Data streaming, at its core, represents a paradigm shift in how we collect, process, and react to information. Gone are the days where data was primarily collected, stored in batches, and then analyzed at a later, often static, juncture. Instead, data streaming champions the concept of continuous data flow, enabling real-time insights and immediate action. This isn’t just about faster data; it’s about a fundamental change in our ability to leverage information as it’s generated, unlocking a wealth of opportunities across industries.
The digital landscape is characterized by an ever-increasing volume and velocity of data. From the sensors embedded in smart devices and industrial machinery to the vast networks of connected vehicles and the constant hum of online transactions, data is being generated at an unprecedented rate. Traditional data processing methods, often reliant on periodic batch processing, struggle to keep pace with this torrent. This is where data streaming steps in, offering a solution that is both agile and responsive.

At its most fundamental level, data streaming involves the continuous transmission of data from a source to one or more destinations. This data can take many forms – sensor readings, user activity logs, financial market updates, video feeds, and much more. The key differentiator is that this data is processed and analyzed in motion, rather than after it has been accumulated. This real-time nature is what imbues data streaming with its transformative power.
The implications of this real-time processing are profound. Businesses can now detect anomalies, predict future trends, personalize user experiences, and respond to critical events with unparalleled speed. This agility is crucial in today’s dynamic environment, where milliseconds can mean the difference between capitalizing on an opportunity and missing it entirely, or between preventing a disaster and reacting to its aftermath.
The Core Principles of Data Streaming
Understanding data streaming begins with grasping its foundational principles. These are the pillars upon which its efficiency and effectiveness are built, ensuring that data is not only moved but also processed in a manner that maximizes its value.
Continuous Data Flow and Low Latency
The hallmark of data streaming is its continuous nature. Unlike batch processing, where data is collected over a period and then processed, streaming treats data as an uninterrupted sequence of events. Each event, or data point, is processed as soon as it arrives. This is achieved through specialized messaging queues and processing frameworks designed for high throughput and minimal delay. The goal is to reduce latency – the time it takes for data to travel from its origin to its processed state – to the lowest possible level. This is critical for applications that demand immediate feedback, such as fraud detection in financial transactions, real-time performance monitoring of critical infrastructure, or dynamic pricing in e-commerce. The ability to react to events as they happen, rather than after a delay, is what makes streaming so powerful.
Event-Driven Architecture
Data streaming is inherently an event-driven architecture. An “event” is any discrete occurrence that has significance and can be captured as data. This could be a user clicking a button on a website, a temperature sensor exceeding a threshold, a new sale being made, or a drone capturing a new image. In a streaming system, these events are captured and transmitted individually or in very small micro-batches. This event-centric approach allows systems to react to specific occurrences in real-time, triggering subsequent actions or analyses. For example, a surge in user activity on a particular feature might trigger an automatic scaling of server resources to accommodate the demand. Similarly, a sudden drop in pressure in a pipeline might trigger an immediate alert and initiate safety protocols. This granular responsiveness is a key advantage of event-driven systems powered by data streaming.
Scalability and Resilience
The modern data landscape is characterized by its unpredictability. Data volumes can fluctuate dramatically, and systems must be able to handle both surges and lulls in activity without compromising performance or availability. Data streaming platforms are designed with scalability in mind. They can often be scaled horizontally by adding more processing nodes, allowing them to handle increasing loads. Furthermore, resilience is a critical component. Data streaming systems are built to withstand failures, ensuring that no data is lost and that processing can continue even if individual components encounter issues. This is often achieved through mechanisms like data replication, fault tolerance, and the ability to reprocess data if necessary. The ability to scale up or down as needed, while maintaining robust operation, is essential for any mission-critical data processing system.
Key Technologies and Architectures in Data Streaming
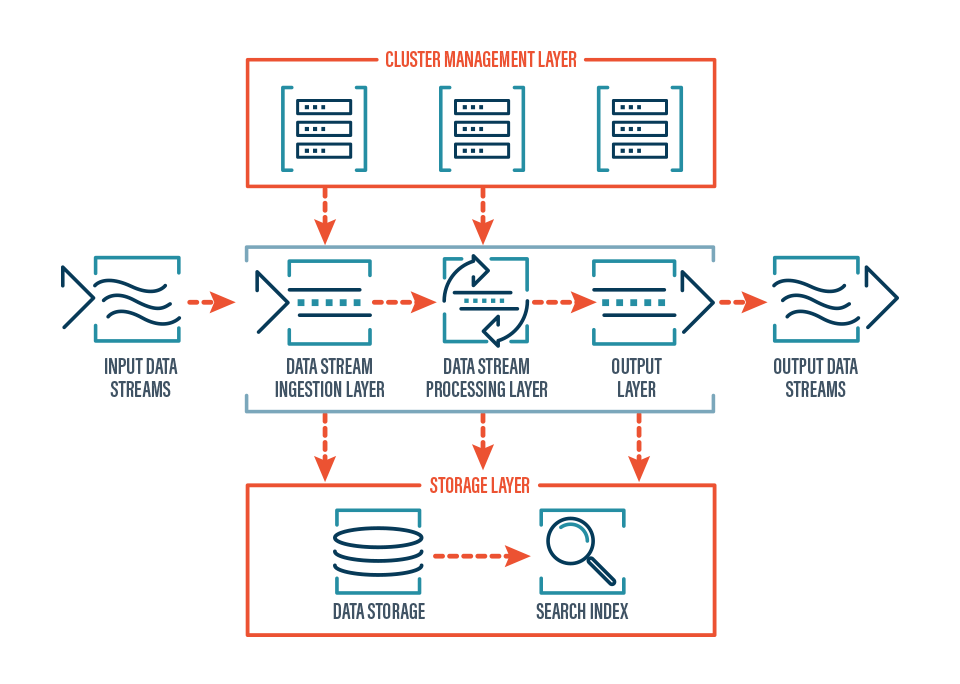
The realization of data streaming capabilities relies on a sophisticated ecosystem of technologies and architectural patterns. These components work in concert to ensure the efficient capture, transport, processing, and consumption of continuous data streams.
Messaging Queues and Event Brokers
At the heart of many data streaming architectures lie messaging queues, also known as event brokers. These act as intermediaries, decoupling data producers from data consumers. Producers send data events to the broker, and consumers subscribe to specific data streams from the broker. This asynchronous communication model provides several benefits, including buffering data during periods of high producer activity, enabling multiple consumers to access the same data stream independently, and allowing for easy addition or removal of producers and consumers without disrupting the system. Prominent examples of such technologies include Apache Kafka, RabbitMQ, and Amazon Kinesis. These platforms are designed for high throughput, low latency, and durability, making them ideal for handling the continuous flow of data in a streaming environment. They provide the foundational backbone for reliable data ingestion and distribution.
Stream Processing Engines
Once data has been ingested into the streaming infrastructure, it needs to be processed. This is where stream processing engines come into play. These are frameworks and platforms designed to perform real-time computations and transformations on data as it flows through the system. Unlike batch processing, which operates on static datasets, stream processors analyze data in motion, enabling operations such as filtering, aggregation, enrichment, and complex event processing (CEP). CEP, for instance, allows for the identification of patterns of events that signify a particular situation, such as detecting a fraudulent transaction by observing a sequence of unusual purchase attempts. Popular stream processing engines include Apache Flink, Apache Spark Streaming, and Kafka Streams. These engines are optimized for speed and efficiency, enabling complex analytics and decision-making in real-time.
Data Storage and Analytics for Streaming Data
While the essence of data streaming is real-time processing, it’s often necessary to store the processed data for historical analysis, auditing, or training machine learning models. However, traditional relational databases can struggle with the sheer volume and velocity of streaming data. Therefore, specialized data stores are often employed. This can include time-series databases optimized for storing and querying data with timestamps, NoSQL databases that offer flexible schema and high scalability, or data lakes that can store vast amounts of raw and processed data. Furthermore, analytics platforms are adapted to work with streaming data, allowing for real-time dashboards, alerts, and the development of predictive models that continuously learn from the incoming data streams. This integration of real-time processing with appropriate storage and analytics ensures that the value derived from streaming data can be maximized both immediately and over time.
Applications and Impact of Data Streaming
The transformative power of data streaming is evident across a wide spectrum of industries, driving innovation and enabling new capabilities that were previously unimaginable. Its ability to provide real-time insights and facilitate immediate action has become a critical competitive advantage.
Real-Time Monitoring and Analytics
One of the most immediate and impactful applications of data streaming is in real-time monitoring and analytics. This encompasses a vast array of use cases, from monitoring the performance of complex IT infrastructure to tracking the health of industrial machinery in a factory. For instance, in an IoT context, sensors on manufacturing equipment can stream data on temperature, vibration, and operational status. By processing this data in real-time, anomalies can be detected instantly, allowing for preventative maintenance before a failure occurs, thereby minimizing downtime and costly repairs. Similarly, financial institutions use data streaming to monitor market fluctuations and detect fraudulent transactions as they happen. This proactive approach to monitoring and analysis is a direct result of the continuous flow of data and the ability to process it with minimal latency.
Personalization and Customer Experience
In the realm of customer engagement, data streaming plays a pivotal role in delivering personalized experiences at scale. Websites and applications can now track user interactions in real-time, analyzing clickstream data, browsing history, and purchase patterns as they occur. This allows for dynamic content delivery, personalized recommendations, and tailored marketing messages. For example, an e-commerce platform can immediately suggest related products based on what a user is currently viewing or has just added to their cart. Social media platforms utilize streaming data to curate personalized news feeds and deliver timely notifications. This ability to understand and respond to individual user behavior in real-time significantly enhances customer satisfaction and drives engagement.
Operational Efficiency and Decision Making
Beyond direct customer interactions, data streaming profoundly impacts operational efficiency and decision-making across businesses. In logistics, real-time tracking of shipments and delivery vehicles allows for dynamic route optimization in response to traffic conditions or unexpected delays. This not only improves delivery times but also reduces fuel consumption. In healthcare, streaming data from wearable devices can alert medical professionals to critical changes in a patient’s condition, enabling faster intervention. Autonomous systems, whether in manufacturing robots or self-driving vehicles, rely heavily on continuous streams of sensor data to navigate their environments and make split-second decisions. The ability to process vast amounts of operational data in real-time empowers organizations to be more agile, responsive, and ultimately, more efficient.