In the rapidly evolving landscape of data management, organizations constantly seek more efficient, scalable, and cost-effective ways to store, process, and analyze their ever-growing volumes of data. For years, the industry grappled with a bifurcated approach, relying on two distinct paradigms: data warehouses for structured, high-quality analytical workloads and data lakes for raw, diverse, and large-scale data storage, particularly for AI and machine learning initiatives. While each served its purpose admirably, the operational complexities and data duplication arising from their separate existence often led to inefficiencies and inconsistencies. Enter the data lakehouse – an innovative architectural pattern that elegantly merges the best features of both data lakes and data warehouses into a single, unified platform.
A data lakehouse represents a fundamental shift in how enterprises approach their data strategy. It’s not merely a theoretical concept but a practical, implementable solution designed to overcome the inherent limitations of traditional architectures. By combining the flexibility and low cost of a data lake with the robust data management and ACID (Atomicity, Consistency, Isolation, Durability) transaction capabilities of a data warehouse, the data lakehouse offers a powerful, simplified, and highly performant environment for all types of data workloads, from business intelligence (BI) to advanced analytics and machine learning. This unified approach promises to democratize data access, accelerate insights, and significantly reduce the total cost of ownership for data infrastructure.
The Evolution of Data Architectures: From Silos to Synergy
Understanding the genesis of the data lakehouse requires a brief journey through the historical evolution of data management systems. For decades, organizations primarily relied on transactional databases for operational needs and data warehouses for analytical reporting. As data volumes exploded and new data types emerged, these traditional systems began to show their strain, paving the way for more specialized solutions.
The Rise of Data Lakes
The advent of “big data” technologies, particularly distributed file systems like Hadoop, gave birth to the concept of the data lake. Data lakes provided a scalable and economical storage solution for vast amounts of raw, unstructured, semi-structured, and structured data. Their “schema-on-read” approach offered immense flexibility, allowing organizations to ingest data without predefined schemas, processing it only when analysis was required. This made data lakes ideal for exploratory analytics, data science, and machine learning, where the exact analytical questions were not always known upfront. However, data lakes often struggled with data quality, governance, and the ability to perform complex, high-concurrency SQL queries efficiently, leading to the infamous “data swamp” phenomenon. Without proper metadata management and data governance, data lakes could become difficult to navigate and trust.
The Enduring Value of Data Warehouses
Conversely, data warehouses have long been the bedrock of business intelligence and reporting. They are meticulously designed for structured data, optimized for complex analytical queries, and enforce strict data quality rules through schema-on-write principles. Key features like ACID transactions ensure data reliability, and robust indexing capabilities facilitate fast query performance. While data warehouses excel at providing trustworthy data for strategic decision-making, their rigidity, high cost for large-scale raw data storage, and difficulty in handling unstructured data made them less suitable for the diverse and dynamic needs of modern data applications, especially those involving machine learning.
The Impetus for Integration
The coexistence of data lakes and data warehouses often led to a complex data architecture. Data engineers would frequently move data between the two systems – raw data would land in the data lake, undergo transformation, and then be loaded into the data warehouse for BI. This process was not only resource-intensive and time-consuming but also introduced data duplication, potential inconsistencies, and increased latency, making it challenging to maintain a single source of truth. The need for a unified platform that could offer the flexibility and scale of a data lake alongside the reliability and performance of a data warehouse became increasingly apparent, laying the groundwork for the data lakehouse.
Defining the Data Lakehouse: A Hybrid Paradigm
The data lakehouse is fundamentally a new data architecture built on the open and flexible foundation of a data lake but incorporating critical data management features traditionally associated with data warehouses. It aims to eliminate data silos and provide a single platform for all data workloads.
Bridging the Divide
At its core, a data lakehouse uses an open file format (like Parquet or ORC) for storing data on object storage (like AWS S3, Azure Data Lake Storage, or Google Cloud Storage), just like a data lake. However, it overlays this storage with an “open table format” layer (such as Delta Lake, Apache Iceberg, or Apache Hudi). This layer introduces data warehouse-like features directly onto the data lake, transforming it from a raw data repository into a robust, structured, and manageable system.
Core Principles
The defining principles of a data lakehouse include:
- Open Formats and Storage: Utilizing open, standardized data formats (e.g., Parquet, ORC) and object storage for maximum flexibility and cost-efficiency. This avoids vendor lock-in.
- Schema Enforcement and Evolution: Providing mechanisms for schema enforcement to ensure data quality, while also supporting schema evolution to adapt to changing data structures over time.
- ACID Transactions: Guaranteeing data reliability and consistency by supporting atomic transactions, crucial for concurrent reads and writes, and ensuring data integrity.
- Data Governance and Security: Offering robust capabilities for data cataloging, access control, auditing, and compliance, enabling strong data governance across all data types.
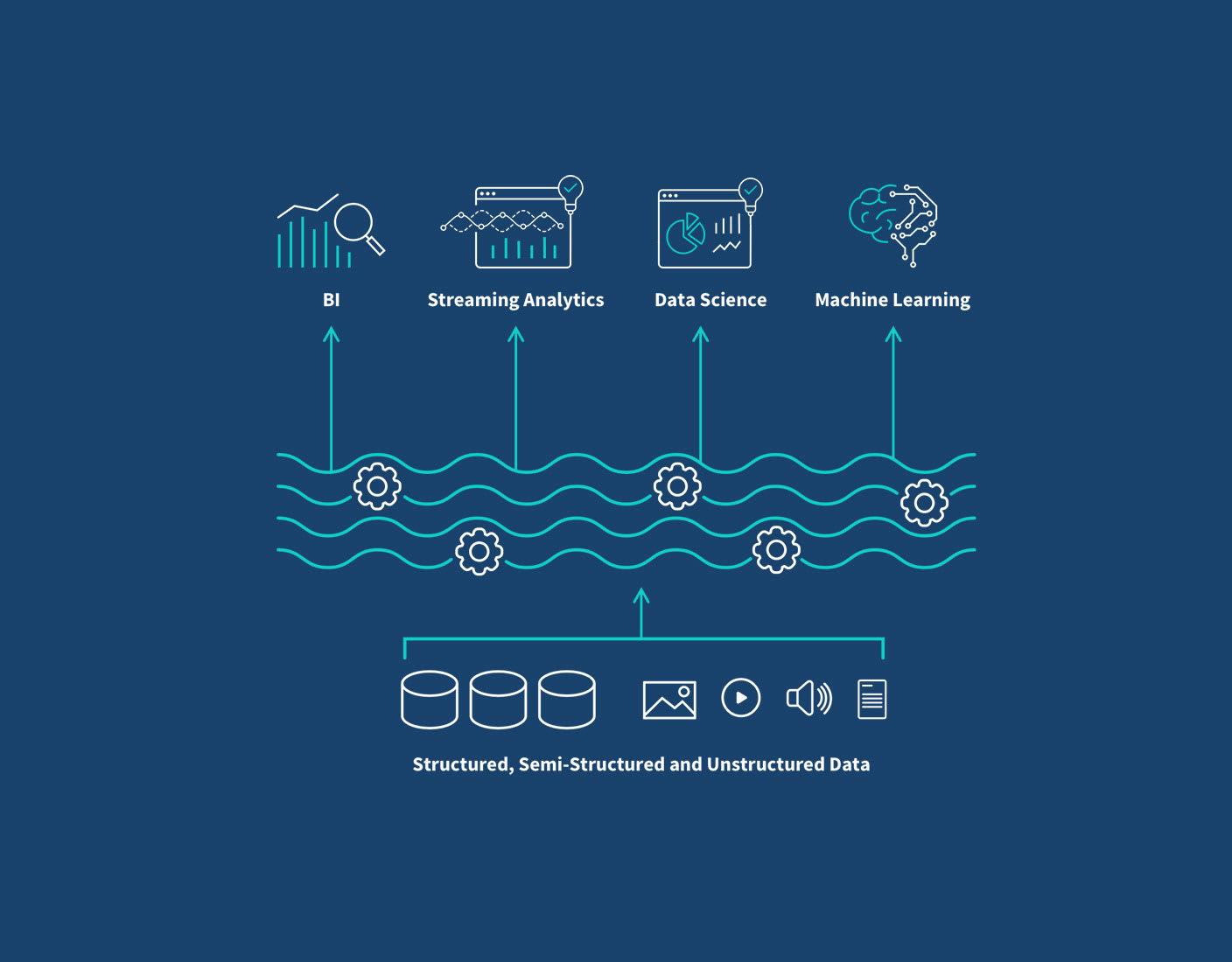
- Support for Diverse Workloads: Seamlessly handling traditional BI and SQL analytics alongside advanced analytics, machine learning, and data science workloads on the same data.
- Data Versioning and Time Travel: Allowing users to access previous versions of data, facilitating rollbacks, audit trails, and consistent machine learning model training.
- Direct Data Access: Enabling various data processing engines (SQL engines, Spark, Python, R) to directly access the same data without needing to move it.

Key Features and Advantages of the Data Lakehouse
The unified nature of the data lakehouse architecture brings forth a multitude of advantages that address the complexities and limitations of previous data architectures.
Enhanced Performance and Scalability
By leveraging cloud object storage, data lakehouses offer virtually limitless scalability for data storage at a fraction of the cost of traditional data warehouses. Furthermore, the open table formats introduce optimizations like indexing, caching, and data skipping, significantly boosting query performance for analytical workloads, often rivaling or exceeding that of dedicated data warehouses. This architecture can scale compute and storage independently, allowing organizations to provision resources based on demand without over-provisioning.
Improved Data Quality and Governance
The ability to enforce schemas, support ACID transactions, and implement robust metadata management ensures a higher level of data quality and trustworthiness. Data lakehouses provide a centralized platform for data governance, simplifying compliance, auditing, and access control across all data assets, regardless of their structure or origin. This eliminates the “data swamp” problem and fosters confidence in the data used for critical business decisions.
Simplified Data Management
Consolidating data into a single platform streamlines data ingestion, transformation, and management processes. Data engineers no longer need to maintain separate ETL (Extract, Transform, Load) pipelines for data lakes and data warehouses, reducing complexity, development time, and operational overhead. This simplification allows teams to focus more on deriving insights rather than managing infrastructure.
Cost-Effectiveness
Cloud object storage, which forms the foundation of a data lakehouse, is significantly cheaper than the proprietary storage often used by data warehouses. By avoiding data duplication and streamlining operations, organizations can realize substantial cost savings on infrastructure, data movement, and operational expenditures. The ability to choose the most suitable compute engine for a given task also optimizes resource utilization and cost.
Architectural Components and Enabling Technologies
The successful implementation of a data lakehouse relies on a combination of foundational technologies and innovative architectural components.
Open Table Formats: The Cornerstone
The most crucial enabling technologies for the data lakehouse are open table formats. These layers sit atop cloud object storage and provide the transactional, schema enforcement, and metadata management capabilities that elevate a data lake to a lakehouse.
- Delta Lake: Developed by Databricks, Delta Lake adds ACID transactions, scalable metadata handling, and unified streaming and batch data processing to Apache Spark. It supports schema enforcement, evolution, and time travel.
- Apache Iceberg: Originating from Netflix, Iceberg is an open table format designed for huge analytical tables. It supports schema evolution, hidden partitioning, and provides fast scan performance over large datasets.
- Apache Hudi: Developed at Uber, Hudi provides record-level updates and deletes on data stored in HDFS or cloud object storage, making it suitable for incremental data processing and real-time analytics.
These formats manage metadata about the data files in the data lake, allowing various query engines to interact with the data as if it were in a traditional database table, complete with transactional guarantees.
Cloud-Native Integration
Data lakehouses are inherently cloud-native, leveraging the scalability, flexibility, and managed services offered by major cloud providers (AWS, Azure, GCP). This includes using object storage, serverless compute services, and managed analytical engines. The elasticity of the cloud allows lakehouses to scale up and down dynamically, optimizing resource utilization and cost.
Unified Data Access Layers
A key aspect of the data lakehouse is its ability to serve a wide array of data consumers through a unified access layer. This means that data scientists can use Python notebooks with Spark, BI analysts can use SQL tools, and application developers can access data via APIs, all interacting with the same underlying data assets within the lakehouse. This eliminates the need for data copies and ensures consistency across all data consumers.
Implementing and Leveraging the Data Lakehouse
Adopting a data lakehouse architecture involves strategic planning and a phased approach to maximize its benefits.
Strategic Considerations
Organizations considering a data lakehouse should evaluate their existing data infrastructure, the volume and variety of their data, and their specific analytical and operational needs. Key considerations include:
- Tooling and Ecosystem: Choosing an open table format and ensuring compatibility with existing analytical tools (e.g., Power BI, Tableau, Looker) and data processing frameworks (e.g., Apache Spark, Presto, Trino).
- Migration Strategy: Planning a gradual migration path from existing data lakes and data warehouses to the unified lakehouse architecture, potentially starting with new data pipelines.
- Data Governance: Establishing robust data governance policies, including data quality checks, access controls, and auditing mechanisms, from the outset.
- Team Skills: Investing in training for data engineers and analysts on new tools and paradigms associated with the lakehouse architecture.
Use Cases and Applications
The data lakehouse is remarkably versatile, catering to a broad spectrum of data applications:
- Business Intelligence & Reporting: Providing a reliable and performant foundation for traditional BI dashboards and reports, ensuring a single source of truth.
- Advanced Analytics & Data Science: Offering a flexible environment for machine learning model training, exploratory data analysis, and predictive analytics on large, diverse datasets.
- Real-time Analytics: Supporting streaming data ingestion and near real-time analytics for operational intelligence and immediate decision-making.
- Data Sharing & Collaboration: Facilitating secure and governed data sharing with internal teams and external partners through a centralized platform.
Best Practices
To fully harness the power of a data lakehouse, organizations should adhere to best practices such as:
- Data Cataloging and Metadata Management: Implementing a comprehensive data catalog to make data discoverable and understandable.
- Data Quality Automation: Integrating automated data quality checks and validation processes within data pipelines.
- Layered Architecture: Structuring the lakehouse into layers (e.g., raw, silver, gold zones) to progressively refine data quality and structure.
- Cost Optimization: Regularly monitoring and optimizing storage and compute costs, leveraging serverless and auto-scaling capabilities.
- Security by Design: Integrating security measures at every layer, from access control to data encryption.
Conclusion
The data lakehouse represents a significant leap forward in enterprise data architecture, offering a pragmatic solution to the long-standing challenges of managing diverse data types and analytical workloads. By marrying the unparalleled scalability and flexibility of data lakes with the transactional reliability and robust governance of data warehouses, it provides a unified, efficient, and cost-effective platform for modern data-driven organizations. As businesses continue to demand faster insights, higher data quality, and greater agility, the data lakehouse is poised to become the dominant architectural paradigm, empowering innovation and unlocking the full potential of enterprise data in the years to come.