In the increasingly data-driven landscape of the 21st century, organizations across every sector are grappling with vast quantities of information. From user interactions and sensor readings to financial transactions and operational logs, data is the new raw material powering insights, automation, and decision-making. However, raw data is rarely in a usable state. It’s often disparate, messy, and requires significant processing before it can yield value. This is where the concept of a “data pipeline” becomes not just relevant, but absolutely critical. At its core, a data pipeline is a series of automated processes designed to move raw data from various sources, transform it into a more usable format, and deliver it to a destination where it can be analyzed, stored, or consumed by other applications. It is the sophisticated plumbing system that ensures a continuous, reliable flow of information, powering everything from advanced analytics and machine learning models to real-time operational dashboards and intelligent autonomous systems. Without robust data pipelines, the promise of big data, AI, and comprehensive tech innovation would remain largely unfulfilled.
The Foundational Role of Data Pipelines in Modern Tech
The sheer volume, velocity, and variety of data generated today demand a systematic approach to its management. Data pipelines provide precisely that, acting as the backbone for virtually every data-intensive application and system. Their significance extends beyond mere data transfer; they are instrumental in maintaining data integrity, ensuring timeliness, and preparing data for high-level computational tasks.
Demystifying the Concept
Imagine a complex manufacturing process. Raw materials enter one end, undergo several stages of refinement, assembly, and quality control, and finally emerge as a finished product. A data pipeline operates on a similar principle, but with information as its raw material. It orchestrates the entire journey of data, from its origin to its final consumption. This journey typically involves several key stages: extraction from source systems, transformation to standardize and clean the data, and loading into a target system such as a data warehouse, data lake, or an analytics platform. The entire process is automated, minimizing manual intervention and maximizing efficiency. It’s an end-to-end solution for managing the lifecycle of data, making it accessible and valuable for diverse technological applications. Whether it’s feeding a recommendation engine, optimizing supply chains, or enabling predictive maintenance, the health and efficiency of the underlying data pipeline dictate the success of these initiatives.
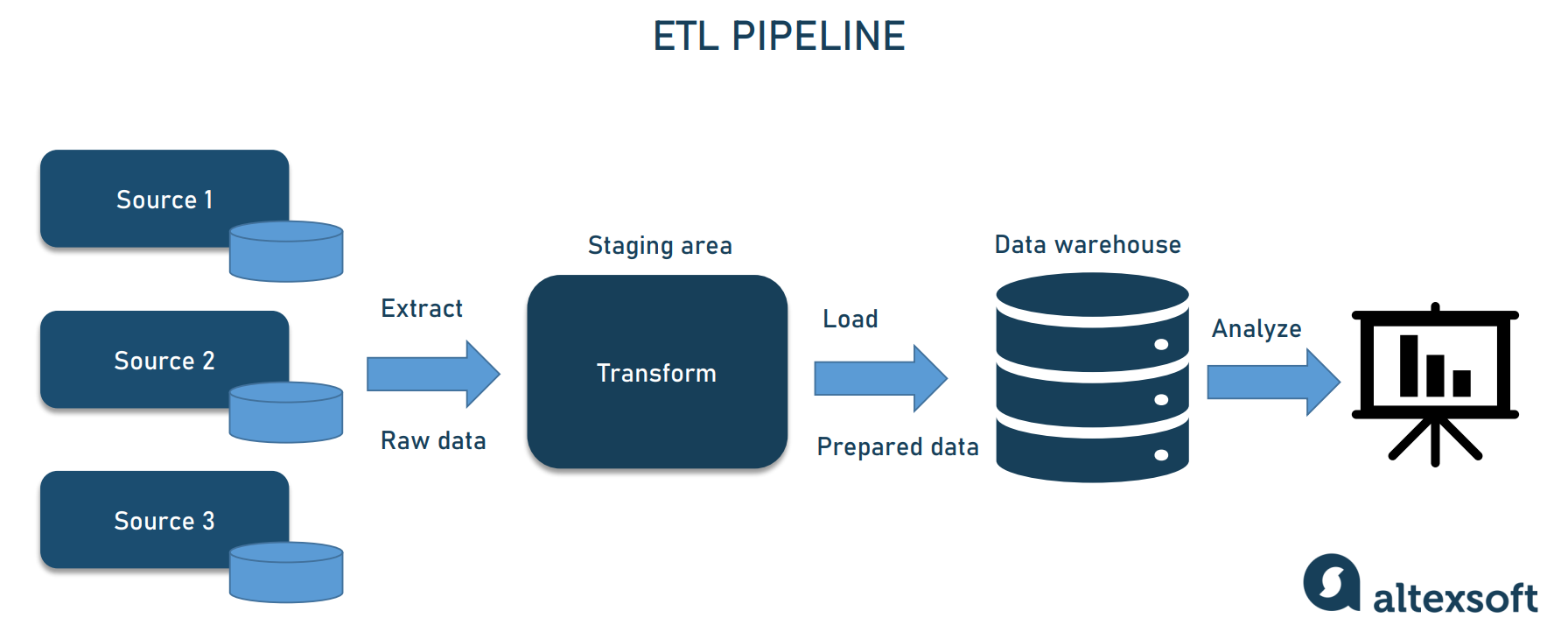
Why Data Pipelines are Indispensable
In an era defined by rapid technological advancements, the ability to collect, process, and analyze data efficiently is a competitive differentiator. Data pipelines are indispensable for several reasons. Firstly, they enable data integration from disparate sources, breaking down silos and providing a holistic view of operations or customer behavior. This unified perspective is crucial for accurate reporting and strategic planning. Secondly, they automate repetitive tasks, freeing up valuable human resources to focus on analysis and innovation rather than data wrangling. Thirdly, they ensure data quality and consistency through predefined transformation rules, reducing errors and improving the reliability of insights derived. Finally, and perhaps most importantly, robust data pipelines are the bedrock for advanced technologies like artificial intelligence and machine learning. These systems are inherently data-hungry, requiring vast amounts of clean, well-structured data for training and inference. Without efficient pipelines, feeding these sophisticated algorithms would be a monumental, if not impossible, task. For any organization aspiring to leverage AI for autonomous features, intelligent automation, or sophisticated predictive models, well-engineered data pipelines are non-negotiable.
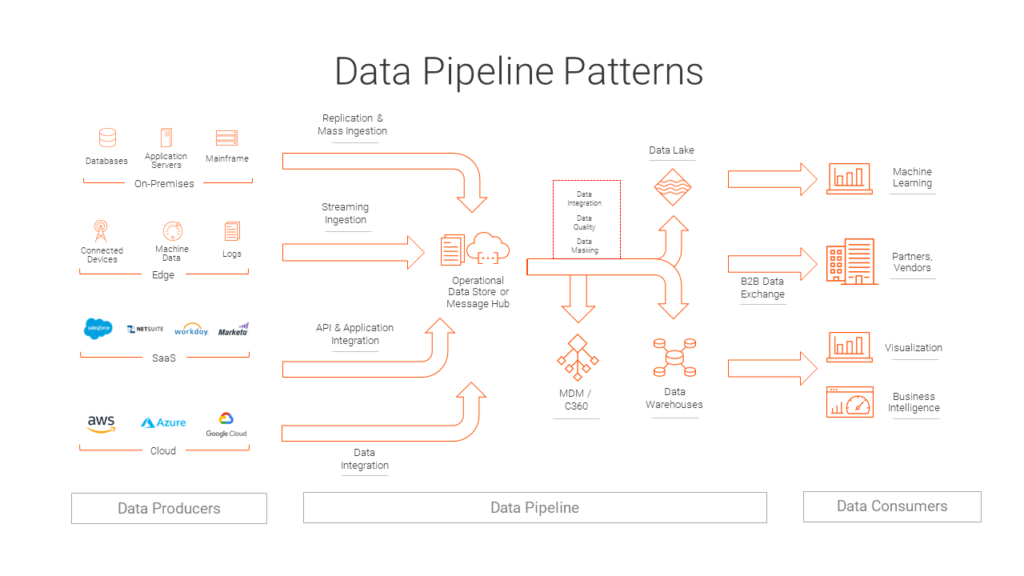
Anatomy of a Data Pipeline: Key Stages and Components
A data pipeline is not a monolithic entity but rather a coordinated sequence of processes, each with a distinct role in preparing data for its ultimate purpose. Understanding these stages is key to appreciating the complexity and utility of these systems.
Data Ingestion: The Entry Point
The first stage in any data pipeline is ingestion, where raw data is collected and brought into the pipeline from its source. Data sources can be incredibly diverse, ranging from relational databases, APIs, IoT devices, web servers, social media feeds, log files, and streaming platforms. This stage often involves various connectors and protocols designed to interface with different systems. Depending on the nature of the data and the requirements, ingestion can happen in batch, where large chunks of data are moved periodically, or in real-time streaming, where data is moved continuously as it is generated. The goal here is to efficiently and reliably capture all relevant data without loss or corruption, laying the groundwork for subsequent processing.
Data Transformation: Shaping and Refining
Once ingested, raw data is seldom in a format suitable for direct analysis or storage. The transformation stage is where data is cleaned, structured, enriched, and validated. This can involve a myriad of operations:
- Cleaning: Removing duplicates, handling missing values, correcting errors, and standardizing formats.
- Structuring: Converting data into a consistent schema, often involving parsing unstructured data (like text or JSON) into structured tables.
- Enrichment: Adding context to the data by combining it with other datasets or external information.
- Filtering: Selecting only the relevant data points and discarding unnecessary information.
- Aggregation: Summarizing data, such as calculating totals, averages, or counts.
- Validation: Ensuring data conforms to predefined rules and constraints.
The transformation process is crucial for enhancing data quality and making it consistent and compliant with the requirements of the destination system and subsequent analytical tasks. It’s a painstaking but essential step that unlocks the true potential of the raw information.
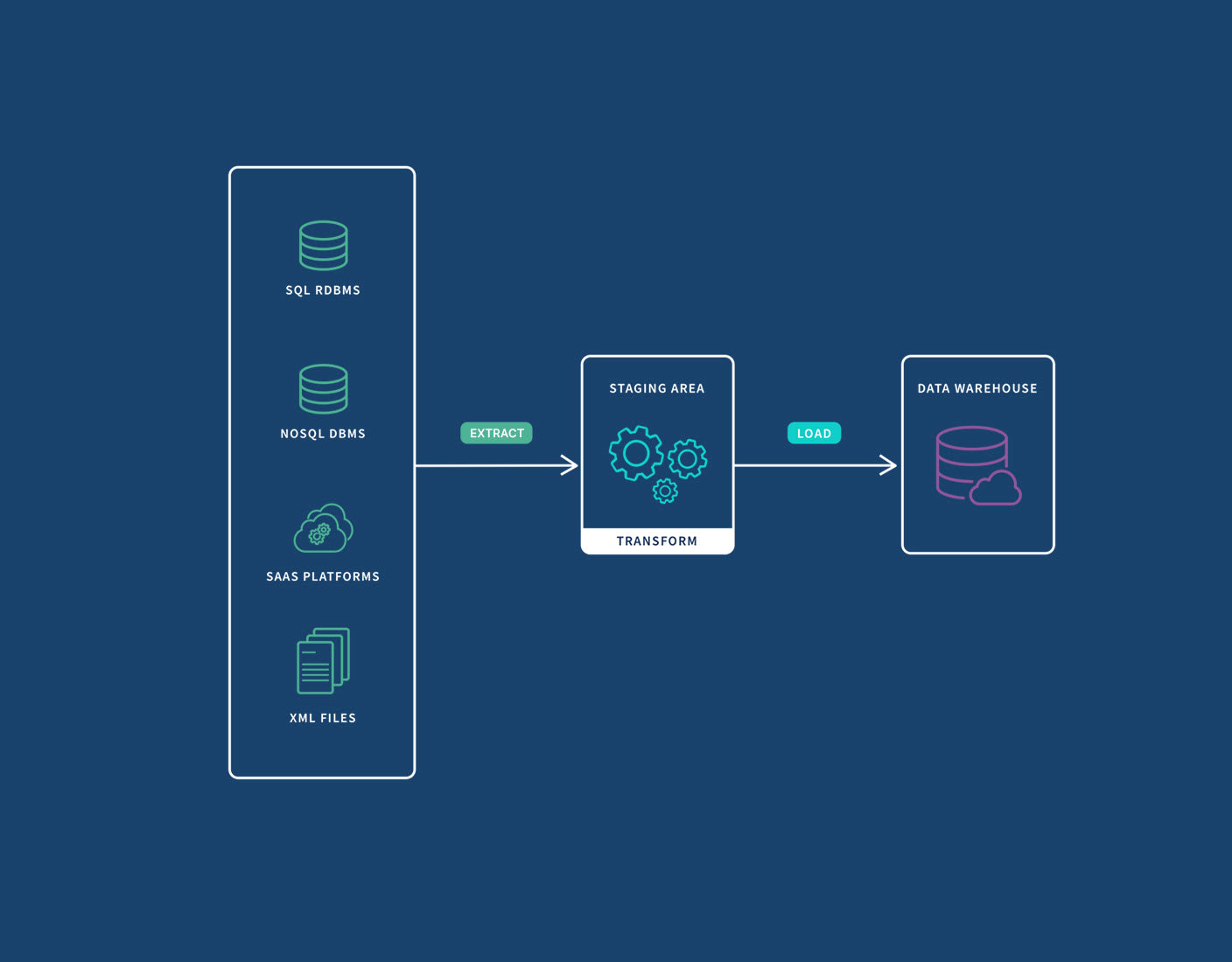
Data Storage: The Repository of Value
After transformation, the processed data needs a place to reside. The storage component of a data pipeline can vary significantly based on the data’s nature, volume, and intended use. Common storage destinations include:
- Data Warehouses: Optimized for analytical queries, supporting structured, historical data from multiple sources.
- Data Lakes: Capable of storing vast amounts of raw, semi-structured, and structured data, offering flexibility for future analysis.
- NoSQL Databases: Suitable for handling unstructured or rapidly changing data.
- Operational Databases: For immediate use by transactional applications.
The choice of storage solution impacts performance, scalability, and cost. Modern data pipelines often leverage cloud-based storage solutions due to their elasticity, scalability, and managed services, providing robust and accessible repositories for valuable information.
Data Consumption and Analysis: Actionable Insights
The final stage of a data pipeline is where the processed and stored data is consumed. This consumption can take many forms:
- Business Intelligence (BI) Dashboards: Providing visual summaries and insights for operational monitoring and strategic decision-making.
- Reporting: Generating periodic reports for stakeholders.
- Machine Learning Models: Feeding clean, structured data to training algorithms or for real-time inference in AI applications.
- Data Science Workbenches: Enabling data scientists to explore, model, and experiment with data.
- APIs: Exposing data for use by other applications and services.
- Autonomous Systems: Providing real-time data for decision-making in systems like automated flight control or remote sensing platforms.
This stage closes the loop, transforming raw bytes into actionable intelligence and powering the advanced technological innovations that rely on accurate and timely data.
Types of Data Pipelines: Adapting to Diverse Needs
Not all data processing needs are the same. Data pipelines are designed to handle different requirements, primarily categorized by how they process data over time.
Batch Processing: Handling Large Volumes Periodically
Batch data pipelines are designed to process large volumes of data at scheduled intervals. Data is collected over a period (e.g., hourly, daily, weekly) and then processed as a single “batch.” This approach is ideal for tasks that don’t require immediate real-time insights, such as end-of-day financial reports, monthly sales summaries, or historical data analysis. While there might be a latency between data generation and processing, batch pipelines are highly efficient for managing large datasets, optimizing resource usage, and ensuring thorough data validation before loading. They are often less complex to design and maintain compared to real-time systems, making them a cornerstone for many traditional data warehousing and business intelligence initiatives.
Stream Processing: Real-time Agility
In contrast, stream processing pipelines are built for real-time data ingestion and processing. Data is processed as it arrives, piece by piece, enabling immediate analysis and reactions. This is crucial for applications where low latency is paramount, such as fraud detection, IoT sensor monitoring, live stock market updates, personalized user experiences, or the operational data feeding autonomous drones. Stream processing systems require robust infrastructure capable of handling continuous data flows and rapid computations. Technologies like Apache Kafka, Apache Flink, and Spark Streaming are commonly used to build these agile pipelines, empowering immediate decision-making and allowing tech innovations to react instantaneously to changing conditions. The ability to process data in motion is a game-changer for systems that demand real-time intelligence.
The Strategic Advantages of Robust Data Pipelines
Beyond their functional role, well-implemented data pipelines offer significant strategic advantages, empowering organizations to leverage their data assets more effectively and drive innovation.
Enhancing Data Quality and Reliability
One of the primary benefits of a robust data pipeline is the significant improvement in data quality and reliability. By enforcing strict transformation rules, validation checks, and error handling mechanisms throughout the process, pipelines ensure that data arriving at its destination is clean, consistent, and accurate. This high-quality data is foundational for trustworthy analytics, accurate AI model training, and reliable operational systems. Errors introduced at the data collection or processing stage can have cascading negative impacts down the line, leading to flawed insights or erroneous decisions. Data pipelines mitigate this risk by automating and standardizing the data cleansing process, thereby building confidence in the data.
Driving Efficiency and Automation
The automation inherent in data pipelines dramatically increases operational efficiency. Manual data handling is not only time-consuming but also prone to human error. Pipelines eliminate these manual bottlenecks by automating the entire flow from ingestion to consumption. This reduces the time and effort spent on data preparation, allowing data engineers, analysts, and data scientists to focus on higher-value tasks such like model building, insight generation, and strategic planning. The ability to automatically scale processing capabilities to handle fluctuating data volumes further contributes to efficiency, ensuring that data is always processed promptly without requiring constant manual oversight. This efficiency is critical for organizations looking to innovate rapidly.
Empowering Advanced Analytics and AI
Perhaps the most significant strategic advantage of data pipelines in the context of tech and innovation is their role in empowering advanced analytics and artificial intelligence. AI and machine learning models thrive on large volumes of clean, well-structured, and timely data. Data pipelines provide precisely this, acting as the consistent supply chain for these data-hungry algorithms. Whether it’s preparing historical data for training a predictive model, or feeding real-time sensor data for an AI-driven autonomous system, robust pipelines ensure that the necessary data is available in the right format at the right time. This seamless integration of data sources with AI applications is fundamental to developing smarter systems, enabling predictive capabilities, and unlocking new frontiers in automation and intelligent decision-making across various industries, from healthcare to aerospace.
Overcoming Challenges and Future Outlook
While indispensable, building and maintaining data pipelines is not without its challenges. However, continuous innovation in the field promises to make these systems even more powerful and accessible in the future.
Common Hurdles in Pipeline Implementation
Implementing and managing data pipelines can present several significant hurdles. The complexity often arises from the sheer diversity of data sources, each with its unique format, schema, and API. Ensuring data consistency across these disparate sources is a constant battle. Scalability is another major concern; pipelines must be able to gracefully handle exponential growth in data volume and velocity without compromising performance. Data quality and governance, including privacy regulations like GDPR and CCPA, add layers of complexity, requiring careful attention to data masking, access control, and audit trails. Furthermore, monitoring and maintaining these systems, detecting failures, and recovering from errors require sophisticated tools and skilled personnel. The “pipeline debt” – the accumulated cost of technical debt in data pipelines – is a growing concern for many organizations.
The Evolving Landscape of Data Orchestration
The future of data pipelines is characterized by increasing automation, intelligence, and accessibility. We are seeing a shift towards more intelligent data orchestration platforms that leverage AI and machine learning to automate pipeline creation, optimize performance, detect anomalies, and even suggest transformations. Cloud-native solutions continue to dominate, offering serverless computing and managed services that simplify deployment and scaling. The rise of DataOps methodologies, which apply DevOps principles to data management, is fostering greater collaboration between data engineers, data scientists, and operations teams, leading to more agile and reliable pipeline development. Furthermore, advancements in real-time processing and streaming analytics are making instantaneous data insights more achievable and commonplace, pushing the boundaries of what’s possible in autonomous systems, proactive decision-making, and truly intelligent applications. As data continues to grow in importance, the evolution of data pipelines will remain at the forefront of technological innovation, ensuring that the lifeblood of modern tech flows freely and efficiently.