In the realm of digital media, particularly when dealing with the high-resolution footage captured by modern drones and advanced cameras, the term “compress video” is frequently encountered. It’s a fundamental concept that underpins efficient storage, seamless sharing, and smooth playback of video content. At its core, video compression is a process of reducing the amount of data required to represent a video, making it smaller in file size without a significant perceptible loss in quality. This is achieved through sophisticated algorithms that identify and eliminate redundant information within the video stream. Understanding this process is crucial for anyone working with video, from casual drone pilots capturing aerial vistas to professional filmmakers crafting cinematic narratives.

The Fundamental Principles of Video Compression
Video compression is a complex interplay of mathematical techniques designed to exploit the inherent characteristics of video data. The primary goal is to reduce redundancy, which exists in several forms within a video sequence. Without compression, the sheer volume of data generated by high-definition cameras would render storage and transmission impractical.
Temporal Redundancy: What Stays the Same Over Time
One of the most significant sources of redundancy in video is temporal redundancy. This refers to the fact that consecutive frames in a video sequence are often very similar to each other. Think about a drone hovering steadily over a landscape. For many seconds, only minor changes occur due to wind or slight camera adjustments. Instead of storing each frame independently, compression techniques exploit this similarity.
Inter-frame Prediction (Motion Compensation)
The most common method for tackling temporal redundancy is inter-frame prediction, often referred to as motion compensation. This technique involves identifying and describing the movement of objects between frames. Instead of storing the entire content of a new frame, the encoder stores only the differences from a reference frame, along with a description of how these differences moved. For instance, if a bird flies across the sky, the encoder would identify the bird’s pixels in the previous frame, track its movement, and then only encode the small region where the bird is in the current frame, along with the motion vector indicating its displacement. This dramatically reduces the amount of data needed for frames that are largely static or have predictable movement.
Intra-frame Redundancy: What’s Within a Single Frame
While temporal redundancy addresses similarities between frames, intra-frame redundancy focuses on the redundancies within a single frame. This is analogous to how still image compression works, like in JPEGs. Within a single frame, there are often large areas of similar color or texture.
Spatial Redundancy Reduction
Spatial redundancy occurs when adjacent pixels within a frame have similar color values. Compression algorithms analyze these blocks of similar pixels and represent them more efficiently. Techniques like discrete cosine transform (DCT) or wavelet transforms are applied to convert pixel data into frequency components. The idea is that most of the visual information in a scene is concentrated in the lower frequencies, while high frequencies represent finer details. By quantizing or discarding some of the high-frequency components, a significant reduction in data can be achieved with minimal perceptible loss. For example, a large patch of blue sky will have many pixels with very similar color values. Instead of storing each pixel individually, the compression algorithm can represent this area with a few parameters describing its color and extent.
The Process of Video Compression: Encoding and Decoding
Video compression is a two-part process: encoding and decoding. Encoding is the process of compressing the video data, and decoding is the process of decompressing it for playback or editing.
Encoding: The Art of Shrinking Data
The encoding process is where the magic of compression happens. Modern video codecs, such as H.264 (AVC), H.265 (HEVC), and AV1, employ a combination of techniques to achieve high compression ratios. The general workflow involves several stages:
Color Space Transformation and Chroma Subsampling
Before applying other compression techniques, video data is often converted into a different color space, typically YUV, which separates luminance (brightness, Y) from chrominance (color, UV). The human eye is more sensitive to changes in brightness than in color. Chroma subsampling is a technique that exploits this by reducing the amount of color information stored relative to the brightness information. For example, in 4:2:0 chroma subsampling, for every four luminance samples, there are only two chrominance samples (one U and one V). This significantly reduces the data associated with color, as it’s less visually critical.
Motion Estimation and Compensation
As discussed earlier, this is a cornerstone of temporal compression. The encoder analyzes blocks of pixels in the current frame and searches for similar blocks in preceding or succeeding frames. Once a match is found, instead of encoding the entire block, it encodes a reference to the matching block and a motion vector describing its displacement.
Transform Coding
Blocks of pixels (or difference blocks from motion compensation) are then transformed using techniques like DCT. This converts the spatial pixel values into frequency coefficients. High-frequency coefficients, representing fine details and noise, are less important perceptually and can be more aggressively compressed.
Quantization
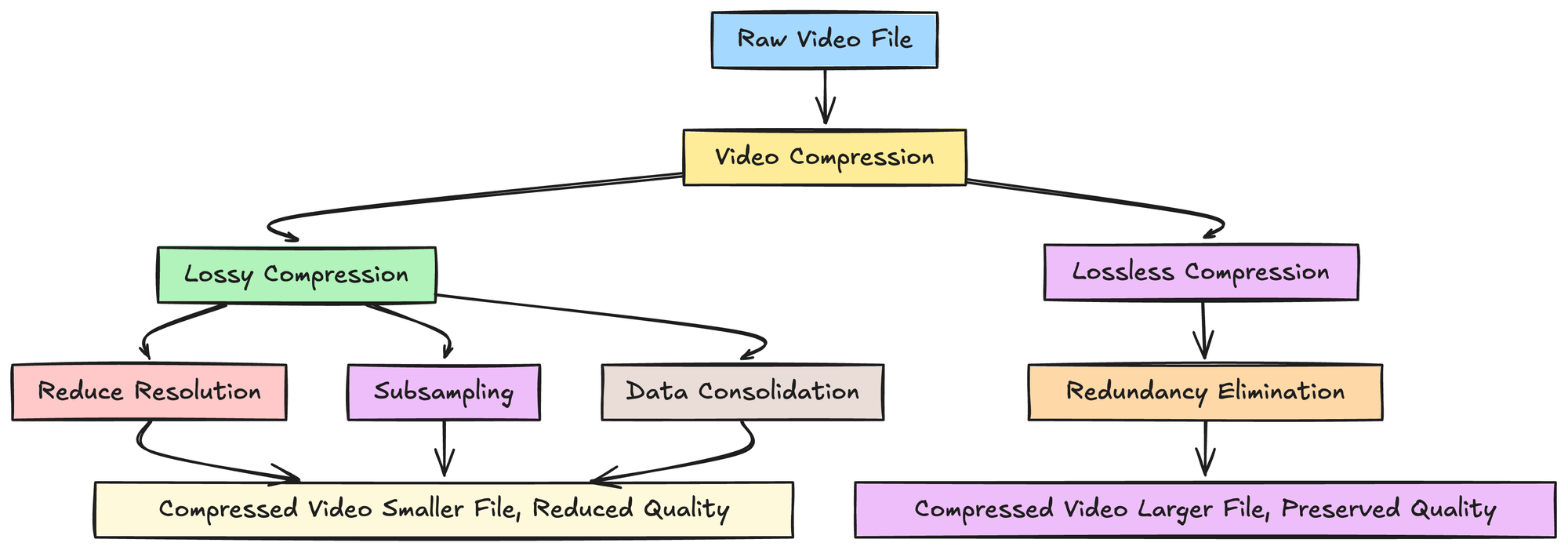
Quantization is the process of reducing the precision of the transform coefficients. This is where most of the lossy compression occurs. Less important coefficients are rounded or discarded altogether, leading to a reduction in file size. The level of quantization determines the trade-off between file size and image quality. Higher quantization means more data reduction but potentially more noticeable artifacts.
Entropy Coding
The final stage of encoding is entropy coding, a lossless compression technique. It assigns shorter codes to frequently occurring symbols (e.g., common color values or motion vectors) and longer codes to less frequent ones. Techniques like Huffman coding or Arithmetic coding are used here to further reduce the data size without discarding any information.
Decoding: Reconstructing the Visual Experience
The decoder’s job is to reverse the encoding process to reconstruct the video for viewing. This involves de-quantization, inverse transform, motion reconstruction, and finally, combining the reconstructed frames to display the video. The decoder uses the information provided by the encoder (motion vectors, difference data, quantized coefficients) to rebuild the video stream.
The Impact and Importance of Video Compression
The ability to compress video has had a profound impact on the digital landscape, enabling a wide range of technologies and applications that would otherwise be impossible. From the vast libraries of streaming services to the efficient storage of drone footage, compression is an indispensable tool.
Storage Efficiency: Making More with Less
One of the most direct benefits of video compression is its impact on storage requirements. High-definition video, especially at higher frame rates and resolutions like 4K or 8K, generates enormous amounts of data. Without compression, storing even a few minutes of such footage would require terabytes of storage. Compression algorithms reduce these file sizes by orders of magnitude, making it feasible to store hours of footage on consumer-grade hard drives, memory cards used in drones, and cloud storage platforms. This efficiency directly translates to lower costs for both individuals and businesses.
Transmission and Bandwidth: Enabling Seamless Streaming and Sharing
The internet, and by extension, wireless communication, has bandwidth limitations. Transmitting uncompressed video over these networks would be incredibly slow and often impossible for real-time streaming. Video compression is the backbone of online video streaming services like YouTube, Netflix, and Twitch. By reducing the amount of data that needs to be sent, compressed video allows for smooth playback even on relatively low-bandwidth connections. Similarly, sharing large video files, whether it’s drone footage sent to a client or home videos shared with family, is made practical through compression.
Real-time Applications: The Foundation of Modern Communication
Beyond storage and streaming, video compression is critical for many real-time applications. Video conferencing, online gaming with video elements, and live broadcasting all rely on efficient compression to transmit video data with minimal latency. The speed at which video can be encoded and decoded directly affects the responsiveness and quality of these interactive experiences. For drone pilots using FPV (First-Person View) systems, low-latency video transmission is paramount for safe and accurate control, and compression plays a vital role in achieving this balance between image quality and transmission speed.

Trade-offs: Quality vs. File Size
It’s important to acknowledge that most practical video compression techniques are “lossy.” This means that some information is discarded during the compression process. The goal is to discard information that is least perceptible to the human eye. However, at very high compression ratios, or when compressing footage that has already been compressed, these losses can become noticeable. This can manifest as blocky artifacts, blurring, or a general loss of fine detail. Understanding the compression settings used by your camera or editing software is crucial to balancing the need for smaller file sizes with the desire to maintain the highest possible image quality for your specific application, whether it’s aerial cinematography or simple sharing of vacation memories.