The realm of artificial intelligence is rapidly expanding, and at its forefront are powerful language models that are changing how we interact with technology. Among these, Generative Pre-trained Transformers, or GPTs, have emerged as a particularly influential force. But what exactly is a GPT, and what makes it so significant in the landscape of AI and technological innovation? This article delves into the core of GPT technology, exploring its architecture, capabilities, and the profound impact it’s having on various fields, particularly within the broader domain of Tech & Innovation.
GPTs represent a monumental leap forward in natural language processing (NLP). They are a type of artificial neural network specifically designed to understand, generate, and manipulate human-like text. Their “generative” nature means they can create new content, “pre-trained” signifies they are initially trained on vast datasets of text, and “transformer” refers to the underlying neural network architecture that makes them so effective. This combination has led to AI systems capable of tasks that were once considered exclusively human domains, such as writing coherent essays, generating creative stories, answering complex questions, and even assisting in coding.

The implications of GPT technology are far-reaching, touching everything from how we search for information to how we automate complex tasks. In the context of Tech & Innovation, GPTs are not just a development; they are a paradigm shift, accelerating innovation across numerous sectors. They empower developers with new tools, enable more intuitive human-computer interfaces, and unlock possibilities for advanced automation and intelligent systems.
The Transformer Architecture: The Engine of GPT
At the heart of every GPT model lies the transformer architecture, a groundbreaking neural network design introduced in the seminal 2017 paper “Attention Is All You Need.” This architecture revolutionized NLP by moving away from sequential processing models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks. Instead, transformers leverage a mechanism called “attention” to weigh the importance of different words in an input sequence, regardless of their position. This allows them to capture long-range dependencies in text much more effectively, leading to a deeper understanding of context and meaning.
Self-Attention: Understanding Contextual Relationships
The key innovation within the transformer architecture is the self-attention mechanism. Unlike RNNs, which process text word by word, self-attention allows the model to consider all words in the input simultaneously. For each word, it calculates an “attention score” to every other word in the sentence, determining how relevant they are to each other. This means that a word’s meaning is not just influenced by its immediate neighbors but by its entire context. For example, in the sentence “The bank is on the river bank,” self-attention can distinguish between the financial institution and the land along the river by looking at the surrounding words. This ability to grasp nuanced contextual relationships is fundamental to GPT’s linguistic prowess.
Positional Encoding: Maintaining Word Order
While self-attention excels at understanding relationships, it inherently lacks a sense of word order. To address this, transformers employ positional encoding. This process adds information about the position of each word in the sequence to its input representation. By doing so, the model can distinguish between words that are the same but appear in different positions, preserving the grammatical structure and semantic flow of the text. Without positional encoding, a sentence like “dog bites man” would be indistinguishable from “man bites dog” to the attention mechanism, leading to incorrect interpretations.
Encoder-Decoder Structure (and its Evolution in GPT)
The original transformer architecture featured an encoder-decoder structure. The encoder processed the input sequence and created a rich representation, while the decoder used this representation to generate an output sequence. However, GPT models, particularly those focused on text generation, often employ a decoder-only architecture. This simplified structure is optimized for autoregressive generation, meaning the model predicts the next word in a sequence based on all the preceding words. This autoregressive nature is what allows GPTs to produce coherent and contextually relevant text, sentence by sentence.
The Power of Pre-training and Fine-tuning

The “pre-trained” aspect of GPTs is as crucial as its transformer architecture. This phase involves training the model on an enormous and diverse corpus of text data – billions of words from books, articles, websites, and more. During this extensive training, the GPT learns grammar, facts about the world, reasoning abilities, and various writing styles. This foundational knowledge is what enables GPTs to perform a wide range of language tasks without needing explicit instruction for each one.
Unsupervised Learning on Massive Datasets
The pre-training process is typically unsupervised, meaning the model learns by predicting missing words or the next word in a sequence. For instance, it might be given a sentence with a word masked out and tasked with predicting that word. By performing this task millions upon millions of times across a vast and varied dataset, the GPT develops a sophisticated understanding of language patterns, semantic relationships, and factual information. This massive scale of training allows it to generalize its knowledge to new, unseen data.
Fine-tuning for Specialized Tasks
Once pre-trained, a GPT model can be “fine-tuned” for specific downstream tasks. This involves further training the model on a smaller, task-specific dataset. For example, if the goal is to build a chatbot for customer service, the pre-trained GPT would be fine-tuned on a dataset of customer service conversations. This allows the model to adapt its general language understanding to the particular nuances, terminology, and interaction styles required for that specific application. This two-stage process – broad pre-training followed by targeted fine-tuning – makes GPTs incredibly versatile and efficient.
Applications and Innovations Fueled by GPT
The capabilities unlocked by GPT technology are driving innovation across numerous fields, extending far beyond simple text generation. In the domain of Tech & Innovation, GPTs are enabling new forms of automation, enhancing user experiences, and creating entirely new possibilities for how we interact with and leverage technology.
Natural Language Understanding and Generation
At its core, GPT excels at understanding and generating human language. This translates to applications like advanced chatbots that can hold nuanced conversations, sophisticated content creation tools that can draft articles, marketing copy, or even creative fiction, and intelligent summarization systems that can condense lengthy documents into concise overviews. This ability to process and produce human-like text is transforming how businesses communicate with their customers and how individuals consume information.
Code Generation and Assistance
One of the most significant emerging applications of GPT technology is in the realm of software development. GPT models can be trained to understand programming languages and assist developers by generating code snippets, debugging existing code, explaining complex code structures, and even writing entire programs from natural language descriptions. This “AI pair programmer” capability dramatically speeds up the development lifecycle, lowers the barrier to entry for aspiring coders, and allows experienced developers to focus on more complex problem-solving.
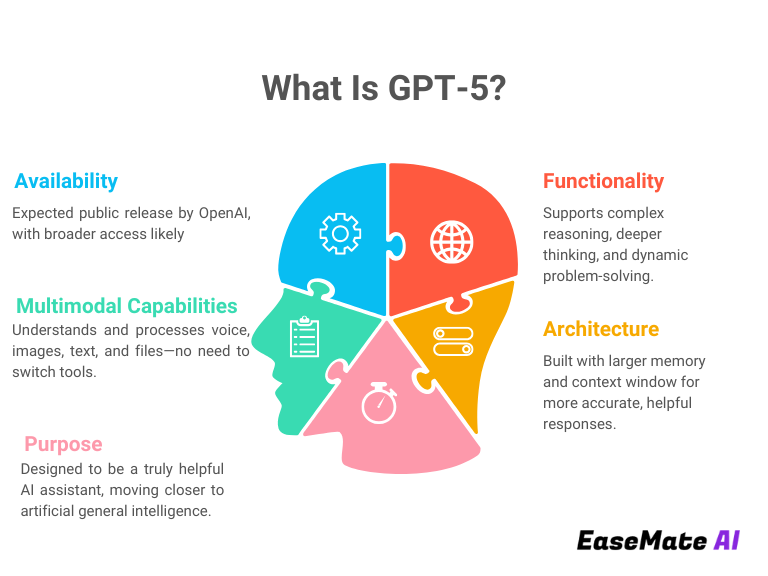
Driving Autonomous Systems and Intelligent Assistants
Beyond text, GPTs are becoming integral to the development of more sophisticated autonomous systems and intelligent assistants. Their ability to process and understand complex instructions, interpret user intent, and generate logical responses makes them ideal for powering virtual assistants that can manage schedules, control smart home devices, and provide personalized recommendations. Furthermore, in fields like robotics and autonomous vehicles, GPTs can process sensor data and translate it into actionable commands or assist in decision-making processes, contributing to more intelligent and responsive autonomous operations.
The continuous evolution of GPT technology, with models becoming larger, more sophisticated, and more accessible, promises an even more exciting future. As these powerful AI tools become more integrated into our technological landscape, they will undoubtedly continue to redefine the boundaries of what is possible, pushing the frontiers of innovation in countless ways.