The central processing unit (CPU) is the brain of any modern electronic device, from your smartphone to a high-performance server. At its heart lies a fundamental concept that dictates its processing power and efficiency: the core. Understanding what a core is, how it functions, and how it impacts performance is crucial for anyone looking to grasp the inner workings of the technology that powers our digital lives. In essence, a processor core is an independent processing unit within the CPU, capable of executing its own set of instructions simultaneously. The more cores a processor has, the more tasks it can handle concurrently, leading to improved multitasking capabilities and faster overall operation.
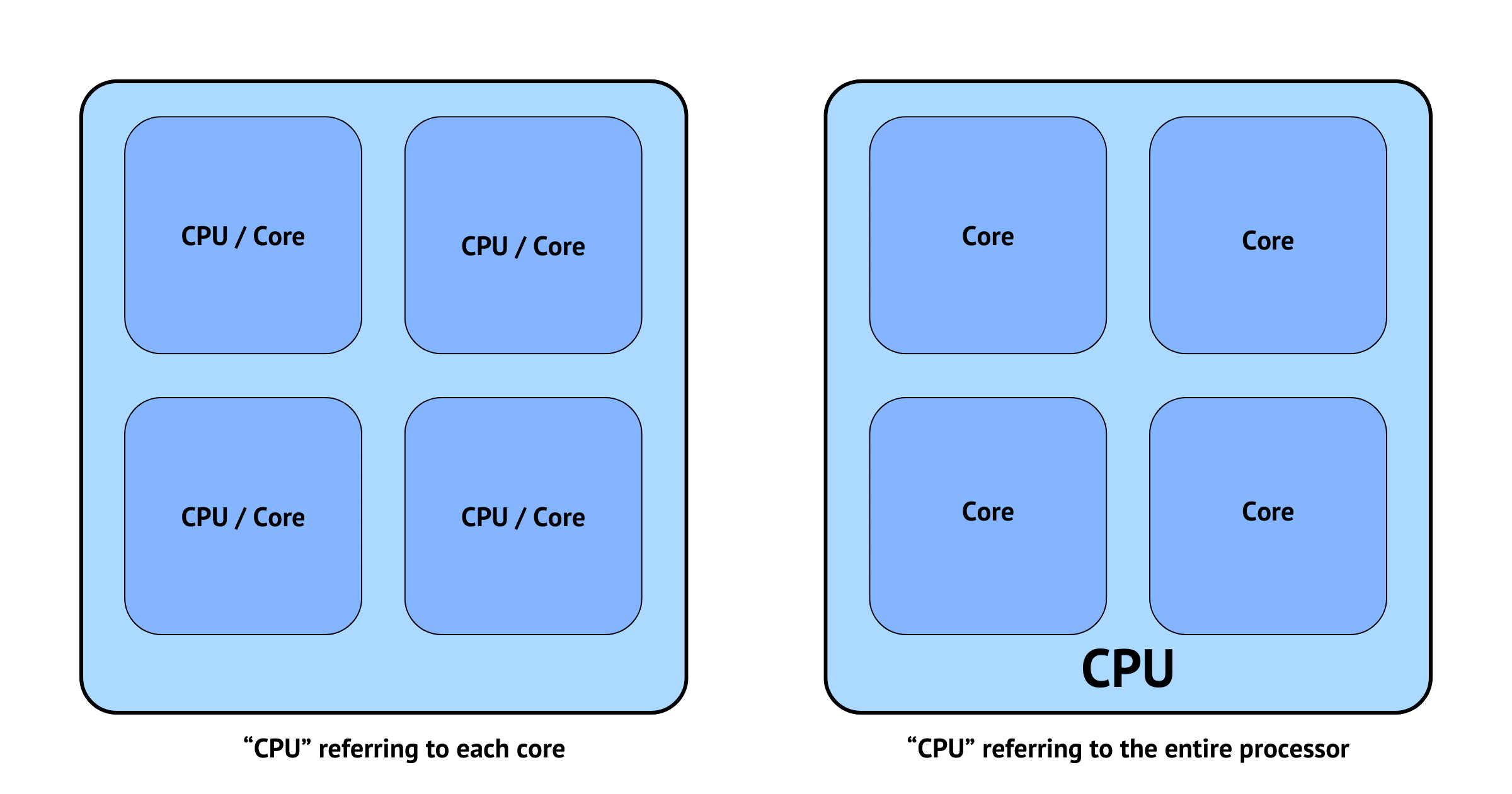
The Fundamental Building Block: Understanding the CPU Core
At its most basic, a processor core is a single, complete processing unit. Think of it as a miniaturized computer within the larger CPU. Each core contains its own arithmetic logic unit (ALU), control unit, and cache memory. These components work together to fetch, decode, and execute instructions from software.
The Anatomy of a Core: ALU, Control Unit, and Cache
The Arithmetic Logic Unit (ALU) is the workhorse of the core. It performs all the mathematical calculations (addition, subtraction, etc.) and logical operations (comparisons, boolean logic) required by programs. The speed and efficiency of the ALU directly contribute to how quickly a core can crunch numbers.
The Control Unit acts as the conductor of the orchestra. It fetches instructions from memory, decodes them, and directs the other components of the core and the CPU to execute them in the correct sequence. It’s responsible for managing the flow of data and instructions, ensuring everything happens in an orderly fashion.
Cache memory is a small, high-speed memory located directly on or very close to the core. It stores frequently accessed data and instructions, allowing the core to retrieve them much faster than if it had to access the main system RAM. Processors typically have multiple levels of cache (L1, L2, and sometimes L3), with L1 being the smallest and fastest, closest to the core.
From Single-Core to Multi-Core: The Evolution of Processing Power
The earliest processors were single-core, meaning they had only one processing unit. While capable, they were limited in their ability to handle multiple tasks simultaneously. If one task was computationally intensive, it could bog down the entire processor, making other applications slow to respond.
The advent of multi-core processors revolutionized computing. By integrating multiple cores onto a single chip, manufacturers could significantly boost performance. A dual-core processor has two independent cores, a quad-core has four, and high-end processors can have dozens or even hundreds of cores. This parallelism allows the CPU to execute multiple threads of execution concurrently, meaning different programs or different parts of the same program can run at the same time, leading to a much smoother and more responsive user experience.
The Impact of Core Count on Performance
The number of cores in a processor is a primary indicator of its potential performance, especially in scenarios involving multitasking and demanding applications. However, it’s not the only factor, and understanding its interplay with other architectural features is key.
Multitasking and Responsiveness: The Power of Parallelism
For everyday users, the most noticeable benefit of more cores is in multitasking. Imagine having multiple browser tabs open, streaming music, and running a word processor simultaneously. On a single-core processor, these tasks would compete for resources, leading to lag and slowdowns. A multi-core processor can assign different tasks to different cores, allowing them to run independently and without significant interference. This results in a far more fluid and responsive system.
For professional users and enthusiasts, this parallelism is even more critical. Applications like video editing, 3D rendering, scientific simulations, and software development inherently involve processing large datasets and complex computations that can be broken down into smaller, parallelizable tasks. A processor with more cores can distribute these tasks across its available processing units, dramatically reducing the time it takes to complete them. For instance, rendering a complex 3D scene might take hours on a dual-core processor but could be reduced to minutes on a processor with 16 or more cores.
Specialized Workloads and Threading
The effectiveness of multiple cores is heavily dependent on how well software is designed to utilize them. This is where the concept of threading comes in. A thread is the smallest sequence of programmed instructions that can be managed independently by a scheduler. Applications that are “multi-threaded” can divide their workload into multiple threads, which can then be executed by different cores simultaneously.
Programs designed for single-threaded execution will only ever utilize one core, regardless of how many are available. This is why simply having a high core count doesn’t guarantee a significant performance boost for every application. However, modern operating systems and application development have increasingly embraced multi-threading. Tasks like compiling code, running complex calculations in spreadsheets, and processing large images in photo editing software are often heavily multi-threaded, benefiting immensely from increased core counts.
Beyond Core Count: Architecture, Clock Speed, and Cache

While the number of cores is a significant performance metric, it’s essential to consider other crucial aspects of processor design. The overall performance of a CPU is a complex interplay of various factors, and focusing solely on core count can be misleading.
Clock Speed: The Pace of Instruction Execution
Clock speed, measured in gigahertz (GHz), represents how many cycles a processor core can complete per second. A higher clock speed means a core can execute instructions at a faster pace. For applications that are not heavily multi-threaded, or for certain specific operations within a multi-threaded application, clock speed can be a dominant factor in performance.
For example, a single-threaded application might run faster on a processor with fewer cores but a higher clock speed compared to a processor with more cores but a lower clock speed. This is because the single-threaded application can only utilize one core, and a faster core will process its instructions more quickly. However, in heavily multi-threaded workloads, the parallel processing power of multiple cores often outweighs the advantage of a slightly higher clock speed.
Cache Hierarchy: The Speed of Data Access
As mentioned earlier, cache memory plays a vital role in processor performance. It acts as a high-speed buffer between the CPU and the main system RAM. The larger and more efficient the cache, the more data and instructions the processor can keep readily accessible, reducing the need to access slower main memory.
Processors typically have L1, L2, and L3 caches. L1 is the smallest and fastest, usually dedicated to each core. L2 is larger and slightly slower, and L3 is the largest and slowest of the on-chip caches, often shared among all cores. A well-designed cache hierarchy can significantly improve performance by minimizing memory latency, allowing cores to spend more time processing data and less time waiting for it.
Architectural Innovations: IPC and Beyond
Beyond core count, clock speed, and cache, processor manufacturers constantly innovate with architectural advancements. One such advancement is Instructions Per Clock (IPC). This metric essentially measures how much work a processor core can accomplish in a single clock cycle. A processor with a higher IPC can perform more operations per cycle, making it more efficient even at the same clock speed as another processor.
Other architectural improvements include enhanced branch prediction (predicting which path of execution a program will take to avoid delays), improved instruction pipelines (breaking down instruction execution into stages for parallel processing within a single core), and specialized instruction sets (e.g., AVX for advanced vector operations) that accelerate specific types of computations. These subtle but significant architectural differences can lead to substantial performance disparities between processors that might otherwise seem similar based on core count and clock speed alone.
The Future of Processor Cores: Specialization and Integration
The trajectory of processor development points towards increasing specialization and deeper integration of different processing units. As the demands of computing evolve, so too do the designs of the processors that power them.
Heterogeneous Computing: Big.LITTLE and Beyond
A significant trend is the rise of heterogeneous computing. This approach involves combining different types of cores on a single chip to optimize for both performance and efficiency. The most well-known example is ARM’s big.LITTLE architecture, which pairs high-performance “big” cores with power-efficient “little” cores.
In this model, demanding tasks are handled by the big cores for maximum speed, while less intensive background tasks are managed by the little cores to conserve power. This dynamic allocation allows devices to offer impressive performance when needed without excessively draining the battery. This concept is extending beyond smartphones, with desktop and server CPUs exploring similar heterogeneous designs.

Integrated Graphics and Specialized Accelerators
Modern processors are also increasingly integrating other processing units beyond general-purpose CPU cores. Integrated Graphics Processing Units (iGPUs) are now standard in most consumer CPUs, providing graphics capabilities for everyday tasks and even some light gaming without the need for a discrete graphics card.
Furthermore, there’s a growing trend towards integrating specialized accelerators. These are hardware units designed to efficiently handle specific types of computations. Examples include:
- AI Accelerators (NPUs): Neural Processing Units are specifically designed to accelerate machine learning and artificial intelligence tasks, crucial for features like image recognition, natural language processing, and intelligent automation.
- Media Encoders/Decoders: Dedicated hardware for fast and efficient processing of video and audio codecs, vital for streaming, video editing, and gaming.
- Cryptography Accelerators: Hardware designed to speed up encryption and decryption processes, enhancing security for sensitive data.
The future of processors lies not just in simply adding more of the same type of core, but in intelligently combining a diverse array of specialized processing units to create highly efficient and powerful computing platforms tailored to the ever-expanding needs of technology. Understanding the role of cores, alongside these other architectural elements, provides a comprehensive view of the incredible engineering that drives our digital world.