The Tidyverse is a collection of R packages designed for data science. These packages share an underlying design philosophy, grammar, and data structures, making them work together seamlessly. The primary goal of the Tidyverse is to make common data science tasks more intuitive, efficient, and enjoyable for R users. It aims to provide a consistent and opinionated framework for data manipulation, exploration, and visualization, fostering a more productive workflow.
The Core Principles of Tidy Data
At the heart of the Tidyverse’s philosophy lies the concept of “tidy data.” Tidy data is a standardized way of structuring datasets, making them easier to analyze and visualize. The principles of tidy data are as follows:
1. Each variable forms a column.
In a tidy dataset, each column represents a distinct variable. This means that if you have collected data on multiple attributes, each attribute should have its own dedicated column. For example, if you are analyzing sales data, you might have columns for “Product Name,” “Date,” “Quantity Sold,” and “Price.” This clear separation of variables prevents confusion and allows for straightforward analysis.
2. Each observation forms a row.
Each row in a tidy dataset represents a single observation or a single data point. This observation should capture the values of all relevant variables for a specific instance. Continuing the sales data example, each row would represent a single sale of a particular product on a specific date, with columns detailing the product, date, quantity, and price of that individual sale. This structure ensures that each unit of observation is clearly defined.
3. Each type of observational unit forms a table.
Observational units are the entities about which you are collecting data. If you are collecting data about customers and their purchases, you would likely have separate tables for “Customers” and “Purchases.” The “Customers” table would contain information about each individual customer, while the “Purchases” table would detail each transaction. This separation of observational units prevents redundancy and makes it easier to manage relationships between different types of data.
By adhering to these principles, data becomes more organized and amenable to programmatic manipulation. The Tidyverse packages are built with these principles in mind, enabling users to work with data in a consistent and predictable manner.
Key Tidyverse Packages and Their Roles
The Tidyverse is not a single entity but rather an ecosystem of interconnected packages. While there are many packages within the Tidyverse, a few core ones form the foundation of most data science workflows. Understanding these key packages is crucial to leveraging the full power of the Tidyverse.
1. dplyr: The Grammar of Data Manipulation
dplyr is arguably the most central package in the Tidyverse for data manipulation. It provides a set of intuitive verbs that allow you to perform common data wrangling tasks with remarkable ease. These verbs act as building blocks for constructing complex data transformations.
select(): This function allows you to choose specific columns from a dataset. You can select columns by name, position, or even by patterns in their names. For example,select(data, column1, column3)would keep onlycolumn1andcolumn3.filter(): This function enables you to subset rows based on specific conditions. You can filter data to include only observations that meet certain criteria, such asfilter(data, sales > 100).mutate(): This verb is used to create new columns or modify existing ones. You can add calculations, derive new features, or transform existing variables. For instance,mutate(data, profit = revenue - cost)would create a new “profit” column.arrange(): This function allows you to sort rows based on the values in one or more columns. You can sort in ascending or descending order.arrange(data, date)would sort the data by date.summarise(): This function reduces multiple values down to a single summary. It’s commonly used to calculate statistics like means, medians, counts, or sums for groups of data. For example,summarise(data, average_sales = mean(sales))would calculate the average sales.group_by(): Often used in conjunction withsummarise(), this function groups data by one or more categorical variables. Subsequent operations are then performed independently on each group. For instance,group_by(data, product_category)would allow you to calculate summary statistics for each product category separately.
The combination of these verbs allows for powerful and readable data manipulation pipelines.
2. ggplot2: The Grammar of Graphics for Data Visualization
ggplot2 is the cornerstone of data visualization within the Tidyverse. It’s built upon the “Grammar of Graphics,” a theoretical framework that breaks down the process of creating visualizations into distinct components. This approach makes ggplot2 incredibly flexible and allows for the creation of a wide range of plot types with a consistent syntax.
- Data: The dataset to be visualized.
- Aesthetics (
aes()): These map variables in your data to visual properties of the plot, such as x-axis, y-axis, color, size, and shape. For example,aes(x = date, y = sales)maps the “date” variable to the x-axis and the “sales” variable to the y-axis. - Geometries (
geom_): These are the visual elements used to represent the data, such as points (geom_point()), lines (geom_line()), bars (geom_bar()), or smooth lines (geom_smooth()). - Facets: These allow you to create multiple plots based on subsets of your data, effectively creating small multiples.
- Statistics: Transformations applied to the data before plotting (e.g., calculating counts for a bar chart).
- Coordinates: The system used to map data values to positions on the plot.
- Themes: Controls the non-data elements of the plot, such as fonts, backgrounds, and gridlines.
The layered nature of ggplot2 allows you to build complex plots incrementally, adding layers of data, aesthetics, and geoms to create insightful visualizations.
3. tidyr: Tools for Tidying Data
While dplyr focuses on manipulating data once it’s in a tidy format, tidyr is designed to help you get your data into that tidy format. Many real-world datasets are not inherently tidy, and tidyr provides functions to reshape and clean them.
pivot_longer(): This function takes wide data (where multiple variables are spread across columns) and pivots it into a longer format, where each original column becomes a row. This is incredibly useful when you have data that is structured with one column for each time point or measurement.pivot_wider(): The inverse ofpivot_longer(), this function takes long data and pivots it into a wider format. This is useful when you want to see multiple measurements for a single observation side-by-side.separate(): This function splits a single column into multiple columns based on a delimiter. For example, if you have a “Date” column that combines year, month, and day (e.g., “2023-10-27”),separate()can split it into “Year,” “Month,” and “Day” columns.unite(): The inverse ofseparate(), this function combines multiple columns into a single column.
These functions are essential for preparing your data for analysis and visualization, ensuring it conforms to the tidy data principles.
The Tidyverse Workflow: Connecting the Dots
The power of the Tidyverse lies in its ability to create coherent and readable data analysis pipelines. The “pipe” operator (%>% or |> in R 4.1+) is a fundamental element of this workflow, allowing you to chain together multiple operations in a logical sequence.
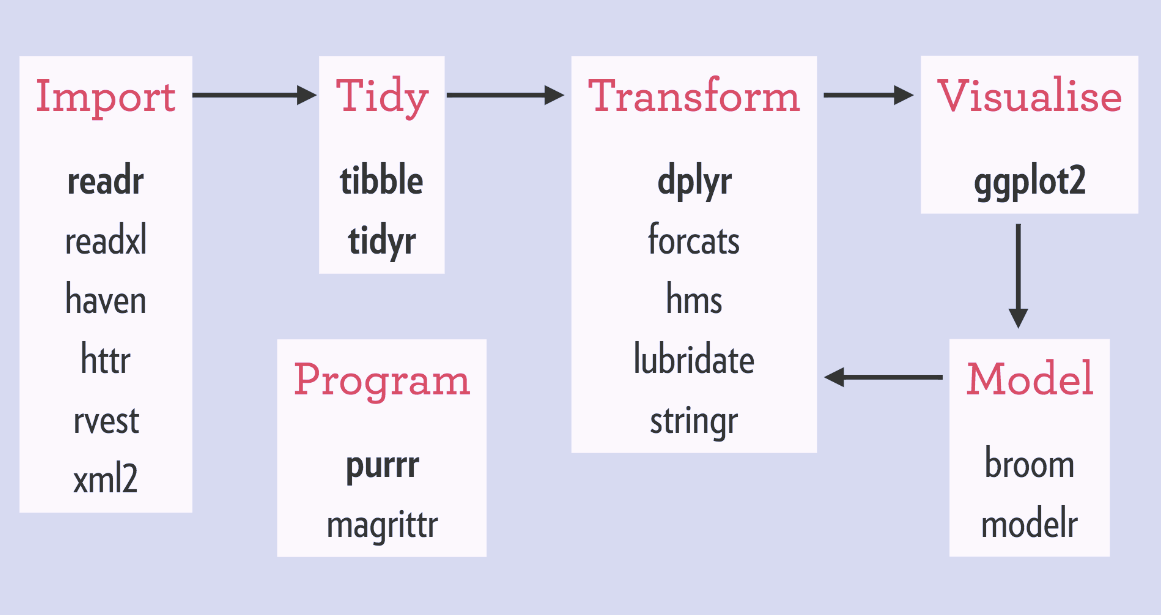
1. Data Import and Inspection
The first step in any data analysis is to import your data into R and get a feel for its structure. Tidyverse packages like readr offer fast and friendly functions for reading various file formats (e.g., read_csv(), read_tsv()). Once imported, functions from dplyr like head(), glimpse(), and summary() are invaluable for initial inspection. glimpse() provides a concise overview of columns, their types, and the first few values.
![]()
2. Data Cleaning and Transformation
This is where tidyr and dplyr shine. You’ll use tidyr functions to reshape and clean your data, ensuring it adheres to the tidy data principles. Then, dplyr verbs come into play to filter, select, mutate, and arrange your data according to your analytical needs. For instance, you might filter out irrelevant rows, select only the columns you need, create new calculated columns, and sort the data by a specific variable.
Consider this example of a typical dplyr and pipe workflow:
library(dplyr)
library(readr)
# Assume 'sales_data.csv' is a file containing sales information
sales_data <- read_csv("sales_data.csv")
clean_and_transformed_sales <- sales_data %>%
filter(region == "North") %>% # Keep only sales from the North region
select(product, date, quantity, price) %>% # Select relevant columns
mutate(total_revenue = quantity * price) %>% # Calculate total revenue
group_by(product) %>% # Group data by product
summarise(
average_revenue = mean(total_revenue),
total_quantity_sold = sum(quantity)
) %>%
arrange(desc(average_revenue)) # Arrange by average revenue in descending order
print(clean_and_transformed_sales)
This pipeline clearly shows the steps involved: reading the data, filtering, selecting, creating a new variable, grouping, summarizing, and finally arranging. The pipe operator makes the flow of data and operations easy to follow.
3. Data Visualization and Exploration
Once your data is clean and transformed, ggplot2 is used to create compelling visualizations. You can explore relationships between variables, identify patterns, and communicate your findings effectively. The layered approach of ggplot2 allows you to build intricate plots by adding different geoms and aesthetics.
For example, to visualize the average revenue per product:
library(ggplot2)
ggplot(clean_and_transformed_sales, aes(x = product, y = average_revenue, fill = product)) +
geom_bar(stat = "identity") +
labs(title = "Average Revenue by Product (North Region)",
x = "Product",
y = "Average Revenue") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # Rotate x-axis labels
This ggplot2 code generates a bar chart showing the average revenue for each product in the North region, making it easy to compare performance.
4. Reporting and Communication
The Tidyverse ecosystem also extends to tools for reporting and communicating your analyses. Packages like rmarkdown allow you to integrate R code, text, and visualizations into dynamic reports, presentations, and dashboards. This ensures that your analyses are not only reproducible but also easily shareable and understandable by a wider audience.
Benefits of Adopting the Tidyverse
The widespread adoption of the Tidyverse is a testament to its significant benefits for data scientists and analysts.
1. Enhanced Readability and Maintainability
The consistent syntax and the use of the pipe operator (%>% or |>) make Tidyverse code highly readable. Complex operations can be expressed in a clear, sequential manner, making it easier for individuals to understand their own code later on, and for others to collaborate on projects. This improved readability directly translates to better maintainability of codebases.
2. Increased Productivity
By providing intuitive and efficient tools for common data science tasks, the Tidyverse significantly boosts productivity. Instead of spending excessive time wrestling with base R functions for data manipulation and visualization, users can leverage the specialized functions within the Tidyverse to achieve results more quickly and with less effort.
3. Consistency and Predictability
The Tidyverse promotes a consistent approach to data analysis. The shared design philosophy and grammatical structure across packages mean that once you learn the core concepts, applying them to different tasks and datasets becomes more intuitive. This predictability reduces the cognitive load and allows for a more streamlined workflow.
4. Strong Community and Ecosystem
The Tidyverse has a vibrant and active community of users and developers. This means abundant resources, tutorials, and support are readily available. The extensive ecosystem of Tidyverse-compatible packages continues to grow, offering solutions for a vast array of data science challenges.
5. Encourages Best Practices
The Tidyverse’s emphasis on tidy data and its well-designed functions naturally encourage users to adopt best practices in data handling and analysis. This leads to more robust, reproducible, and reliable data science workflows.
In conclusion, the Tidyverse represents a paradigm shift in how data analysis is approached in R. By providing a coherent, opinionated, and powerful set of tools, it empowers individuals to tackle complex data science problems with greater efficiency, clarity, and enjoyment. Whether you are a beginner or an experienced R user, embracing the Tidyverse can significantly elevate your data science capabilities.