Google indexing is the foundational process that allows the world’s most popular search engine to understand, organize, and retrieve information from the vast expanse of the internet. Imagine the internet as an unimaginably large library, constantly receiving new books (web pages) and updates to existing ones. Google indexing is the meticulous and continuous work of librarians who read, catalog, and shelve every single one of these books so that when someone asks a question (performs a search), the librarian can quickly and accurately point them to the most relevant resources. Without this intricate system of cataloging, searching the internet would be an impossible and chaotic endeavor.
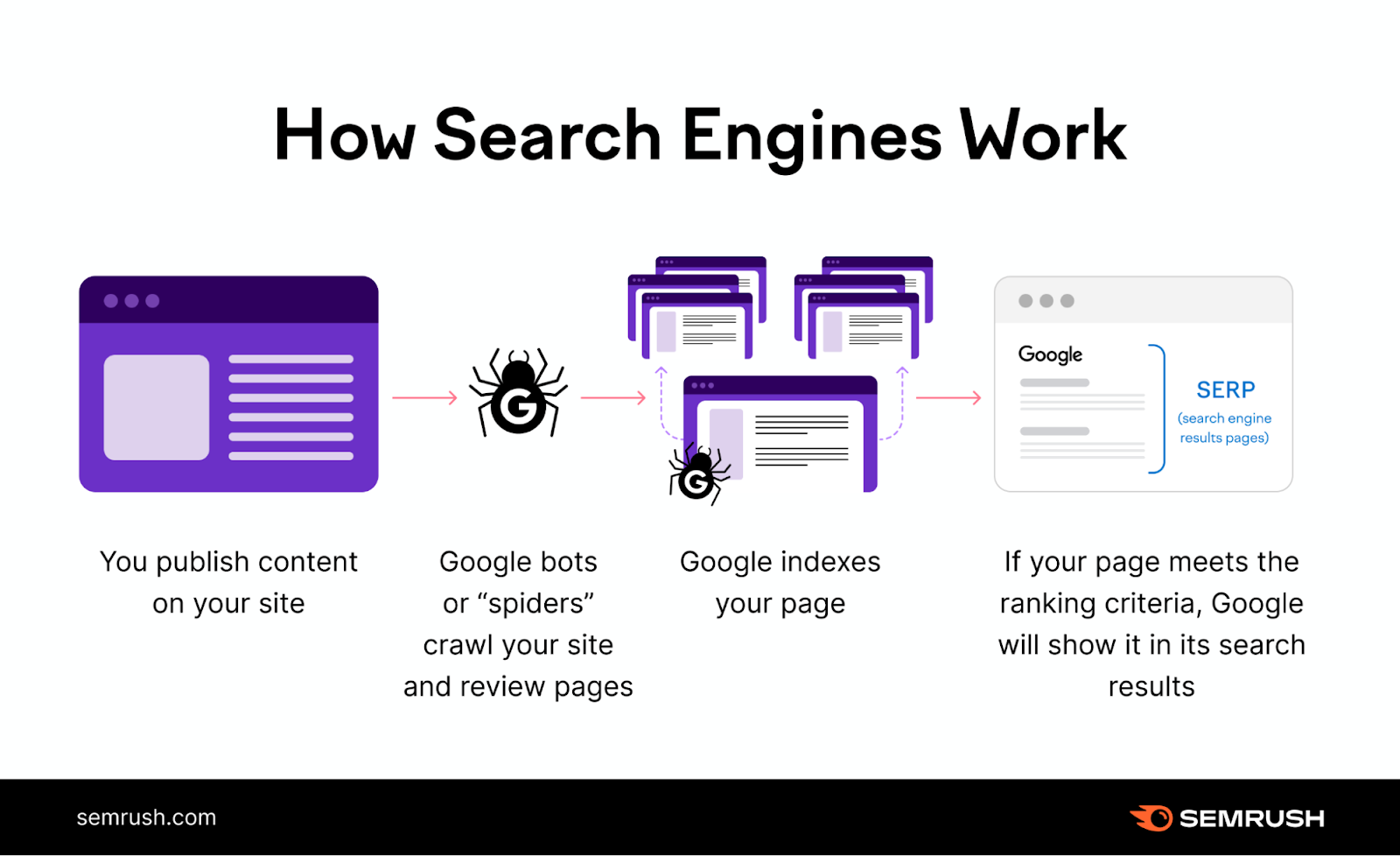
The process of Google indexing can be broadly understood through several key stages: Crawling, Indexing, and Serving Search Results. Each of these stages is crucial and interconnected, contributing to the seamless delivery of information that billions of users rely on daily. Understanding these stages not only demystifies how Google works but also provides invaluable insights for website owners and content creators aiming to make their digital content discoverable.
The Crawling Process: Discovering the Digital Landscape
Before Google can even think about organizing information, it first needs to find it. This is where crawling comes in. Crawling is the ongoing process by which Google bots, also known as spiders or crawlers, systematically explore the web to discover new and updated content. These bots navigate from page to page, following links from one website to another, much like a person browsing the internet.
How Crawlers Navigate the Web
Google’s crawlers are sophisticated software programs that operate around the clock. Their journey begins with a list of known URLs, often gathered from previous crawls and from sitemaps submitted by website owners. When a crawler visits a page, it reads the HTML code and extracts all the links present on that page. These extracted links are then added to a list of pages to be crawled in the future. This recursive process allows Google to discover an immense number of web pages, including those that are not directly linked from anywhere else.
The Role of Sitemaps
While crawlers are adept at finding pages through link discovery, sitemaps play a vital role in guiding them. A sitemap is essentially a roadmap for search engine crawlers, listing all the important pages on a website. By submitting a sitemap to Google Search Console, website owners can help crawlers discover new pages more efficiently and ensure that important content isn’t missed. This is particularly useful for large websites with complex structures or for new websites that haven’t yet accumulated many inbound links.
Crawl Budget and Its Importance
For website owners, understanding the concept of “crawl budget” is crucial. A crawl budget refers to the number of pages a search engine crawler can and will crawl on a website within a given period. Google allocates a crawl budget based on factors such as the website’s perceived authority, its update frequency, and the number of errors encountered during previous crawls. A higher crawl budget means Google’s bots will visit your site more often and discover new content or updates faster, which can positively impact your search rankings. Conversely, a low crawl budget can lead to delays in content being discovered and indexed.
Robots.txt: Guiding the Crawlers
The robots.txt file is a standard that website owners use to communicate with web crawlers. Located in the root directory of a website, this file provides instructions to crawlers about which pages or sections of the website they should not access or crawl. This is often used to prevent crawlers from accessing sensitive areas of a website, duplicate content, or pages that are not intended for public consumption. While robots.txt is a directive, it relies on the cooperation of the crawler; well-behaved crawlers, like Googlebot, will adhere to these instructions.
The Indexing Process: Cataloging and Understanding Content
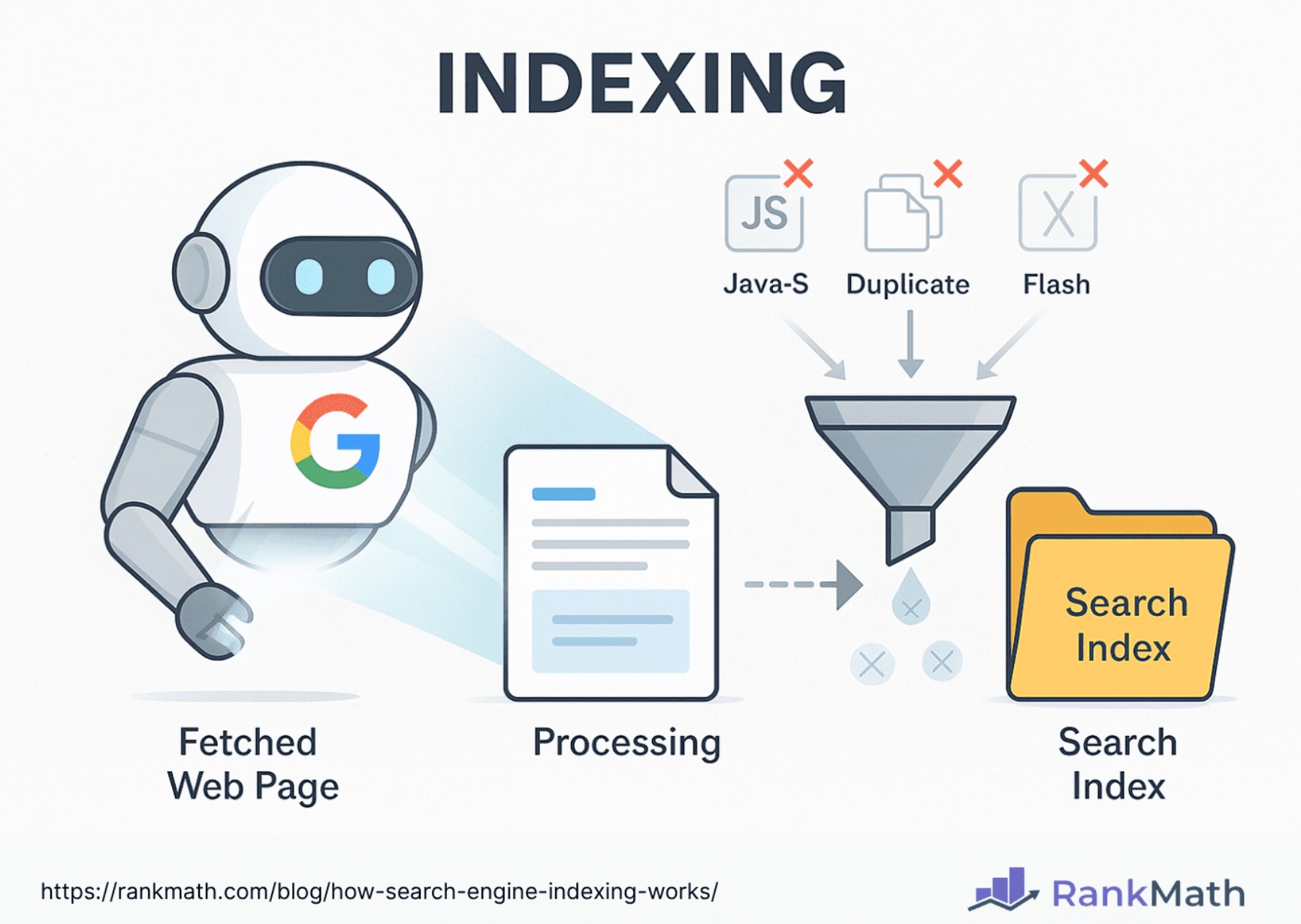
Once a page has been crawled, Google needs to process and understand its content. This is the essence of the indexing process. Google analyzes the content of each crawled page – the text, images, videos, and other media – and stores this information in a massive database, known as the Google index. This index is not simply a list of URLs; it’s a highly structured and complex repository of information about the web.

Parsing and Analyzing Content
When Googlebot crawls a page, it doesn’t just see the raw HTML. It parses the code to extract key information such as titles, headings, meta descriptions, image alt text, and the main body content. Algorithms then analyze this extracted information to understand the topic of the page, its relevance to various keywords, and its overall quality. This analysis involves sophisticated natural language processing (NLP) techniques to grasp the meaning and context of the words used.
Keywords, Context, and Semantic Understanding
Google’s indexing goes beyond simply matching keywords. Modern search engines strive for a semantic understanding of content, meaning they aim to comprehend the intent behind a search query and the meaning of the words used on a page, even if the exact keywords don’t match. This involves understanding synonyms, related concepts, and the overall topic being discussed. For example, if someone searches for “best way to make sourdough bread,” Google will not only look for pages with those exact words but also for pages discussing “artisan bread baking,” “starter maintenance,” or “fermentation techniques.”
Storing and Organizing the Data
The indexed data is stored in a massive, distributed database. This database is optimized for incredibly fast retrieval, allowing Google to access and rank billions of web pages in milliseconds when a user performs a search. The organization of this index is proprietary and constantly evolving, but it effectively creates a searchable map of the internet, where each piece of content is tagged and categorized based on its subject matter, relevance, and authority.
Serving Search Results: From Index to Answer
The final stage is presenting the most relevant information to users when they type a query into the search bar. This is where the power of the Google index truly shines. Google’s search algorithms use the information stored in the index to rank pages based on hundreds of factors, aiming to provide the most accurate and useful results for a given query.
Ranking Algorithms: The Art and Science of Relevance
When you perform a search, Google doesn’t just pick random pages from its index. Sophisticated algorithms analyze your query and compare it against the indexed information. These algorithms consider numerous ranking factors, including:
- Relevance: How well the content on a page matches the user’s search query. This includes keyword matching, but also semantic understanding of the query and the content.
- Authority: The trustworthiness and credibility of the website and the page itself. This is often determined by factors like the number and quality of backlinks (links from other websites).
- User Experience: Factors like page load speed, mobile-friendliness, and the absence of intrusive ads.
- Freshness: For certain queries, newer content may be more relevant than older content.
- Location: For local searches, the user’s geographical location is a critical factor.
These algorithms are constantly being refined and updated by Google to improve the quality of search results.
The Importance of User Intent
A key aspect of serving search results is understanding user intent. Google aims to determine why a user is searching for something. Are they looking to learn something (informational intent), buy something (commercial intent), or navigate to a specific website (navigational intent)? By understanding intent, Google can provide results that best fulfill the user’s underlying need. For example, a search for “buy running shoes” will likely return e-commerce results, while a search for “how do running shoes work” will return informational content.
Optimizing for Discoverability: SEO and Indexing
For website owners, understanding Google indexing is directly linked to Search Engine Optimization (SEO). By ensuring that their websites are crawlable, their content is well-structured and relevant, and they follow best practices, website owners can significantly improve their chances of being indexed and ranked highly in search results. This includes using descriptive titles and headings, creating high-quality and unique content, building natural backlinks, and ensuring a positive user experience. Ultimately, a well-indexed website is one that can effectively reach its target audience.