OpenMP (Open Multi-Processing) is an industry-standard API for parallel computing. It is a set of compiler directives, library routines, and environment variables that allow programmers to easily exploit shared-memory parallelism in C, C++, and Fortran applications. For the realm of cutting-edge technology, particularly in areas like advanced drone navigation, complex imaging processing for aerial surveys, and sophisticated AI-driven flight control, understanding and leveraging parallel processing capabilities is paramount. OpenMP provides a powerful yet accessible framework for developers to harness the power of multi-core processors, enabling faster and more efficient execution of computationally intensive tasks that are at the heart of modern technological advancements.

The Foundation of Parallelism: Shared Memory and Threads
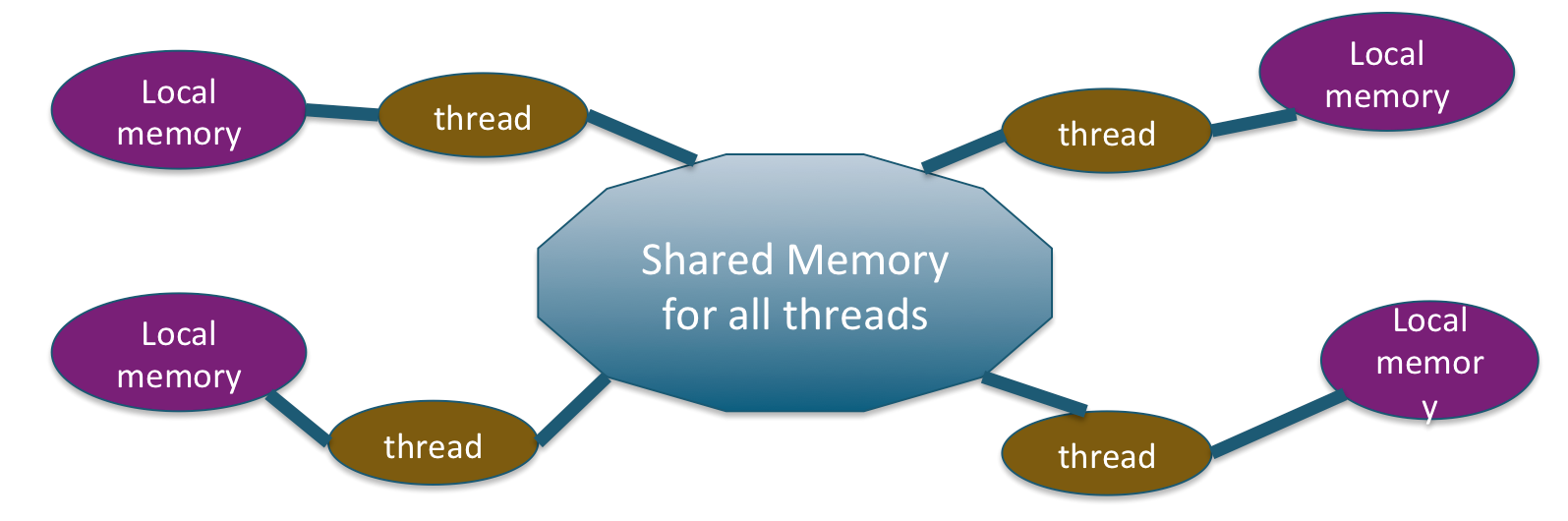
At its core, OpenMP is designed to work with shared-memory multiprocessing systems. This means that multiple processors (or cores within a single processor) can access and manipulate the same memory space. This is a common architecture in modern computing, including the processors found in advanced drone flight controllers, ground control stations, and the servers used for data processing from aerial platforms.
Understanding Threads
The fundamental unit of execution in OpenMP is the thread. A thread is essentially a lightweight process that can run concurrently with other threads within the same program. In a shared-memory environment, threads can communicate and share data by reading and writing to the same memory locations. OpenMP simplifies the process of creating and managing these threads.
The Role of the Parallel Region
The cornerstone of OpenMP programming is the parallel region. This is a block of code that is designated to be executed by a team of threads. When the program encounters a parallel region, it automatically creates a team of threads. All threads in the team execute the code within the parallel region. By default, this execution is “fork-join” parallelism: the master thread forks off a team of worker threads, all threads execute the parallel region, and then the worker threads join back, with execution continuing with only the master thread.
#include <iostream>
#include <omp.h> // Include the OpenMP header
int main() {
#pragma omp parallel // This directive defines a parallel region
{
// Code within this block will be executed by multiple threads
int thread_id = omp_get_thread_num();
int num_threads = omp_get_num_threads();
std::cout << "Hello from thread " << thread_id << " out of " << num_threads << std::endl;
} // End of parallel region - threads join here
return 0;
}
In this simple example, the #pragma omp parallel directive tells the compiler to execute the subsequent code block in parallel. Each thread will print a message indicating its unique ID and the total number of threads participating.
Implicit vs. Explicit Parallelism
OpenMP offers both implicit and explicit parallel constructs. Implicit parallelism often involves automatic parallelization of loops by the compiler based on directives. Explicit parallelism, as seen in the parallel directive, gives the programmer more direct control over the parallel execution of code sections. This fine-grained control is crucial for optimizing performance in complex algorithms used in drone operations.
Key OpenMP Constructs for Performance Optimization
OpenMP provides a rich set of directives and clauses that allow programmers to precisely control how parallelism is applied and how data is managed across threads. This level of control is essential for squeezing maximum performance out of multi-core processors, which is often a requirement for real-time processing of sensor data, complex simulations, or advanced path planning for autonomous drones.
Work-Sharing Constructs
Work-sharing constructs are used to divide the work of a parallel region among the threads in a team.
The #pragma omp for Directive
The #pragma omp for directive (or #pragma omp do in Fortran) is used to distribute the iterations of a loop among the threads. This is one of the most common and powerful work-sharing constructs.
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
const int size = 1000;
std::vector<int> data(size);
// Initialize data
for (int i = 0; i < size; ++i) {
data[i] = i;
}
// Parallel loop execution
#pragma omp parallel for
for (int i = 0; i < size; ++i) {
data[i] *= 2; // Each thread processes a portion of the loop iterations
}
// Verify a few elements
std::cout << "data[0]: " << data[0] << std::endl;
std::cout << "data[999]: " << data[999] << std::endl;
return 0;
}
In this example, the loop iterations are automatically divided among the threads in the parallel region. Each thread will execute a subset of the loop’s iterations, performing the multiplication. The schedule clause can be used to control how iterations are assigned to threads (e.g., static, dynamic, guided).
Other Work-Sharing Constructs
#pragma omp sections: Allows different threads to execute different sections of code concurrently. This is useful when tasks are not easily divisible into loop iterations.#pragma omp single: Specifies a block of code that should be executed by only one thread in the team. This is often used for initialization or finalization tasks that do not need to be replicated.
Synchronization Constructs
When threads share data, there’s a risk of race conditions, where the outcome of the program depends on the unpredictable timing of thread execution. Synchronization constructs are used to ensure that threads access shared data in a controlled manner.
The #pragma omp critical Directive
The #pragma omp critical directive ensures that only one thread at a time can execute a specific section of code. This is useful for protecting shared resources from concurrent access.
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
int shared_counter = 0;
#pragma omp parallel num_threads(4) // Explicitly set number of threads
{
#pragma omp for
for (int i = 0; i < 100; ++i) {
#pragma omp critical // Only one thread can update shared_counter at a time
{
shared_counter++;
}
}
}
std::cout << "Final counter value: " << shared_counter << std::endl;
return 0;
}
Here, even though multiple threads are incrementing shared_counter, the critical section ensures that the increment operation is atomic, preventing race conditions and guaranteeing the correct final count.
The #pragma omp atomic Directive
The #pragma omp atomic directive provides a more fine-grained mechanism for ensuring atomicity for specific operations, such as simple updates to a shared variable. It’s often more efficient than a critical section for such operations.
Locks
OpenMP provides explicit lock mechanisms (omp_set_lock, omp_unset_lock) for more complex synchronization scenarios.
Data Environment Clauses: Managing Shared and Private Data
A crucial aspect of parallel programming is managing how data is accessed and modified by different threads. OpenMP’s data environment clauses allow developers to explicitly define whether variables are shared among all threads or private to individual threads. This control is vital for preventing unintended side effects and ensuring data integrity, especially in applications dealing with large datasets like 3D mapping from drone imagery.
shared Clause
The shared clause indicates that a variable is accessible by all threads in the parallel region. This is often the default behavior for variables declared outside the parallel construct.
private Clause
The private clause declares a variable such that each thread in the parallel region gets its own private copy of the variable. Updates to a private variable by one thread do not affect the copies owned by other threads.
#include <iostream>
#include <omp.h>
int main() {
int shared_var = 10;
#pragma omp parallel private(shared_var) // Each thread gets its own copy of shared_var
{
shared_var = omp_get_thread_num() + 100; // Modifying private copy
std::cout << "Thread " << omp_get_thread_num() << ": shared_var = " << shared_var << std::endl;
}
std::cout << "Outside parallel region: shared_var = " << shared_var << std::endl; // Original value remains
return 0;
}
In this scenario, each thread modifies its own shared_var. The original shared_var outside the parallel region remains unchanged. This is essential when a loop variable is used within a parallel loop, ensuring each thread has its own iteration counter.
firstprivate Clause
The firstprivate clause is similar to private, but each thread’s private copy is initialized with the value of the variable from before the parallel region.
lastprivate Clause
The lastprivate clause ensures that the value of the variable from the last iteration of a loop (or the last executed statement in a sections construct) is copied back to the original variable outside the parallel region. This is useful when the final result of a parallel computation needs to be propagated back.
reduction Clause
The reduction clause is extremely powerful for performing aggregate operations (like sum, product, min, max) on a variable across multiple threads. Each thread computes its local reduction, and then OpenMP combines these local results to produce the final global result. This avoids the need for explicit synchronization around each update to the aggregate variable, significantly improving performance.
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
const int size = 1000;
std::vector<int> numbers(size);
for (int i = 0; i < size; ++i) {
numbers[i] = i + 1;
}
int sum = 0;
#pragma omp parallel for reduction(+:sum) // Perform a sum reduction on 'sum'
for (int i = 0; i < size; ++i) {
sum += numbers[i];
}
std::cout << "Sum of numbers: " << sum << std::endl;
return 0;
}
In this example, reduction(+:sum) allows each thread to accumulate its partial sum locally. OpenMP then efficiently combines these partial sums to compute the total sum without explicit locks or critical sections for each addition.
OpenMP in Action: Enhancing Drone Technology
The principles of OpenMP are directly applicable to numerous facets of drone technology, enabling more sophisticated capabilities and improved performance.
Advanced Navigation and Path Planning
Complex path planning algorithms, especially those involving real-time obstacle avoidance in dynamic environments, require immense computational power. OpenMP can parallelize the computation of potential flight paths, the evaluation of their safety and efficiency, and the processing of sensor data to update the flight plan on the fly. For example, in photogrammetry or inspection drones, generating detailed 3D models from numerous images involves computationally intensive tasks that can be significantly accelerated with OpenMP.
Real-time Image and Data Processing
Drones equipped with high-resolution cameras, LiDAR, or multispectral sensors generate vast amounts of data. Processing this data in real-time for immediate analysis, object detection, or change monitoring necessitates efficient parallel processing. OpenMP can be used to accelerate image filtering, feature extraction, stitching of aerial imagery, and the execution of machine learning models for on-board object recognition.
Sensor Fusion and Stabilization
Integrating data from multiple sensors (IMU, GPS, barometer, vision sensors) for precise stabilization and accurate positioning is a complex task. OpenMP can help parallelize the algorithms involved in sensor fusion, Kalman filtering, and attitude estimation, leading to more stable flight and more accurate data capture, critical for applications like aerial surveying, surveillance, and delivery services.
Simulation and Testing
Before deploying autonomous or semi-autonomous drone systems, extensive simulation and testing are required. OpenMP can accelerate these simulations by parallelizing the physics engines, environmental models, and the execution of various flight scenarios, allowing developers to test a wider range of conditions and refine control algorithms more efficiently.

Conclusion
OpenMP represents a vital tool in the developer’s arsenal for harnessing the power of multi-core processors. Its straightforward directives and clauses simplify the process of parallelizing C, C++, and Fortran applications, making it an accessible yet powerful solution. For industries pushing the boundaries of technology, from the intricate flight control of advanced UAVs to the sophisticated data analysis from aerial platforms, OpenMP provides the framework to achieve unprecedented levels of performance and computational capability. By understanding and effectively utilizing its constructs, developers can unlock the full potential of modern hardware, enabling the creation of smarter, faster, and more capable technological solutions.