Cardinality, in the context of a Database Management System (DBMS), refers to a fundamental concept that describes the uniqueness of data values within a column or a set of columns. It quantifies the number of distinct or unique values that a particular attribute can hold. Understanding cardinality is crucial for database design, performance optimization, and data integrity. It influences how data is stored, indexed, and queried, ultimately impacting the efficiency and scalability of any database application.
Understanding Cardinality: A Deeper Dive
At its core, cardinality helps us understand the nature of the relationship between different attributes in a database. It’s not merely about counting values; it’s about understanding the variety and uniqueness of those values. This distinction is critical because it dictates how we can effectively model our data and leverage database features.
Types of Cardinality
Cardinality can be broadly categorized into two main types:
High Cardinality
A column is said to have high cardinality if it contains a large number of unique values relative to the total number of rows in the table. Think of columns like unique identifiers, timestamps, or email addresses. In a table with a million rows, a column with 900,000 unique values would be considered high cardinality.
Characteristics of High Cardinality Columns:
- Many Distinct Values: The number of unique values is close to the total number of rows.
- Uniqueness is Key: The primary purpose of these columns is often to distinguish one record from another.
- Indexing Benefits: High cardinality columns are excellent candidates for indexing. Indexes on such columns can significantly speed up data retrieval because they allow the database to quickly pinpoint specific rows without scanning the entire table. For example, searching for a specific
user_idororder_numberbenefits greatly from an index on these columns. - Query Performance: Queries that filter or join on high cardinality columns can be very efficient if properly indexed. However, without proper indexing, they can lead to full table scans and poor performance, especially in large tables.
- Data Compression Challenges: High cardinality data can sometimes be more challenging to compress effectively, as there’s less redundancy.
Examples of High Cardinality:
CustomerIDin anOrderstable (assuming each order has a unique customer ID).EmailAddressin aUserstable.TransactionIDin aTransactionstable.IPAddressin a web server log.Timestampof an event.
Low Cardinality
Conversely, a column is considered to have low cardinality if it contains a small number of unique values relative to the total number of rows. Examples include gender, boolean flags (true/false), or status codes. In a table with a million rows, a column with only 5 unique values would be considered low cardinality.
Characteristics of Low Cardinality Columns:
- Few Distinct Values: The number of unique values is significantly less than the total number of rows.
- Repetitive Values: Values in these columns tend to repeat frequently across many rows.
- Indexing Considerations: While indexing can still be beneficial for low cardinality columns, the impact is often less dramatic than with high cardinality columns. Databases might employ different indexing strategies for low cardinality data. For instance, a B-tree index on a low cardinality column might not be as efficient as other methods if the number of unique values is extremely small (e.g., only 2 or 3).
- Query Performance: Queries filtering on low cardinality columns can be optimized by the database’s query planner. The planner can often use the limited number of distinct values to its advantage. For example, a query filtering by
Gender = 'Female'in a largeCustomerstable can quickly narrow down the results because the database knows there are only two possible values. - Data Compression Opportunities: Low cardinality data is generally more amenable to compression techniques due to the high degree of repetition.
Examples of Low Cardinality:
Genderin aCustomerstable (‘Male’, ‘Female’, ‘Other’).IsActive(boolean: True/False) in aUserstable.OrderStatusin anOrderstable (‘Pending’, ‘Shipped’, ‘Delivered’, ‘Cancelled’).CountryCodein aAddressestable (if the dataset is heavily skewed towards a few countries).ProductCategoryin aProductstable.
The Cardinality Ratio
Beyond classifying individual columns, cardinality also describes the relationship between tables, often referred to as the cardinality ratio. This specifies how many records in one table can be related to records in another table. The common types are:
- One-to-One (1:1): Each record in Table A can be related to at most one record in Table B, and vice versa.
- Example: A
Employeestable and anEmployeeDetailstable, where each employee has exactly one set of detailed personal information.
- Example: A
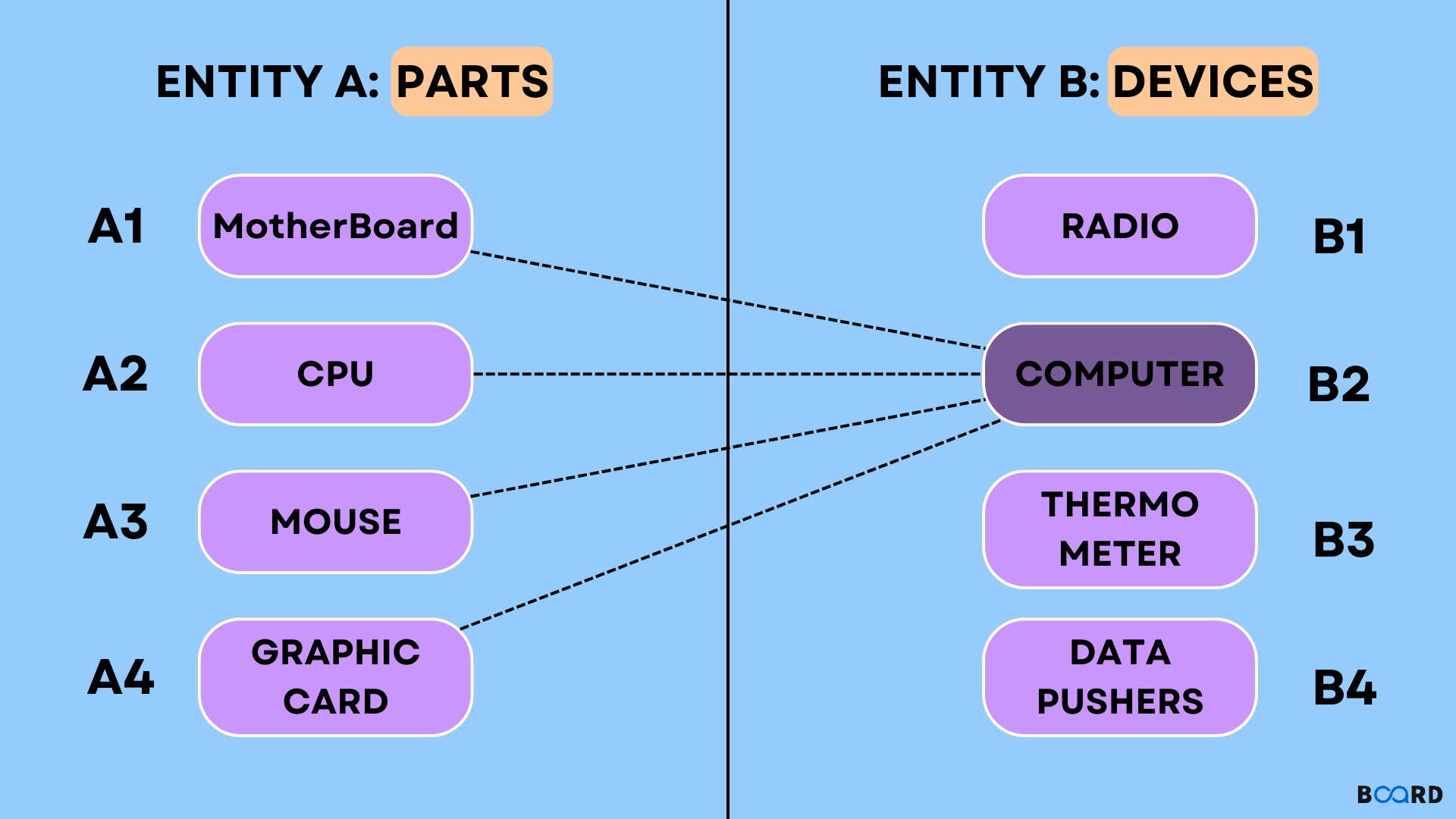
- One-to-Many (1:N): Each record in Table A can be related to many records in Table B, but each record in Table B can be related to at most one record in Table A.
- Example: A
Customerstable and anOrderstable. One customer can place many orders, but each order belongs to only one customer.
- Example: A
- Many-to-One (N:1): This is the inverse of One-to-Many. Each record in Table A can be related to at most one record in Table B, while each record in Table B can be related to many records in Table A.
- Example: An
Orderstable and aCustomerstable. Each order belongs to one customer, but a customer can have many orders.
- Example: An
- Many-to-Many (M:N): Each record in Table A can be related to many records in Table B, and each record in Table B can be related to many records in Table A. This type of relationship is typically implemented using an intermediary “junction” or “linking” table.
- Example: A
Studentstable and aCoursestable. A student can enroll in many courses, and a course can have many students enrolled. The junction table would beStudentCourses, linkingStudentIDandCourseID.
- Example: A

The Importance of Cardinality in Database Design and Performance
Understanding and managing cardinality is not an academic exercise; it has tangible impacts on the functionality and efficiency of your database.
Database Design and Normalization
Cardinality plays a vital role in the process of database normalization. Normalization aims to reduce data redundancy and improve data integrity by organizing data into tables in a way that ensures dependencies are correctly enforced.
- Identifying Redundancy: Low cardinality columns might indicate opportunities for creating separate tables or using lookup tables. For instance, if a
Productstable has aColorcolumn with only a few distinct values, it might be more efficient to create a separateColorstable and link it to theProductstable using a foreign key. This avoids repeating color names and simplifies updates. - Defining Relationships: As discussed, the cardinality ratio (1:1, 1:N, M:N) is fundamental to defining how tables relate to each other. Correctly identifying these relationships is paramount for building a robust and logical database schema.
- Primary and Foreign Keys: Cardinality influences the choice of primary keys (columns that uniquely identify rows) and foreign keys (columns that link to primary keys in other tables). High cardinality columns are often good candidates for primary keys.
Indexing Strategies
The effectiveness of database indexes is heavily dependent on the cardinality of the columns they are applied to.
- High Cardinality & Indexing: Indexes on high cardinality columns are generally highly effective. They create a sorted structure that allows the database to quickly locate specific values, drastically reducing the number of rows that need to be examined for a query. Without an index on a high cardinality column used in a
WHEREclause, the database would have to perform a full table scan, which is computationally expensive for large tables. - Low Cardinality & Indexing: Indexing low cardinality columns can still be beneficial, but their effectiveness varies.
- B-Tree Indexes: For columns with a moderate number of distinct values (e.g., 100s or 1000s in a large table), standard B-tree indexes can provide good performance gains.
- Index Selectivity: The term “selectivity” refers to how well an index can narrow down the search results. High cardinality columns typically have high selectivity. Low cardinality columns have low selectivity. If a low cardinality column has only a handful of unique values (e.g., two), an index might not be very helpful because selecting one of those values will still return a very large percentage of the table. In such cases, the query optimizer might decide it’s faster to scan the table.
- Specialized Indexes: Some database systems offer specialized indexing techniques for low cardinality data, such as bitmap indexes, which can be more efficient for columns with very few distinct values.
Query Optimization
Database query optimizers use cardinality information to make intelligent decisions about how to execute SQL queries efficiently.
- Join Operations: When joining two tables, the optimizer considers the cardinality of the join columns. If a join is performed on a high cardinality column, the optimizer might favor algorithms that can quickly find matching rows. If the join is on a low cardinality column, it might explore different join strategies.
- Filter Predicates: When a
WHEREclause filters a table on a particular column, the optimizer estimates how many rows will be returned based on the column’s cardinality. This estimate influences the execution plan. For example, if a query filters on a low cardinality column that returns a large portion of the table, the optimizer might decide that a full table scan is more efficient than using an index. - Cardinality Estimation Errors: Inaccurate cardinality estimates can lead to suboptimal query plans and poor performance. This can happen with outdated statistics or complex data distributions. Regularly updating database statistics is crucial for accurate cardinality estimation.
Data Integrity and Quality
Cardinality also contributes to maintaining the quality and integrity of data.
- Constraint Enforcement: Unique constraints, which are enforced by primary keys and unique indexes, directly rely on the concept of high cardinality to ensure that no duplicate values exist in specified columns.
- Data Validation: Understanding the expected cardinality of a column can help in implementing data validation rules. For instance, if a
CountryCodecolumn is expected to have only a few distinct values based on the application’s scope, an unusually high number of distinct values might indicate an data entry error.
Practical Implications and Best Practices
Leveraging the understanding of cardinality in a DBMS leads to more robust, performant, and scalable database systems.
Analyzing Cardinality
- Database Tools: Most DBMS provide tools or functions to analyze the cardinality of columns. For example, in SQL Server, you can query
sys.dm_db_index_physical_statsor useDBCC SHOW_STATISTICS. In PostgreSQL and MySQL, you can useCOUNT(DISTINCT column_name)or query the information schema. - Execution Plans: Examining the execution plan of a query is a powerful way to understand how the database is interpreting cardinality and making decisions.

Optimizing for Cardinality
- Indexing:
- Index columns with high cardinality that are frequently used in
WHEREclauses,JOINconditions, andORDER BYclauses. - Be cautious with indexing very low cardinality columns (e.g., only 2-3 distinct values). Analyze the query patterns and consider alternatives if standard indexes aren’t providing significant gains.
- Consider composite indexes (indexes on multiple columns) for queries that filter or join on combinations of columns. The cardinality of the composite index matters.
- Index columns with high cardinality that are frequently used in
- Schema Design:
- Use lookup tables for low cardinality attributes to reduce redundancy and simplify maintenance.
- Ensure that foreign key relationships accurately reflect the intended cardinality ratios between tables.
- Query Tuning:
- Write queries that take advantage of indexed columns.
- Avoid using functions on indexed columns in
WHEREclauses, as this can prevent the index from being used (e.g.,WHERE UPPER(column_name) = 'VALUE'instead ofWHERE column_name = 'value'). - Regularly update database statistics to ensure the query optimizer has accurate cardinality estimates.
- Data Archiving and Partitioning: For very large tables, consider partitioning strategies based on cardinality or time. For example, partitioning a
Logstable by date can improve query performance if queries often target specific date ranges.
In conclusion, cardinality is a cornerstone concept in database management. By understanding the distinctness of data within columns and the relationships between tables, database professionals can design more efficient schemas, implement effective indexing strategies, optimize query performance, and ultimately build more reliable and scalable applications. It’s a concept that, while seemingly simple, has profound implications for the entire lifecycle of data within a DBMS.