Network redundancy is a fundamental concept in computer networking that ensures the continuous operation and reliability of systems. In essence, it involves the duplication of critical network components, such as devices, links, or even entire network paths, to provide an alternative route or function in the event of a failure. This proactive approach to system design minimizes downtime, preserves data integrity, and maintains the flow of information, even when faced with unexpected disruptions.
The Imperative of Network Redundancy
In today’s hyper-connected world, the reliance on robust and always-available networks is paramount. Businesses, governments, and individuals all depend on seamless data transmission for a vast array of operations. From financial transactions and critical infrastructure management to communication and entertainment, any interruption can have cascading and detrimental consequences.
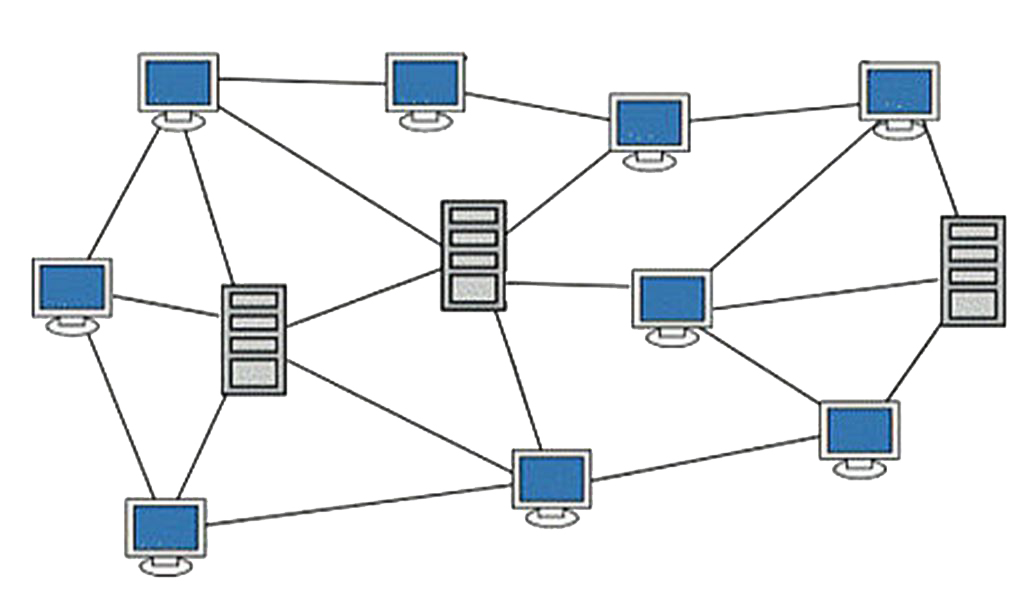
Consequences of Network Failure
The impact of network failure can range from minor inconvenconveniences to catastrophic losses. These consequences can be broadly categorized as follows:
Financial Losses
Downtime directly translates to lost revenue. For e-commerce platforms, every minute of inaccessibility means lost sales. For businesses reliant on online services, productivity grinds to a halt, impacting operational efficiency and profitability. Furthermore, the cost of emergency repairs and the potential loss of customer trust can significantly damage a company’s financial standing.
Operational Disruption
Critical services can be severely impacted by network outages. Hospitals relying on networked systems for patient records and diagnostics, emergency services needing instant communication, and logistical operations dependent on real-time tracking can all face significant disruptions, potentially jeopardizing public safety and well-being.
Data Loss and Corruption
While not directly caused by the network itself, prolonged network unavailability can lead to data loss. Systems may fail to save data correctly during an outage, or data backups may be interrupted, leading to the loss of valuable information. In some cases, the process of restoring service might inadvertently lead to data corruption.
Reputational Damage
For any organization, maintaining a reputation for reliability is crucial. Frequent or prolonged network outages can erode customer confidence and damage a brand’s image, making it difficult to attract and retain customers.
The Role of Redundancy in Mitigation
Network redundancy acts as a safety net, designed to detect failures and automatically reroute traffic or activate backup components, thereby mitigating the impact of these potential disruptions. It transforms a single point of failure into a resilient system capable of withstanding a variety of adverse events.
Types of Network Redundancy
Network redundancy can be implemented at various levels and through different architectural approaches. The choice of redundancy strategy often depends on the criticality of the network, the budget, and the specific requirements of the application or service being supported.
Component Redundancy
This is the most basic form of redundancy, focusing on duplicating individual hardware components within a network.
Power Supply Redundancy
- Dual Power Supplies: Servers and network devices are often equipped with two independent power supplies. If one fails, the other immediately takes over, ensuring uninterrupted operation. This is a common and relatively inexpensive form of redundancy.
Hardware Redundancy
- Redundant Network Interface Cards (NICs): Devices can have multiple NICs connected to different network switches. If one NIC or its connection fails, the other can still provide connectivity.
- Redundant Switches and Routers: In critical network segments, identical switches or routers can be deployed. If one device fails, traffic can be redirected to the other, often with minimal disruption.
Link Redundancy
This type of redundancy focuses on providing multiple physical or logical pathways between network devices.
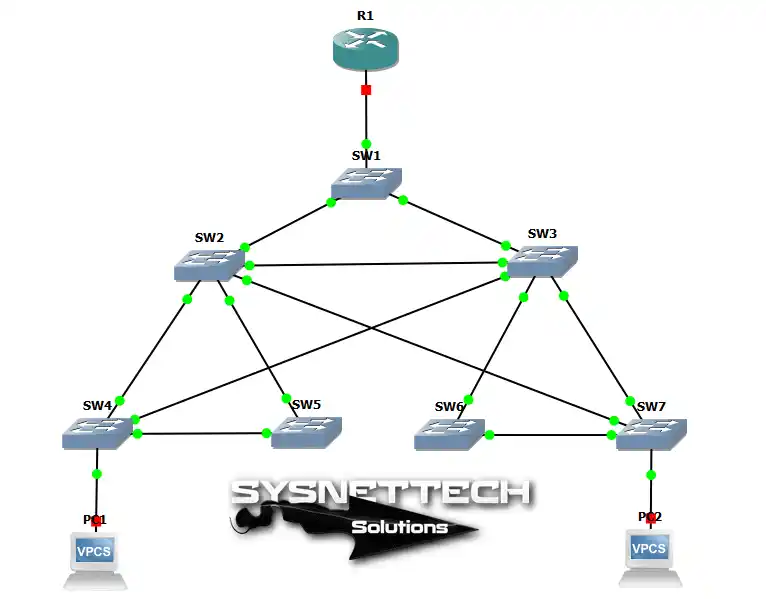
Physical Link Redundancy
- Multiple Cables: Connecting devices with more than one cable to different ports or even different devices can prevent a single cable failure from causing an outage.
- Multiple Network Paths: Designing the network so that there are at least two independent paths between critical locations ensures that if one path is broken, traffic can be rerouted through the other.
Logical Link Redundancy
- Link Aggregation (LAG) / EtherChannel: Multiple physical links are bundled together to form a single logical link. This not only provides redundancy but also increases bandwidth. If one of the physical links fails, the aggregate link continues to function with reduced capacity.
- Spanning Tree Protocol (STP) and its variants (RSTP, MSTP): STP is a Layer 2 protocol that prevents loops in Ethernet networks by blocking redundant paths. However, it can also be configured to provide redundancy. If a primary link fails, STP can unblock a previously blocked redundant path, restoring connectivity.
Path Redundancy
This extends the concept of link redundancy to entire network segments or routes.
Routing Protocol Redundancy
- Dynamic Routing Protocols (e.g., OSPF, EIGRP, BGP): These protocols are designed to automatically discover and adapt to network topology changes. If a link or router fails, routing protocols can recalculce the best paths to ensure traffic continues to flow, albeit potentially through a longer or less optimal route.
- Multiple Default Gateways: For end-user devices or servers, configuring multiple default gateways can provide redundancy. If the primary gateway becomes unavailable, the device can automatically switch to the secondary gateway.
Site and Data Center Redundancy
For mission-critical applications and the highest levels of availability, redundancy is implemented at the physical site level.
High Availability (HA) Clusters
- Active-Passive Clusters: In an active-passive setup, one server or device is actively handling traffic, while a standby (passive) device is ready to take over immediately if the active one fails. Failover can be automatic or manual.
- Active-Active Clusters: In this configuration, both devices are actively handling traffic, distributing the load. If one device fails, the other continues to operate, carrying the entire load. This offers both redundancy and improved performance.
Disaster Recovery Sites (DR Sites)
- Geographically Separated Data Centers: Organizations often maintain backup data centers in different geographical locations. In the event of a disaster affecting the primary site (e.g., natural disaster, power outage), operations can be shifted to the DR site, ensuring business continuity. This often involves complex replication of data and services.
Implementing Redundancy: Best Practices and Considerations
Successfully implementing network redundancy requires careful planning, design, and ongoing maintenance. It’s not simply a matter of buying duplicate equipment.
Design Principles
- Single Point of Failure Analysis (SPOFA): Identify all potential single points of failure in the network architecture. This involves a thorough review of all critical components and their connections.
- Layered Redundancy: Implement redundancy at multiple layers of the network (e.g., component, link, path) for comprehensive protection.
- End-to-End Redundancy: Ensure that redundancy is not just limited to specific segments but extends across the entire network path, from the source to the destination.
- Asymmetrical vs. Symmetrical Redundancy: Consider whether the redundant path needs to be identical to the primary path (symmetrical) or if a different, potentially less performant, but functional path is acceptable (asymmetrical).
Protocols and Technologies
- First Hop Redundancy Protocols (FHRPs): Protocols like Hot Standby Router Protocol (HSRP) and Virtual Router Redundancy Protocol (VRRP) provide a virtual default gateway for devices, ensuring that if one router fails, another can take over its IP address and functionality.
- Multipath TCP (MPTCP): This protocol allows a single TCP connection to utilize multiple network paths simultaneously, enhancing both performance and resilience.
- Software-Defined Networking (SDN): SDN can simplify the management of redundant paths by providing a centralized control plane that can dynamically reroute traffic based on network conditions and policy.
Testing and Maintenance
- Regular Testing: Redundancy systems are useless if they don’t work when needed. Regularly simulate failures and test the failover mechanisms to ensure they are functioning correctly. This can be done through controlled outages or dedicated testing tools.
- Monitoring and Alerting: Implement robust network monitoring tools to detect component failures, performance degradation, or unusual traffic patterns that could indicate an impending issue. Configure alerts to notify administrators immediately.
- Documentation: Maintain detailed documentation of the redundant architecture, including the configuration of redundant components, failover procedures, and troubleshooting steps.
- Configuration Management: Ensure that redundant components are configured identically (unless intentionally designed otherwise) and that configurations are kept up-to-date. Version control for network configurations is highly recommended.
Cost vs. Benefit Analysis
Implementing network redundancy comes with associated costs, including hardware, software, and operational overhead. It’s crucial to perform a cost-benefit analysis to determine the appropriate level of redundancy for specific needs. The cost of downtime and potential data loss should be weighed against the investment required for redundancy. Mission-critical applications will justify higher levels of redundancy than less critical ones.
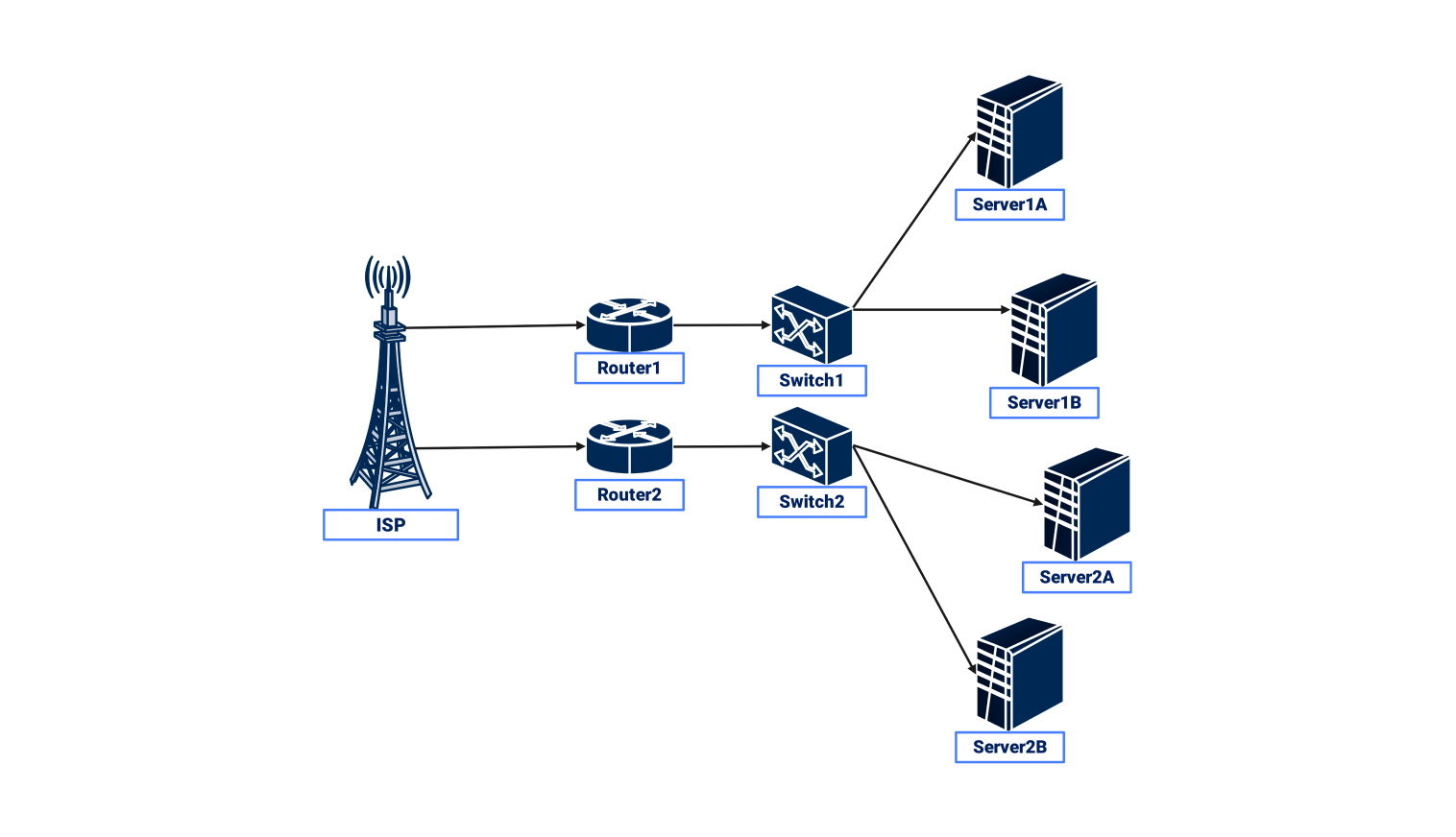
Conclusion
Network redundancy is not a luxury but a necessity in modern computing. By duplicating critical components and pathways, organizations can build resilient networks that are capable of withstanding failures and maintaining continuous operation. From basic component duplication to complex site-level disaster recovery plans, the principles of redundancy are applied to create robust, reliable, and always-available network infrastructure. A well-designed and meticulously maintained redundant network is the cornerstone of business continuity, data integrity, and operational efficiency in an increasingly interconnected world.