The evolution of autonomous systems, from sophisticated unmanned aerial vehicles (UAVs) to self-driving cars and advanced robotic platforms, hinges on an intricate dance of sensors, algorithms, and decision-making processes. While the promise of enhanced efficiency, safety, and capability is immense, the inherent complexity of these systems also introduces a unique set of challenges. Among the more colloquial, yet critically important, discussions within the field of AI and robotics is the concept of “testicular torsion” – a term used to describe a specific category of cascading, self-reinforcing, and potentially catastrophic failure modes that can afflict autonomous systems.
This article delves into the metaphorical “testicular torsion” within autonomous systems, dissecting its nature, identifying its triggers, exploring its profound implications, and examining the innovative strategies being developed to prevent and mitigate such devastating system collapses. It’s a deep dive into the cutting-edge of resilience engineering for the intelligent machines that are increasingly shaping our world.
Understanding the Nature of Critical System Torsion
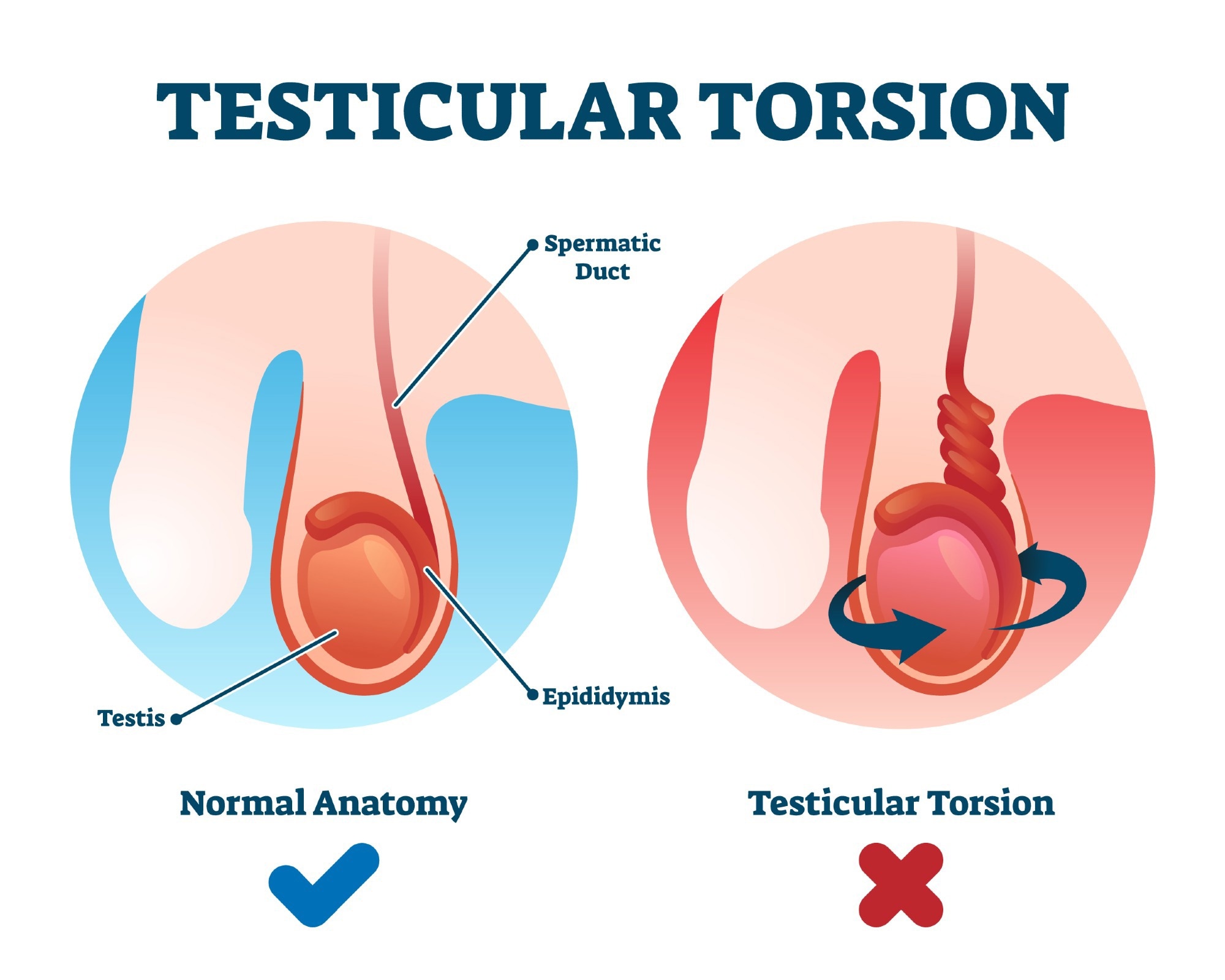
The term “testicular torsion,” when applied to autonomous systems, is not a literal medical reference. Instead, it serves as a vivid analogy for a failure state where a minor initial anomaly or instability escalates into a systemic breakdown. This escalation is characterized by positive feedback loops, where the output of a system component or process amplifies its own input or related inputs, leading to an uncontrolled and rapid degradation of performance. Unlike a simple bug or a singular component failure, “testicular torsion” represents a systemic collapse, often occurring with alarming speed and leaving the system in a state of complete incapacitation or unpredictable, hazardous behavior.
The Anatomy of a Cascading Failure
At its core, a cascading failure in autonomous systems involves several key elements:
- Initial Anomaly: This is the trigger. It could be a subtle sensor drift, a minor misinterpretation of environmental data, a glitch in a communication link, or an unexpected deviation from a planned trajectory. Crucially, this anomaly might be minor enough to be initially overlooked or deemed inconsequential by less robust monitoring systems.
- Feedback Loops: This is the engine of the escalation. In an autonomous system, various modules are interconnected. For instance, a navigation module relies on sensor data, a control module interprets navigation commands, and a perception module processes environmental information to update the navigation system. If the navigation system begins to drift slightly, it might provide slightly erroneous position data to the control module. The control module, attempting to correct this perceived error, might then issue commands that further exacerbate the original drift, creating a vicious cycle.
- Systemic Interdependence: Modern autonomous systems are highly integrated. A failure in one seemingly isolated subsystem can have ripple effects across the entire architecture. For example, a problem with the AI’s predictive modeling of other agents’ behavior could lead to inappropriate evasive maneuvers, which in turn might overload the propulsion system, causing further sensor degradation, and so on.
- Degradation of State Estimation: A critical aspect of autonomous operation is maintaining an accurate understanding of the system’s own state and its environment. Cascading failures often lead to a complete breakdown in this state estimation. The system loses its ability to reliably determine its position, orientation, velocity, or the characteristics of its surroundings.
- Loss of Control or Predictability: The ultimate outcome is a loss of effective control. The system may become erratic, unresponsive, or operate in ways that are entirely unpredictable and potentially dangerous. In severe cases, this can lead to a complete shutdown, a loss of communication, or even a hard crash.
The analogy to testicular torsion is apt because it implies a severe, internal, and often sudden incapacitation that arises from within the system’s own operational dynamics, rather than an external impact.
Differentiating from Other Failure Types
It’s important to distinguish “testicular torsion” from other common failure scenarios:
- Single Point of Failure (SPOF): While a SPOF is a single component whose failure can bring down the entire system, “testicular torsion” is more about a process of failure amplification. A SPOF is a design flaw, whereas “testicular torsion” is a dynamic operational breakdown.
- Graceful Degradation: Many systems are designed to continue operating with reduced functionality when a component fails. “Testicular torsion” represents the opposite – a rapid and complete loss of functionality.
- Software Bugs: Standard software bugs are typically localized errors in code. While bugs can contribute to the initial anomaly, “testicular torsion” describes the systemic collapse that ensues, often due to the interaction of multiple components and algorithms under stress.
- Hardware Malfunction: A straightforward hardware failure (e.g., a motor burning out) is usually a direct cause. “Testicular torsion” is a more complex phenomenon where hardware might be operating within its parameters, but the way it’s being controlled or interpreted leads to the catastrophic outcome.
Triggers and Contributing Factors in Autonomous Systems
The conditions that can precipitate “testicular torsion” in autonomous systems are varied and often arise from the interplay of complex design choices, environmental factors, and operational stresses. Understanding these triggers is paramount for designing resilient autonomous platforms.
Environmental and Operational Stresses
The real world is a dynamic and often unpredictable environment. Autonomous systems must contend with a wide array of external conditions that can challenge their operational integrity:
- Adverse Weather Conditions: Heavy rain, fog, snow, strong winds, and extreme temperatures can degrade sensor performance (e.g., camera visibility, lidar accuracy) and impact the physical dynamics of the system (e.g., flight stability for drones). A slight degradation in sensor readings, if not properly handled, can become the initial anomaly.
- Unforeseen Obstacles and Dynamic Environments: Unexpected objects appearing in the path, rapidly changing traffic patterns, or sudden ground surface alterations can present challenges that the system’s prediction and planning algorithms may not have adequately accounted for.
- GPS/GNSS Degradation or Spoofing: Reliance on Global Navigation Satellite Systems (GNSS) is common, but signal loss due to urban canyons, jamming, or malicious spoofing can severely disrupt navigation, forcing the system to rely on less precise or potentially misleading alternative sensors.
- Communication Loss or Interference: For networked autonomous systems, intermittent or complete loss of communication can isolate critical control loops or prevent essential data sharing, leading to degraded decision-making.
- High-Speed Maneuvers and Dynamic Loads: Rapid acceleration, deceleration, or complex maneuvering can place significant stress on the system’s control surfaces, actuators, and power distribution, potentially leading to unexpected physical responses that feedback into the control loop.
Algorithmic and Software Vulnerabilities
The intelligence of autonomous systems lies in their algorithms. However, even sophisticated AI can harbor vulnerabilities that, under certain conditions, can initiate a cascade of failures:
- Edge Cases and Unforeseen Scenarios: AI models are trained on vast datasets, but it’s impossible to cover every conceivable scenario. When an autonomous system encounters an “edge case” – a situation significantly different from its training data – its responses can become unpredictable and lead to erroneous decisions.
- Sensor Fusion Errors: Most autonomous systems integrate data from multiple sensors (e.g., cameras, lidar, radar, IMUs). If the fusion algorithms incorrectly weigh or interpret conflicting data from different sensors, it can create a distorted view of reality, leading to flawed navigation or control commands.
- Control System Instability: Control loops, designed to maintain a desired state, can become unstable if not properly tuned. This instability can manifest as oscillations or overcorrection, which, if not damped, can lead to runaway behavior.
- Prediction Model Failures: AI systems often rely on predicting the future behavior of other agents or environmental elements. If these prediction models are overly simplistic, inaccurate, or fail to adapt to changing circumstances, they can lead to critical misjudgments, such as misjudging the speed of an oncoming vehicle or the trajectory of a falling object.
- Computational Overload or Latency: Complex real-time processing demands can lead to computational bottlenecks. If the system cannot process incoming data and execute commands within the required timeframes, latency can build up, disrupting the synchronized operation of various subsystems.
Design and Implementation Flaws
The architecture and implementation of autonomous systems also play a critical role in their susceptibility to these failure modes:
- Insufficient Redundancy: Relying on single critical components without backup systems significantly increases the risk of a SPOF leading to a larger failure.
- Inadequate Fault Detection and Handling: The absence of robust mechanisms to detect anomalies early and initiate appropriate fallback or mitigation strategies leaves the system vulnerable to escalating problems.
- Poorly Defined State Transition Logic: The logic governing how the system moves between different operational states (e.g., from cruising to emergency braking) can be a source of failure if not meticulously designed and tested.
- Over-Reliance on a Single Sensing Modality: If a system heavily relies on one type of sensor and that sensor is compromised, the entire perception system can be rendered unreliable.
Implications of System Torsion: The Cost of Failure
The consequences of a “testicular torsion” event in an autonomous system can be severe, impacting not only the operational integrity of the system itself but also broader safety, economic, and ethical considerations. Understanding these implications underscores the critical importance of developing robust preventive and mitigation strategies.

Safety and Risk Assessment
The most immediate concern is safety. When an autonomous system enters a state of “torsion,” its behavior becomes unpredictable. This poses direct risks to:
- Human Life and Well-being: Autonomous vehicles operating erratically can cause accidents, endangering passengers, pedestrians, and other road users. Drones operating out of control could crash into people or infrastructure.
- Property Damage: Uncontrolled flight or movement can lead to collisions with buildings, infrastructure, or other assets, resulting in significant financial losses.
- Environmental Hazards: In industrial or military applications, a system failure could lead to the release of hazardous materials or unintended destruction.
A thorough risk assessment for any autonomous system must explicitly consider the likelihood and potential impact of such cascading failure modes.
Economic and Operational Disruption
Beyond immediate safety concerns, the economic ramifications can be substantial:
- Mission Failure: For commercial or scientific missions, a catastrophic failure means the objective is not achieved, leading to wasted resources and lost opportunities.
- Financial Losses: The cost of repairing or replacing damaged autonomous hardware can be considerable. Furthermore, downtime due to investigations and repairs can disrupt supply chains or critical services.
- Loss of Trust and Reputation: Repeated or high-profile failures can erode public and industry confidence in autonomous technology, slowing down adoption and investment.
Ethical and Liability Challenges
The advent of autonomous systems brings with it complex ethical and legal quandaries, particularly when failures occur:
- Accountability: Determining who is at fault when an autonomous system fails catastrophically can be challenging. Is it the software developer, the hardware manufacturer, the operator, or the system itself? The emergent nature of “torsion” makes direct blame assignment difficult.
- Decision-Making in Crisis: If an autonomous system is faced with an unavoidable crisis that could lead to harm, the ethical frameworks embedded within its decision-making algorithms become paramount. A failure to handle such a crisis appropriately could be considered an ethical failure.
- Regulatory Hurdles: Governing bodies are constantly grappling with how to regulate increasingly sophisticated autonomous systems. Understanding and mitigating failure modes like “testicular torsion” is crucial for establishing effective safety standards and certification processes.
Resilience Engineering: Strategies to Prevent and Mitigate System Torsion
The pursuit of highly reliable autonomous systems necessitates a proactive and sophisticated approach to resilience engineering. The goal is not just to prevent failures but to ensure that even when anomalies occur, the system can recover gracefully or fail safely. This involves a multi-layered strategy encompassing design, development, testing, and operational monitoring.
Robust Design Principles
The foundation of resilience lies in the initial design of the autonomous system:
- Redundancy and Diversity: Implementing redundant critical components (e.g., multiple flight controllers, redundant sensor suites) and employing diverse algorithms or sensing modalities can prevent a single point of failure from triggering a cascade. For example, using both vision and lidar for obstacle detection provides a fallback if one sensor is compromised.
- Fail-Safe and Fail-Operational Architectures: Systems should be designed with clear strategies for what happens when a failure is detected. A “fail-safe” system aims to reach a safe state (e.g., land safely, stop). A “fail-operational” system can continue to operate, albeit with reduced capability, to complete its mission or reach a safe landing zone.
- Modular Design and Decoupling: Breaking down complex systems into independent modules with well-defined interfaces can limit the blast radius of a failure. If one module fails, it should not directly impact the operation of other unrelated modules.
- Bounded Control and State Machines: Employing rigorous state machines and bounded control loops ensures that the system operates within predictable parameters. This helps prevent runaway conditions where control outputs become excessive or oscillatory.
Advanced Monitoring and Anomaly Detection
The ability to detect subtle anomalies before they escalate is critical. This involves sophisticated real-time monitoring systems:
- Health Monitoring and Diagnostics: Continuously monitoring the performance of all subsystems, including sensor readings, actuator responses, computational load, and communication integrity.
- Predictive Anomaly Detection: Utilizing machine learning models to identify deviations from normal operating patterns. These models can learn the system’s typical behavior and flag subtle inconsistencies that might indicate an incipient failure.
- Cross-Sensor Validation: Comparing data from different sensors to identify discrepancies. If a camera sees an obstacle but the lidar does not, this anomaly needs to be investigated.
- System State Verification: Regularly verifying that the system’s perceived state matches its actual physical state and the external environment.
Intelligent Recovery and Reconfiguration Mechanisms
When anomalies are detected, the system needs to be able to respond intelligently:
- Graceful Degradation Strategies: If a component fails, the system should have pre-defined strategies to reconfigure itself and continue operating with reduced functionality. This might involve relying on a secondary sensor, reducing operational speed, or disabling non-essential features.
- Re-Initialization and Reset Procedures: In some cases, a partial or full system reset might be necessary to clear transient errors and restore stable operation.
- Dynamic Re-planning and Re-tasking: If a failure significantly alters the system’s capabilities or the environment, the system should be able to dynamically re-plan its mission or adapt its objectives.
- Human-in-the-Loop Intervention: For critical or complex situations, mechanisms for seamless handover to human operators are essential. This allows for human judgment and experience to resolve issues that the autonomous system cannot handle.
Rigorous Testing and Simulation
The development process must include extensive validation:
- Extensive Simulation: Utilizing high-fidelity simulations to test the system’s response to a wide range of environmental conditions and failure scenarios, including those that mimic “testicular torsion.”
- Hardware-in-the-Loop (HIL) Testing: Integrating actual hardware components into simulated environments to test their real-world performance and interactions.
- Field Testing and Empirical Validation: Conducting real-world tests in controlled environments and eventually in operational settings to validate the system’s resilience under diverse conditions.
- Adversarial Testing: Intentionally creating stressful or misleading inputs to probe the system’s vulnerabilities and ensure it can withstand unexpected challenges.
The ongoing evolution of autonomous systems demands a deep understanding of their potential failure modes. By treating phenomena like “testicular torsion” not as obscure possibilities but as critical design considerations, engineers can build more robust, reliable, and ultimately safer intelligent machines that are capable of navigating the complexities of the real world. The future of AI and robotics hinges on our ability to engineer for resilience, ensuring that our creations are not only intelligent but also indomitably dependable.