In the realm of technology and innovation, particularly within fields like autonomous systems, AI-driven analytics, and data-driven decision-making, understanding the fundamental concepts of sampling and populations is paramount. Whether we’re analyzing sensor data from a fleet of drones, evaluating the performance of an AI algorithm, or understanding user behavior for a new flight control interface, the distinction between a sample and a population shapes how we interpret results and draw conclusions. This article delves into the core differences between these two statistical concepts, exploring their significance and application within the broad landscape of tech and innovation.

The Core Concepts: Defining Population and Sample
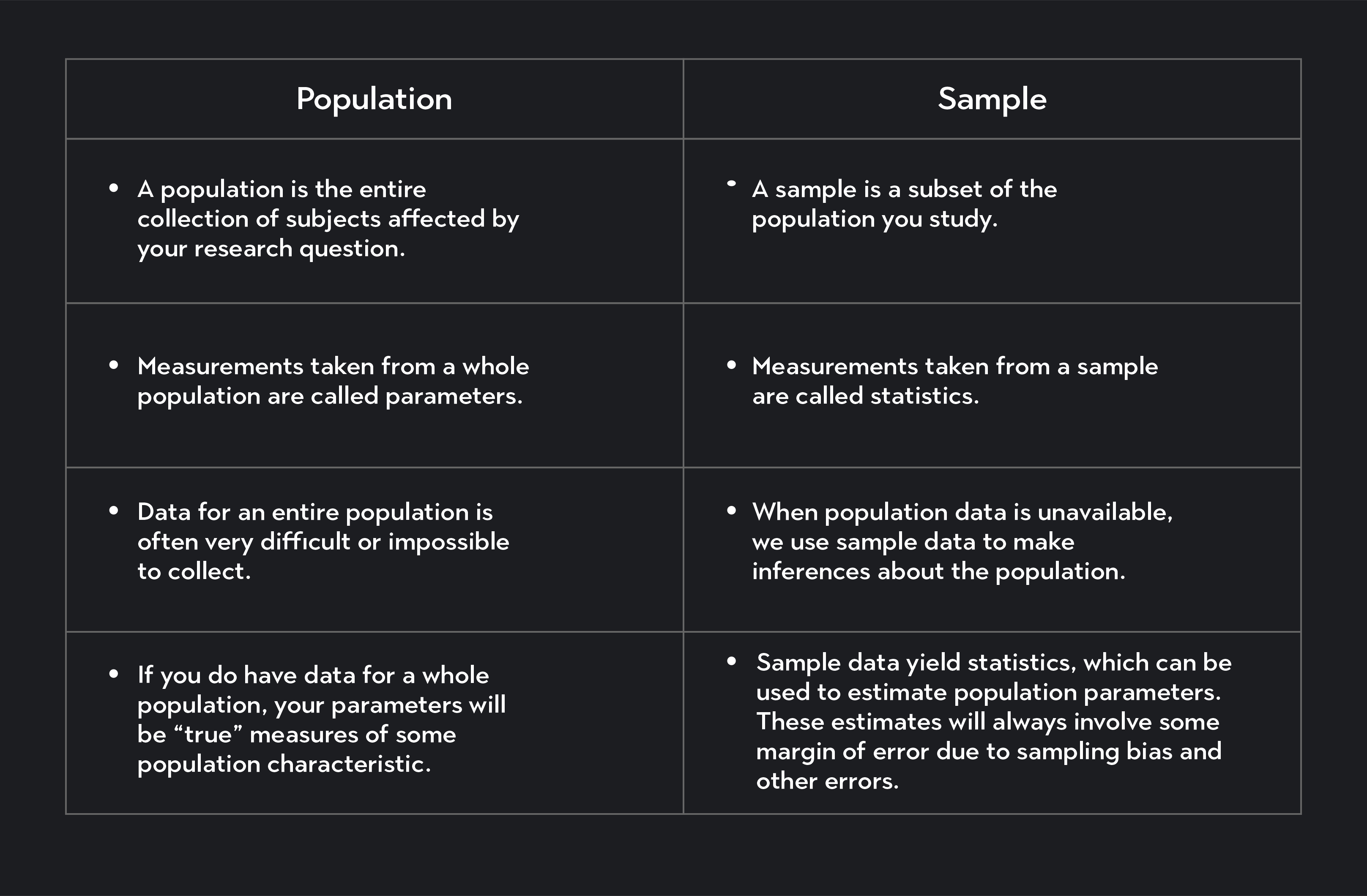
At its heart, the distinction between a population and a sample is a matter of scope and representation. One encompasses the entirety of a group of interest, while the other represents a carefully chosen subset of that group.
Understanding the Population: The Whole Picture
A population in statistics refers to the complete set of all individuals, objects, or data points that possess certain characteristics of interest for a study or analysis. It represents the entire group from which we want to draw conclusions. In the context of tech and innovation, a population can be incredibly diverse:
- All manufactured units of a specific drone model: If a company is testing the battery life of its new quadcopter, the population would be every single unit of that model that has been or will be produced.
- Every data point collected by a sensor network: For a system designed for urban traffic monitoring using embedded sensors, the population would be all traffic data points generated across all sensors within a given timeframe.
- All potential users of a new flight control software: If a startup is developing an innovative AI-powered navigation system, the population of interest would be all individuals who could potentially use this software.
- Every image captured by an autonomous vehicle’s camera system during a specific operational period: For an AI designed for object recognition in self-driving cars, the population might be all images generated during a week of testing.
- All possible outcomes of an algorithm’s execution under varying conditions: When optimizing a mapping drone’s flight path generation algorithm, the population would include every potential path the algorithm could create given different environmental inputs.
The key characteristic of a population is its completeness. It is the ultimate group we are interested in understanding. However, in many practical scenarios, studying an entire population is infeasible, impossible, or prohibitively expensive. This is where the concept of a sample becomes crucial.
Introducing the Sample: A Representative Subset
A sample is a subset of the population that is selected to represent the entire group. The goal of sampling is to gather information from a manageable portion of the population and then use that information to make inferences or draw conclusions about the population as a whole. A well-chosen sample should be representative of the population, meaning it shares similar characteristics and variability.
Continuing with our tech examples:
- A batch of drone units selected for stress testing: Instead of testing every single drone, a company might select a random 100 units from the production line for rigorous battery life assessments. This batch of 100 units is the sample.
- Data from a selected group of sensors: For the traffic monitoring network, researchers might choose to analyze data from 50 randomly selected sensors distributed across different city zones. These 50 sensors provide the sample data.
- Feedback from a beta testing group: Before a full software release, a developer might recruit 200 users from various demographics and experience levels to test the new flight control software. This beta group constitutes the sample.
- A curated selection of images for algorithm training: For an AI development project, a dataset of 10,000 images might be extracted from the millions captured by the vehicle’s cameras. This collection of 10,000 images is the sample used for training and validation.
- A set of simulated flight paths tested for performance: To evaluate the mapping algorithm, engineers might generate and analyze 500 diverse flight paths under various simulated wind and terrain conditions. These 500 paths form the sample for performance analysis.
The effectiveness of any conclusions drawn from a sample hinges on its ability to accurately reflect the population. A biased or unrepresentative sample can lead to flawed insights and misguided technological advancements.
Why the Distinction Matters: Implications in Tech and Innovation
The difference between a sample and a population is not merely an academic distinction; it has profound practical implications across various technological domains. The way we collect data, analyze it, and interpret the results is directly influenced by whether we are working with a sample or the entire population.
The Necessity of Sampling: Practical Constraints and Efficiency
In the world of cutting-edge technology, populations are often vast, dynamic, and inherently difficult to access in their entirety.
- Scale and Scope: Imagine trying to test the signal strength of every Wi-Fi-enabled smart device manufactured globally, or analyzing the operational efficiency of every autonomous vehicle deployed worldwide. These populations are immense, constantly growing, and geographically dispersed, making a complete census impractical.
- Time and Cost: Conducting a full population study would require exorbitant amounts of time, resources, and personnel. For rapidly evolving fields like AI and robotics, by the time a full population study was completed, the technology would likely have advanced significantly, rendering the initial findings obsolete. Sampling allows for timely data collection and analysis, enabling agile development and iteration.
- Destructive Testing: In some cases, the very act of testing can destroy the item being tested. For instance, testing the durability of a drone’s chassis to its breaking point would render that unit unusable. In such scenarios, sampling is the only viable option to gather information about material properties or structural integrity without compromising the entire production output.
- Real-time Analysis: Many advanced technologies operate in real-time, demanding continuous monitoring and analysis. For example, a system designed to detect anomalies in global network traffic cannot wait to analyze every single packet. It relies on sophisticated sampling techniques to process incoming data streams efficiently and identify patterns or outliers in near real-time.
The judicious use of sampling allows researchers, engineers, and developers to gain valuable insights without being crippled by the practical limitations of studying entire populations.
Inferential Statistics: Bridging the Gap
The primary purpose of collecting data from a sample is to make inferences about the population from which it was drawn. This process is the domain of inferential statistics.
- Estimating Population Parameters: When we calculate statistics from a sample (like the average battery life of tested drones, or the success rate of a navigation algorithm on a subset of flight paths), we are often using these as estimates for the true, unknown parameters of the population. For instance, the mean battery life of the sampled drones is an estimate of the true mean battery life of all drones produced.
- Hypothesis Testing: In tech development, we frequently have hypotheses about the performance or characteristics of a new system. For example, “Does the new obstacle avoidance system reduce accidents by at least 10%?” We can test such hypotheses by collecting data from a sample of the system’s operations and using inferential statistics to determine if the observed effect in the sample is statistically significant enough to conclude it exists in the population.
- Generalizability: The ultimate goal is to generalize findings from the sample to the broader population. This allows us to make confident statements about the performance, reliability, or user experience of a technology for its intended audience or application. For example, if a sample of users finds a new drone controller intuitive, we can infer that the broader user base is likely to find it similarly intuitive.

The accuracy of these inferences is directly tied to the quality of the sample. A poorly selected sample can lead to significant errors in estimation and flawed conclusions, potentially resulting in the deployment of unreliable or ineffective technologies.
Types of Sampling and Their Relevance
The way a sample is selected is crucial for its representativeness. Various sampling techniques exist, each with its strengths and weaknesses, and understanding these is vital for drawing valid conclusions in tech research and development.
Probability Sampling Methods: Ensuring Randomness
Probability sampling methods are characterized by the fact that every member of the population has a known, non-zero chance of being included in the sample. This randomness is key to minimizing bias and enhancing the generalizability of findings.
- Simple Random Sampling: This is the most basic form, where each member of the population has an equal chance of selection. Imagine assigning a unique number to every drone off the assembly line and using a random number generator to pick 100 of them for quality control. This ensures no systematic bias in selection.
- Stratified Sampling: This method is used when the population can be divided into subgroups (strata) that may differ in some characteristic. The sample is then drawn randomly from each stratum, proportionally to its size in the population. For example, when testing a new AI-powered flight system, if the population of potential users includes distinct groups (e.g., beginners, hobbyists, professionals), stratified sampling would ensure representation from each group. This is particularly useful for understanding how a technology performs across diverse user segments.
- Cluster Sampling: In this approach, the population is divided into clusters (often geographically or organizationally). A random selection of clusters is made, and then all individuals (or a random sample of individuals) within the selected clusters are included in the sample. This is efficient when the population is spread out. For example, testing the performance of a drone-based inspection system across different industrial sites might involve randomly selecting a few sites (clusters) and then testing the system at all designated points within those sites.
Non-Probability Sampling Methods: Practicality Over Probability
Non-probability sampling methods do not involve random selection. While often more convenient and less expensive, they are more susceptible to bias and limit the ability to make definitive statistical inferences about the population.
- Convenience Sampling: This involves selecting individuals or data points that are most readily available. For example, a developer testing a new drone app might gather feedback from their immediate colleagues or friends. While quick, this sample is unlikely to represent the broader user base.
- Purposive Sampling: In this method, the researcher uses their judgment to select individuals or data points that they believe are most representative or relevant to the study’s purpose. For instance, when developing a feature for advanced aerial cinematography, a filmmaker might deliberately select experienced cinematographers for feedback, assuming they best understand the needs of that niche.
- Snowball Sampling: This technique is often used to reach hard-to-access populations. An initial set of participants is identified, and they are then asked to refer other potential participants. This can be useful for researching niche communities within the tech industry, such as early adopters of experimental robotics.
The choice of sampling method profoundly impacts the validity and reliability of conclusions drawn from data. In tech and innovation, where rapid development and sound decision-making are crucial, selecting the appropriate sampling strategy is a critical step in the research and development lifecycle.
The Impact of Sampling on Data Analysis and Decision Making
The distinction between sample and population, and the methods used to bridge them through sampling, have direct consequences on how we analyze data and the decisions we make based on that analysis.
Statistical Significance and Confidence Intervals
When analyzing data from a sample, it’s important to acknowledge the inherent uncertainty. We are not observing the entire population, so our findings are estimates.
- Statistical Significance: This concept helps us determine whether the observed results in a sample are likely to be a true reflection of the population or simply due to random chance. For instance, if a new drone’s flight time is tested on a sample of 50 units and shows a 5% improvement over the previous model, statistical significance testing will tell us if this 5% improvement is likely to hold true for all drones produced or if it’s just a fluke in the tested batch.
- Confidence Intervals: These provide a range of values within which the true population parameter is likely to lie, with a certain level of confidence. For example, a confidence interval for the average battery life of a sample of drones might be “We are 95% confident that the true average battery life of all drones produced is between 28 and 32 minutes.” This quantifies the uncertainty associated with our sample estimate.
Understanding these concepts is vital for avoiding overstatement or underestimation of a technology’s performance. In fields like autonomous navigation or safety-critical systems, misinterpreting sample data can have severe consequences.
Avoiding Biased Conclusions and Misleading Innovations
The most significant pitfall in using samples is the risk of bias. If the sample is not representative of the population, the conclusions drawn will be flawed.
- Selection Bias: This occurs when the sampling method systematically favors certain individuals or data points over others. For example, if a user satisfaction survey for a new drone app only reaches users who are already highly engaged with the product, the results might be overly positive and not reflect the experience of casual users.
- Measurement Bias: This arises from errors in the way data is collected or measured. For example, if sensors used to collect traffic data in a sampled area are consistently miscalibrated, the data will be systematically inaccurate, leading to flawed insights about traffic flow.
- Survivorship Bias: This is a common trap where focus is placed only on those “survivors” or successes, overlooking those who failed. For instance, analyzing the performance of a fleet of delivery drones by only looking at those that completed their missions successfully, while ignoring those that experienced failures, would lead to an overly optimistic assessment of the fleet’s overall reliability.
In the fast-paced world of technology, rushing to deploy innovations based on biased sample data can lead to product failures, negative user experiences, and wasted resources. Rigorous attention to sampling methodology and critical evaluation of data are therefore essential.
Conclusion: The Foundation of Data-Driven Tech
The distinction between a sample and a population is a bedrock principle in any data-driven field, and its importance in technology and innovation cannot be overstated. From the development of sophisticated AI algorithms to the engineering of reliable autonomous systems, the ability to effectively collect, analyze, and interpret data is paramount.
A clear understanding of what constitutes a population of interest and how to select a representative sample allows us to move beyond anecdotal evidence and make informed, data-backed decisions. Whether we are estimating the performance of a new sensor array, assessing the usability of an innovative flight control interface, or predicting the failure rate of complex hardware, the principles of sampling guide our research, validate our designs, and ultimately shape the future of technology. By embracing robust sampling methodologies and critically evaluating our findings, we can ensure that the innovations we pursue are not only groundbreaking but also reliable, effective, and beneficial to their intended users and applications.