sets, a thorough understanding of their defining characteristics and the operations they support is essential. These properties dictate when and where sets are the optimal choice for data management.
Creating Sets
Sets can be created in a few straightforward ways. The most common method involves using curly braces {} with comma-separated elements, or by using the set() constructor. An important nuance is that an empty set must be created using set(), as {} creates an empty dictionary.
# Creating a set with elements
unique_ids = {101, 105, 102, 105, 103}
print(unique_ids) # Output: {101, 102, 103, 105} (order may vary)
# Creating a set from a list, automatically removing duplicates
sensor_readings = [25.5, 26.1, 25.5, 27.0, 26.1]
distinct_readings = set(sensor_readings)
print(distinct_readings) # Output: {25.5, 26.1, 27.0} (order may vary)
# Creating an empty set
empty_set = set()
Notice how duplicates (105 in unique_ids and 25.5, 26.1 in distinct_readings) are automatically discarded, reinforcing the set’s commitment to uniqueness.
Adding and Removing Elements
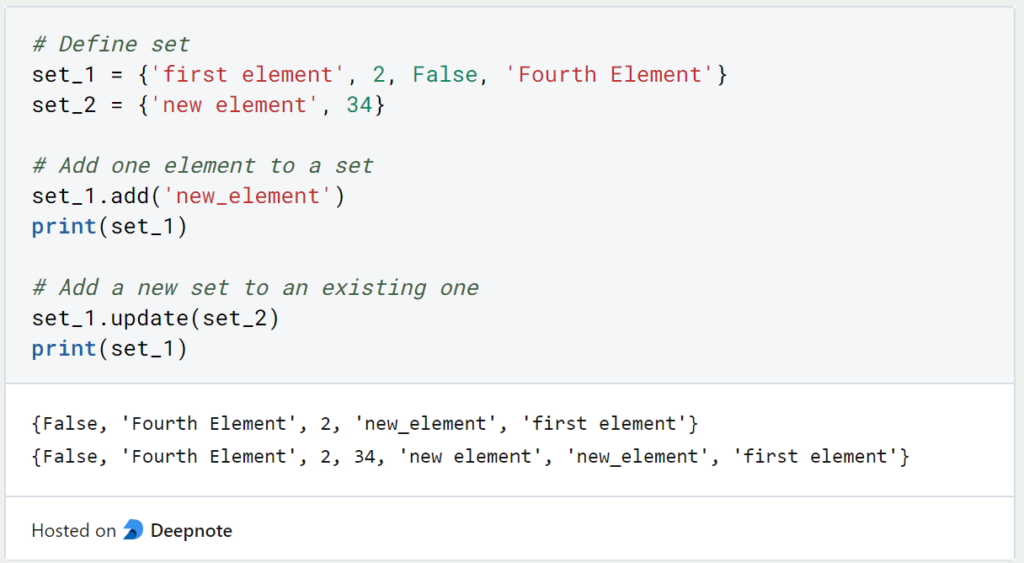
Sets are mutable, meaning elements can be added or removed after creation. The add() method is used to include a single element, while update() can add multiple elements from an iterable. For removal, remove() will delete a specified element and raise a KeyError if it’s not found, whereas discard() will remove an element if present, but do nothing if it’s not. The pop() method removes and returns an arbitrary element, and clear() empties the set entirely.
active_sensors = {'GPS', 'IMU'}
active_sensors.add('LiDAR')
print(active_sensors) # Output: {'IMU', 'GPS', 'LiDAR'}
new_sensors = ['Camera', 'LiDAR', 'Thermal']
active_sensors.update(new_sensors)
print(active_sensors) # Output: {'IMU', 'Thermal', 'GPS', 'LiDAR', 'Camera'}
active_sensors.remove('GPS')
print(active_sensors) # Output: {'IMU', 'Thermal', 'LiDAR', 'Camera'}
active_sensors.discard('Sonar') # No error, 'Sonar' not in set
print(active_sensors) # Output: {'IMU', 'Thermal', 'LiDAR', 'Camera'}
popped_sensor = active_sensors.pop()
print(f"Removed: {popped_sensor}, Remaining: {active_sensors}")
<p style="text-align:center;"><img class="center-image" src="https://blog.finxter.com/wp-content/uploads/2021/02/set-1-scaled.jpg" alt=""></p>
active_sensors.clear()
print(active_sensors) # Output: set()
These methods provide granular control over the set’s contents, allowing for dynamic management of unique items in real-time applications.
Set Operations: The Power of Mathematical Logic
Python sets excel at performing high-level mathematical set operations, which are fundamental in many algorithmic and data processing tasks.
- Union (
|orunion()): Combines all unique elements from both sets.
python
set_a = {1, 2, 3}
set_b = {3, 4, 5}
union_set = set_a | set_b
# Output: {1, 2, 3, 4, 5}
- Intersection (
&orintersection()): Returns elements common to both sets.
python
intersection_set = set_a & set_b
# Output: {3}
- Difference (
-ordifference()): Returns elements in the first set but not in the second.
python
difference_set = set_a - set_b
# Output: {1, 2}
- Symmetric Difference (
^orsymmetric_difference()): Returns elements that are in either set, but not in both.
python
symmetric_diff_set = set_a ^ set_b
# Output: {1, 2, 4, 5}
These operations are incredibly efficient for large sets, making them ideal for tasks like identifying unique sensor faults across different systems, comparing configurations, or consolidating disparate data sources in complex intelligent systems.
Why Use Sets? Advantages in Modern Tech
The unique characteristics of Python sets offer significant advantages, making them particularly valuable for developing sophisticated and efficient applications in the realm of tech and innovation.
Efficiency for Membership Testing
One of the most compelling reasons to use a set is its unparalleled efficiency in checking for the existence of an element. Due to their hash-based implementation, checking if an item is in a set takes, on average, constant time (O(1)), regardless of the set’s size. This contrasts sharply with lists, where membership testing requires iterating through elements, leading to O(n) time complexity in the worst case.
Consider a scenario in autonomous navigation systems where a drone needs to quickly determine if a detected object ID is on a blacklist of no-fly zones or restricted airspace identifiers. With a list of millions of IDs, this check would be a performance bottleneck. With a set, the check is nearly instantaneous. This efficiency is critical for real-time decision-making, where milliseconds can impact safety and operational success.
Data Cleaning and Uniqueness
Sets provide an incredibly simple and efficient mechanism for removing duplicate entries from a collection of data. This is invaluable in data-intensive applications like remote sensing, environmental monitoring, or large-scale mapping projects, where sensor readings or gathered data points might contain redundant entries due to measurement overlaps or system glitches.
By converting a list of raw data into a set, all duplicates are automatically purged, yielding a clean collection of unique data points. This preprocessing step ensures that subsequent analyses, calculations, or machine learning models operate on accurate, non-redundant data, improving the reliability and precision of the insights derived. For example, consolidating unique GPS waypoints from multiple flight logs or identifying distinct feature types detected by computer vision algorithms can be streamlined using sets.
Advanced Algorithmic Design
Sets are not just for basic data management; they are foundational for implementing advanced algorithms that rely on principles of uniqueness, intersection, and difference. Graph algorithms, for instance, might use sets to track visited nodes efficiently. Recommender systems could use set operations to find commonalities or differences in user preferences. Furthermore, in fields like cybersecurity or network management, sets can be used to quickly identify unique IP addresses, detect anomalous data packets, or manage access control lists.
The ability to perform high-speed set operations allows developers to craft elegant and performant solutions to complex problems that would be significantly more challenging or less efficient using other data structures. This direct mapping to mathematical set theory empowers developers to translate abstract logical requirements into practical, optimized code.
Practical Applications in Tech & Innovation
In the dynamic landscape of tech and innovation, Python sets find numerous applications, quietly underpinning the functionality of many advanced systems. Their strengths in managing uniqueness and performing rapid comparisons make them indispensable.
Managing System States and Identifiers
In complex systems, such as those controlling multiple drone components or managing a fleet of autonomous vehicles, tracking unique active states or identifiers is crucial. A set can store the currently active sensors ({'GPS', 'IMU', 'Camera'}) or the unique IDs of drones currently in flight. This allows for quick checks: Is ‘LiDAR’ an active sensor? Is ‘DroneX’ currently airborne? These checks are fast and resilient to duplicate entries, ensuring the system state remains consistent. Similarly, managing unique error codes or warning flags in an incident log benefits from set properties, allowing for quick aggregation of distinct issues.
Data Validation and Filtering
When processing data streams from various sources—be it telemetry data from a drone, sensor readings from an IoT device, or user inputs in an AI application—data validation is paramount. Sets can be employed to define a whitelist or blacklist of acceptable values. For instance, a set of valid command keywords for an autonomous system ensures that only authorized instructions are processed. Any incoming command not present in the set can be flagged as invalid, enhancing system security and reliability. This is particularly useful for filtering noise or malicious inputs in real-time operational environments.
Efficient Resource Allocation
In cloud computing or distributed systems, resource management often involves allocating unique identifiers or tasks to available processors or agents. Sets can facilitate this by maintaining a pool of available resources (e.g., {'CPU_core_1', 'GPU_unit_A'}) and active allocations. When a resource is assigned, it’s removed from the ‘available’ set and added to an ‘allocated’ set. This allows for rapid checks on resource availability and prevents double allocation, which is critical for maintaining system performance and avoiding conflicts.
Anomaly Detection and Pattern Recognition
In the context of machine learning and data analysis, particularly for remote sensing or predictive maintenance, sets can assist in anomaly detection. By comparing unique patterns or feature sets derived from real-time data against a baseline set of ‘normal’ patterns, significant differences (using set difference operations) can highlight unusual events or potential malfunctions. For example, if a set of unique data signatures from a drone’s propulsion system deviates significantly from the typical operational signature set, it could indicate an impending failure, triggering an alert for proactive maintenance.
In summary, while “what is set in Python” might appear to be a fundamental programming question, its implications extend deeply into the architecture and performance of modern technological innovations. The humble set, with its guarantee of uniqueness and efficient operations, is a quiet workhorse in the toolkit of any developer striving to build sophisticated, robust, and intelligent systems for the future.