In an increasingly data-driven world, the ability to effectively compare and analyze sequences of information over time is paramount. From understanding complex speech patterns to monitoring vital signs or predicting market trends, many critical applications hinge on identifying similarities and differences between time-dependent datasets. While simple metrics like Euclidean distance suffice for static comparisons, they often fall short when dealing with dynamic, non-linearly varying sequences. This is where Dynamic Time Warping (DTW) emerges as a powerful and indispensable tool.
Dynamic Time Warping is an algorithm for measuring similarity between two temporal sequences which may vary in speed or duration. For instance, if two people say the same word, the total duration might be different, and the speed at which they pronounce individual phonemes might also vary. DTW allows for these variations by “warping” one sequence to match another, finding an optimal alignment between them. It’s a technique rooted in dynamic programming, offering a flexible and insightful approach to a wide array of challenges in modern technology and innovation.
The Core Problem: Comparing Time Series Data
At the heart of many technological advancements lies the need to make sense of sequential data. Whether it’s a sensor stream recording environmental conditions, a user’s biometric data during an activity, or financial stock prices over a quarter, data often unfolds over time. The challenge arises when we need to compare two such sequences, especially when their temporal alignment isn’t perfect or their intrinsic rates of change differ.
The Limitations of Traditional Metrics
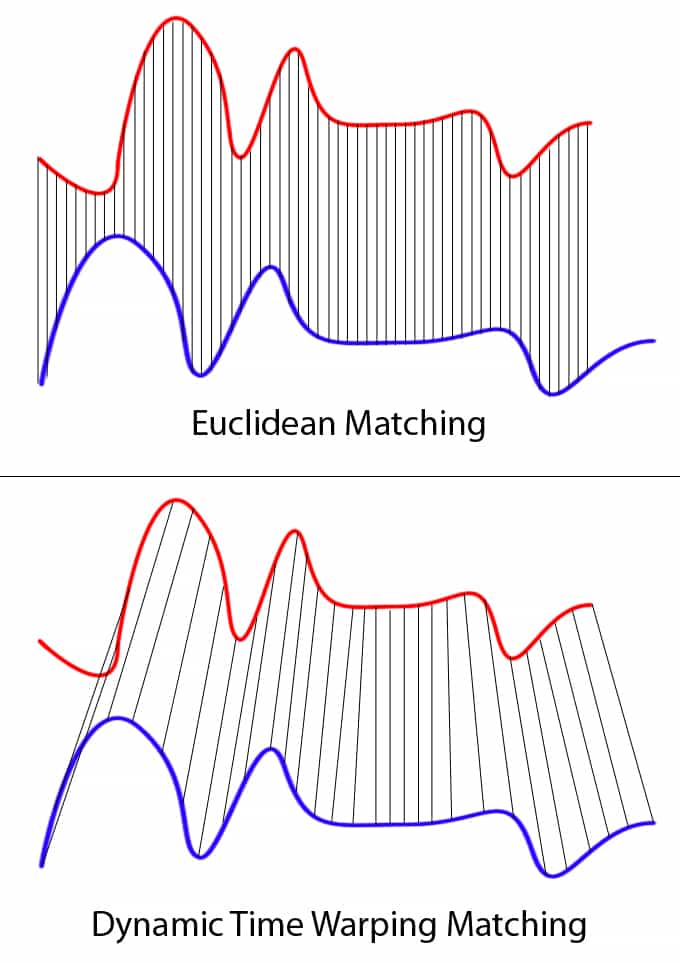
Consider two time series that represent the same underlying phenomenon but are shifted in time or stretched/compressed in their duration. For example, two identical heartbeats recorded, but one starts a fraction of a second later, or one is slightly prolonged due to a deeper breath. If we were to use traditional distance metrics, such as Euclidean distance, to compare these sequences point-by-point, we would likely conclude they are very dissimilar. Euclidean distance, by its nature, pairs points strictly by their index, assuming a perfect one-to-one temporal correspondence.
This strict correspondence is a significant limitation. It’s akin to comparing two musical pieces note by note, only to find them “different” because one performer played a phrase slightly faster or paused a little longer. The underlying melodic structure might be identical, but the rigid comparison method fails to recognize this fundamental similarity. This inability to account for temporal distortions leads to inaccurate similarity measures, hindering effective pattern recognition and analysis in numerous real-world applications.

The Need for Flexible Alignment
What’s needed is a method that can intelligently “stretch” or “compress” parts of one time series to align optimally with another. This flexible alignment allows us to uncover true similarities that are obscured by temporal misalignments or varying rates. DTW provides precisely this capability. Instead of a rigid, linear mapping, DTW seeks a non-linear mapping that minimizes the overall distance between two sequences, effectively finding the “best fit” by allowing one-to-many or many-to-one correspondences between data points. This flexibility makes it an invaluable tool for robust time series analysis, enabling algorithms to see through superficial temporal variations to the core patterns beneath.
Unpacking the Dynamic Time Warping Algorithm
Understanding how DTW achieves its flexible alignment requires a dive into its algorithmic mechanics. At its core, DTW is a dynamic programming algorithm that systematically constructs an optimal path through a grid, representing the possible alignments between two time series.
How DTW Works: A Path Through Time
Imagine two time series, $X = (x1, x2, dots, xN)$ and $Y = (y1, y2, dots, yM)$. To compare them using DTW, we first construct an $N times M$ matrix, often called the “cost matrix” or “distance matrix.” Each cell $(i, j)$ in this matrix stores the local distance between the $i$-th point of sequence $X$ ($xi$) and the $j$-th point of sequence $Y$ ($yj$). A common choice for this local distance is the squared Euclidean distance: $(xi – yj)^2$.
The goal of DTW is to find a “warping path” through this cost matrix, from cell $(1, 1)$ to $(N, M)$, such that the sum of the local distances along this path is minimized. This path represents the optimal alignment between the two sequences. The “dynamic” aspect comes into play because the cumulative cost to reach any cell $(i, j)$ is computed based on the minimum cumulative cost of its neighboring cells (typically $(i-1, j)$, $(i, j-1)$, and $(i-1, j-1)$).

Specifically, the cumulative cost $D(i, j)$ for cell $(i, j)$ is calculated as:
$D(i, j) = text{local_distance}(xi, yj) + min(D(i-1, j), D(i, j-1), D(i-1, j-1))$
This recursive calculation efficiently explores all possible warping paths without explicitly checking each one, ensuring that the globally optimal path is found.
Key Steps and Constraints
The DTW algorithm typically involves these steps:
- Initialization: Create an $N times M$ cost matrix and initialize the first row and first column with infinite values, except for $D(1,1)$ which is the local distance between $x1$ and $y1$.
- Cumulative Cost Calculation: Iterate through the matrix, calculating $D(i, j)$ for each cell using the formula above, progressively building up the cumulative cost matrix.
- Backtracking for Warping Path: Once the entire cumulative cost matrix is filled, the value at $D(N, M)$ represents the DTW distance between the two sequences. To find the actual warping path, one typically backtracks from $(N, M)$ to $(1, 1)$, always choosing the neighbor (from $(i-1, j)$, $(i, j-1)$, or $(i-1, j-1)$) that led to the minimum cumulative cost.
To ensure meaningful alignments and prevent pathological warpings (e.g., matching a single point from one sequence to many points from another, or excessively long/short stretches), various constraints can be applied:
- Monotonicity: The warping path must always move forward in time (no going back).
- Continuity: The path can only advance to adjacent cells.
- Boundary Conditions: The path must start at $(1, 1)$ and end at $(N, M)$.
- Windowing (Sakoe-Chiba Band, Itakura Parallelogram): These constraints restrict the warping path to a specific diagonal band around the main diagonal, preventing absurdly long warps and significantly speeding up computation.
Visualizing the Warping Path
Visualizing the warping path is incredibly insightful. If we plot the two time series, and then draw lines connecting the points that are matched by the DTW algorithm, we can clearly see how one sequence is stretched or compressed to align with the other. This visualization often reveals underlying structural similarities that would be invisible to simpler comparison methods. For example, in speech recognition, it shows which parts of a spoken word correspond to which parts of a template word, even if pronounced at different speeds. This visual clarity underscores the power and interpretability of DTW as a tool for understanding complex temporal relationships.
Transformative Applications Across Tech Domains
The power of DTW’s flexible alignment makes it a cornerstone algorithm in numerous innovative technological applications. Its ability to robustly compare sequences regardless of their temporal distortions unlocks insights across diverse fields.
Speech Recognition and Audio Analysis
One of the earliest and most impactful applications of DTW was in speech recognition. Before the advent of deep learning, DTW was central to recognizing spoken words by matching an incoming speech signal to a library of pre-recorded templates. Despite variations in speaking speed, pitch, or individual pronunciation styles, DTW could find the optimal alignment between the new utterance and a stored template, enabling robust word identification. Today, it still finds use in specialized audio processing, such as speaker verification, music information retrieval (e.g., identifying similar melodies), and subtle sound event detection where precise temporal matching is critical.
Robotics and Sensor Data Alignment
In robotics, particularly for autonomous systems, DTW plays a crucial role in processing and aligning sensor data. Robots often collect data from various sensors (LIDAR, cameras, IMUs) that might have slight time offsets or operate at different frequencies. DTW can align these diverse sensor streams to create a coherent understanding of the environment. Furthermore, it’s used in robot motion planning and imitation learning, where a robot learns a task by observing human demonstrations. DTW helps match the robot’s generated motion trajectory with the human’s demonstrated trajectory, accounting for differences in execution speed to optimize learning.
Healthcare and Biometric Analysis
The healthcare sector benefits significantly from DTW’s ability to analyze physiological signals. Electrocardiograms (ECGs), electroencephalograms (EEGs), and other biometric data are time series prone to variations due to patient movement, changing heart rates, or signal noise. DTW can compare a patient’s current ECG with a baseline or known abnormal patterns, even if heartbeats vary slightly in duration, aiding in the early detection of arrhythmias or other cardiac abnormalities. It’s also used in gesture recognition for rehabilitation exercises, gait analysis to detect anomalies in walking patterns, and even in sleep stage classification based on physiological signals.
Financial Time Series and Anomaly Detection
In finance, market data—such as stock prices, trading volumes, and economic indicators—are inherently time series. DTW can be used to identify similar patterns in stock movements, even if they occur over different durations or with different volatilities, potentially indicating correlated market behavior. Beyond pattern matching, DTW is instrumental in anomaly detection. By comparing current market behavior with historical “normal” patterns, significant deviations, which might signify fraudulent activity or unusual market events, can be identified, even if they unfold at an irregular pace.
Beyond: Data Mining and Machine Learning
The utility of DTW extends broadly across data mining and machine learning. In general time series classification, DTW often serves as a powerful distance metric for k-Nearest Neighbors (k-NN) algorithms, leading to highly accurate classifiers for complex sequential data. It’s applied in weather pattern analysis, climate change modeling, industrial process monitoring for fault detection, and even in analyzing user behavior sequences in web applications. Its versatility lies in its model-free approach, requiring no prior assumptions about the underlying data generation process, making it applicable to a vast range of unstructured and complex time series problems.
Advantages, Challenges, and Optimizations
While DTW offers unparalleled flexibility for time series comparison, it’s essential to understand its strengths, its inherent limitations, and the various ways researchers and practitioners have sought to optimize its performance.
The Power of Non-Linear Alignment
The primary advantage of DTW is its robustness to temporal distortions. Unlike Euclidean distance or other point-to-point metrics, DTW does not assume that corresponding events in two sequences occur at the same absolute time. This non-linear alignment capability allows it to accurately measure the true shape similarity between sequences, making it indispensable in domains where temporal variations are common and significant. This flexibility leads to more intuitive and often more accurate similarity measures, uncovering underlying patterns that rigid comparison methods would miss.
Computational Complexity and Scalability Issues
Despite its powerful capabilities, the most significant challenge with standard DTW is its computational complexity. For two sequences of length $N$ and $M$, the standard DTW algorithm has a time complexity of $O(N times M)$. This quadratic complexity can become prohibitive for very long time series or when comparing a large number of sequences, which is often the case in big data scenarios. Calculating DTW distances between every pair in a large dataset for tasks like clustering can quickly exhaust computational resources, making scalability a major concern.
Enhancements and Variants of DTW
To address the computational bottleneck and improve performance, several enhancements and variants of DTW have been developed:
- Windowing Techniques: As mentioned earlier, constraints like the Sakoe-Chiba Band or Itakura Parallelogram restrict the warping path to a specific region around the main diagonal of the cost matrix. This reduces the number of cells that need to be computed, significantly lowering complexity to nearly linear time $O(N times W)$ where $W$ is the width of the band. While faster, this introduces a hyperparameter (the window size) and might miss optimal global alignments if the true warping path falls outside the window.
- FastDTW: This algorithm offers an approximation of DTW in $O(N)$ time, leveraging a multi-resolution approach. It recursively down-samples the time series, performs DTW on the coarser resolution, and then projects the resulting warping path back onto the higher resolution, refining it iteratively.
- Subsequence DTW: For scenarios where one wants to find whether a shorter pattern exists within a longer sequence, subsequence DTW variants (like DTW-subsequence or UCR-DTW) are used. These don’t require the warping path to span the entire longer sequence.
- Weighted DTW & Dependent DTW: These variants introduce weights to different parts of the sequences or make the local distance calculation dependent on features beyond just the current points, allowing for more nuanced comparisons.
- Parallelization: Given the independent nature of calculating cumulative costs for different cells, DTW computations can often be parallelized, leveraging multi-core processors or GPU acceleration to speed up computation.
These optimizations make DTW more practical for real-world, large-scale applications, expanding its reach within the “Tech & Innovation” landscape.
The Future of Time Series Similarity in Innovation
Dynamic Time Warping has already proven its value across countless technological applications. As data generation continues to explode and our need to extract deeper insights from sequential information intensifies, DTW’s role, particularly in combination with emerging technologies, is set to become even more critical.
Integration with Machine Learning Paradigms
While often used as a standalone distance metric for algorithms like k-NN, the future will see deeper integration of DTW into more complex machine learning and deep learning architectures. Techniques that allow DTW to be differentiable could enable its use directly within neural networks, providing robust temporal alignment capabilities to models designed for sequence prediction, classification, and generation. Hybrid models combining the strengths of DTW’s non-linear alignment with the representational power of deep learning hold immense promise for handling highly variable and complex time series data. This could lead to more robust AI systems in domains like autonomous vehicles (predicting pedestrian movements), healthcare (personalized treatment response analysis), and advanced robotics.
Real-time DTW and Edge Computing
The demand for immediate insights from streaming data is growing. Real-time DTW implementations, possibly leveraging specialized hardware or highly optimized approximate algorithms, will become crucial. This is particularly relevant for edge computing scenarios where data processing occurs close to the source, such as on drones, IoT devices, or wearable sensors. Imagine a smart garment that uses real-time DTW to analyze an athlete’s movement patterns, immediately providing feedback on form correction, or an industrial sensor that detects early signs of machinery failure by continuously comparing live vibrations to known fault signatures. The ability to perform DTW computations on resource-constrained devices at the edge will unlock a new wave of responsive and intelligent applications.
Broader Impact on Data-Driven Decision Making
Ultimately, the continued evolution and application of DTW will have a profound impact on data-driven decision making across all sectors. By providing a more nuanced and accurate understanding of temporal similarities, DTW empowers organizations to make better predictions, identify subtle patterns, and automate complex analyses that were previously intractable. From optimizing supply chains by matching demand patterns to personalizing educational content based on learning trajectories, DTW stands as a testament to the power of innovative algorithmic thinking in transforming how we interact with and learn from the world’s increasingly sequential data. Its journey from a specialized algorithm to a widely recognized tool for robust time series analysis underscores its enduring relevance in the landscape of Tech & Innovation.