Data Manipulation Language (DML) forms a crucial subset of Structured Query Language (SQL), serving as the primary toolset for interacting with and modifying data within a relational database. While SQL itself is a comprehensive language encompassing data definition, control, and querying, DML specifically focuses on the actions we perform on the data after the database structure has been established. Think of DML as the active verbs of database management, enabling us to insert new information, retrieve existing records, update outdated details, and remove irrelevant entries. Without DML, databases would be static repositories, unable to adapt to the dynamic flow of information that characterizes modern applications and businesses.

The importance of DML cannot be overstated. In the realm of tech and innovation, where data is the lifeblood of progress, DML empowers developers and data professionals to build sophisticated applications, analyze trends, and make informed decisions. From tracking user behavior on a website to managing inventory in a large-scale e-commerce platform, DML commands are the engine that drives these operations. Understanding DML is therefore a foundational skill for anyone involved in software development, data science, database administration, or business intelligence. It’s the language through which we speak to our data, ensuring it remains accurate, up-to-date, and readily accessible for analysis and action.
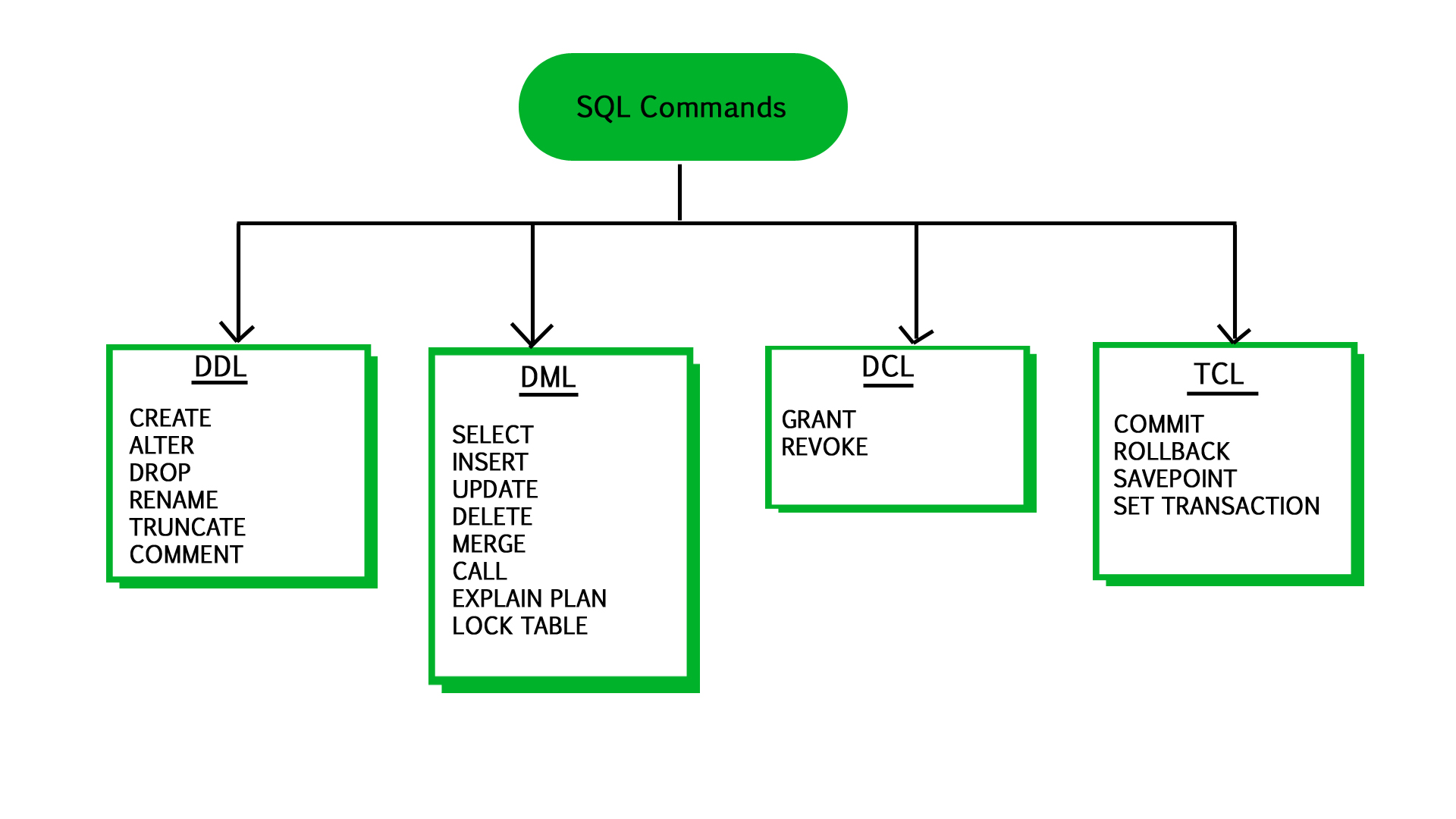
Core DML Operations: The CRUD Matrix
At its heart, Data Manipulation Language revolves around four fundamental operations, often referred to as the CRUD matrix: Create, Read, Update, and Delete. These four verbs represent the complete spectrum of modifications and retrievals possible with data within a relational database. Each of these operations has a corresponding SQL command that facilitates its execution. Mastering these commands is paramount to effectively managing and leveraging database information.
Creating New Data: INSERT
The INSERT statement is the gateway for populating a database with new information. It allows us to add single or multiple rows of data into a specified table. When inserting data, we must ensure that the values provided correspond to the data types and constraints defined for each column in the table. Failing to do so will result in an error, highlighting the importance of careful data entry and understanding table schemas.
Syntax and Examples:
The basic syntax for INSERT involves specifying the table name and then providing the values for the columns. We can either explicitly list the columns we are populating, which is generally a best practice for clarity and robustness, or rely on the default column order if we are populating all columns.
-
Inserting values for specific columns:
INSERT INTO customers (customer_id, first_name, last_name, email) VALUES (101, 'Alice', 'Smith', 'alice.smith@example.com');In this example, we are inserting a new record into the
customerstable, specifying thecustomer_id,first_name,last_name, andemail. -
Inserting values for all columns (assuming default order):
INSERT INTO products (product_id, product_name, price, stock_quantity) VALUES (201, 'Wireless Mouse', 25.99, 150);Here, we assume that
product_id,product_name,price, andstock_quantityare the columns in theproductstable, and we are providing values in that order. -
Inserting multiple rows at once: Many database systems support inserting multiple rows in a single
INSERTstatement, which can significantly improve performance by reducing the overhead of multiple individual operations.
sql
INSERT INTO orders (order_id, customer_id, order_date, total_amount)
VALUES
(301, 101, '2023-10-27', 75.50),
(302, 102, '2023-10-27', 120.00),
(303, 101, '2023-10-28', 45.75);
This statement adds three new orders to theorderstable concurrently.
Reading and Retrieving Data: SELECT
The SELECT statement is arguably the most frequently used DML command. Its purpose is to retrieve data from one or more tables based on specified criteria. It allows us to query the database, extract subsets of information, and present it in a structured format. The power of SELECT lies in its ability to filter, sort, and aggregate data, making it indispensable for reporting, analysis, and powering application interfaces.
Syntax and Examples:
The fundamental structure of a SELECT statement involves specifying the columns to retrieve and the table(s) from which to retrieve them. However, it offers a rich set of clauses that allow for sophisticated data manipulation.
-
Selecting all columns from a table:
SELECT * FROM employees;This will return all columns and all rows from the
employeestable. -
Selecting specific columns:
SELECT first_name, last_name, salary FROM employees;This retrieves only the
first_name,last_name, andsalarycolumns for all employees. -
Filtering data with the WHERE clause: The
WHEREclause is essential for specifying conditions that rows must meet to be included in the result set.SELECT product_name, price FROM products WHERE price > 50.00;This query returns the names and prices of products that cost more than $50.
-
Sorting data with the ORDER BY clause: The
ORDER BYclause arranges the result set in ascending (ASC) or descending (DESC) order based on one or more columns.SELECT customer_id, first_name, last_name FROM customers ORDER BY last_name ASC, first_name ASC;This sorts customers alphabetically by last name, and then by first name for those with the same last name.
-
Joining tables with JOIN clauses: In relational databases, data is often spread across multiple tables. The
JOINclause allows us to combine rows from two or more tables based on a related column between them.SELECT o.order_id, c.first_name, c.last_name, o.total_amount FROM orders o JOIN customers c ON o.customer_id = c.customer_id WHERE o.order_date = '2023-10-27';This query retrieves order details along with the customer’s first and last name for orders placed on a specific date. We use aliases (
oforordersandcforcustomers) for brevity. -
Aggregating data with GROUP BY and aggregate functions:
GROUP BYis used in conjunction with aggregate functions (likeCOUNT,SUM,AVG,MIN,MAX) to perform calculations on groups of rows.
sql
SELECT COUNT(order_id) AS number_of_orders, customer_id
FROM orders
GROUP BY customer_id
ORDER BY number_of_orders DESC;
This query counts the total number of orders for each customer and displays them in descending order of order count.
Modifying Existing Data: UPDATE
The UPDATE statement is used to modify existing records in a table. It allows us to change one or more values in specified rows that meet certain criteria. This is crucial for maintaining data accuracy and reflecting changes in real-world information.
Syntax and Examples:
The UPDATE statement requires you to specify the table to update, the columns to set with new values, and a WHERE clause to identify the specific rows to be modified.
-
Updating a single column for specific rows:
UPDATE products SET price = 27.50 WHERE product_id = 201;This statement increases the price of the product with
product_id201 to $27.50. -
Updating multiple columns for specific rows:
UPDATE employees SET salary = salary * 1.10, hire_date = '2024-01-01' WHERE employee_id = 15;This query increases the salary of employee 15 by 10% and updates their hire date.
-
Updating all rows (use with extreme caution!):
sql
UPDATE customers
SET is_active = FALSE;
This statement would set theis_activeflag toFALSEfor all customers in the table. Without aWHEREclause,UPDATEaffects every row, which can be catastrophic if not intended.
Removing Data: DELETE
The DELETE statement is used to remove one or more records from a table. Similar to UPDATE, it is critical to use a WHERE clause to specify precisely which rows should be deleted. Accidentally deleting the wrong data can lead to irreversible loss and significant business disruption.

Syntax and Examples:
The DELETE statement specifies the table from which to remove rows and uses a WHERE clause to identify the target rows.
-
Deleting specific rows:
DELETE FROM orders WHERE order_id = 302;This removes the order with
order_id302 from theorderstable. -
Deleting rows based on multiple conditions:
DELETE FROM customers WHERE email IS NULL OR last_login_date < '2022-01-01';This statement removes customers who have no email address or whose last login was before January 1, 2022.
-
Deleting all rows from a table (use with extreme caution!):
sql
DELETE FROM temporary_logs;
This will empty thetemporary_logstable entirely. While similar toTRUNCATE TABLE(which is often a Data Definition Language command that resets a table more efficiently),DELETEcan be logged and rolled back if within a transaction.
Advanced DML Concepts and Best Practices
Beyond the fundamental CRUD operations, DML offers more advanced functionalities and requires adherence to best practices to ensure data integrity, security, and performance. Understanding these nuances elevates a user from simply manipulating data to strategically managing it.
Transactions: Ensuring Data Consistency
In database management, a transaction is a sequence of operations performed as a single logical unit of work. Transactions are crucial for maintaining data consistency, especially in multi-user environments or when performing complex operations. DML statements like INSERT, UPDATE, and DELETE are typically executed within transactions.
- COMMIT: The
COMMITstatement makes all the changes performed within the current transaction permanent in the database. Once committed, the changes cannot be undone without initiating a new transaction to reverse them. - ROLLBACK: The
ROLLBACKstatement undoes all the changes made since the beginning of the current transaction. This is vital for error handling or when an operation fails midway, ensuring the database remains in a consistent state.
Consider a scenario where you need to transfer funds between two bank accounts. This involves debiting one account and crediting another. If the debit operation succeeds but the credit operation fails, without transactions, the money would be lost. By encapsulating both operations within a transaction, if the credit fails, the ROLLBACK command can undo the debit, preserving the integrity of the accounts.
Data Integrity Constraints and DML
While DML manipulates the data itself, Data Definition Language (DDL) defines the rules and constraints that govern the data’s structure and validity. DML operations must respect these constraints.
- Primary Keys: DML operations attempting to insert duplicate primary keys will fail.
- Foreign Keys: DML operations that would violate referential integrity (e.g., deleting a parent record that has associated child records) will be prevented unless specific cascade rules are defined.
- UNIQUE Constraints: DML attempts to insert duplicate values into columns with unique constraints will fail.
- NOT NULL Constraints: DML operations that try to insert
NULLvalues into columns defined asNOT NULLwill result in an error. - CHECK Constraints: DML operations that insert or update data violating a
CHECKconstraint (e.g., inserting a negative age) will be rejected.
These constraints act as guardians, ensuring that the data being manipulated through DML adheres to predefined business rules and maintains its accuracy and reliability.
Performance Considerations and Optimization
The efficiency of DML operations can significantly impact application performance. Poorly written queries or inefficient data manipulation can lead to slow response times, increased resource consumption, and a suboptimal user experience.
- Indexing: Proper indexing of columns used in
WHEREclauses andJOINconditions dramatically speeds upSELECTandUPDATEoperations. - Avoiding
SELECT *: When retrieving data, only select the columns you actually need.SELECT *can retrieve unnecessary data, increasing network traffic and processing time. - Efficient
WHEREClauses: Use selectiveWHEREclauses to limit the number of rows processed byUPDATEandDELETEstatements. - Batch Operations: Whenever possible, perform
INSERTandDELETEoperations in batches rather than one row at a time. - Understanding Execution Plans: Database systems provide tools to analyze how a query will be executed (the execution plan). Understanding these plans can help identify bottlenecks and optimize queries.
The Role of DML in Modern Tech Ecosystems
Data Manipulation Language is not merely an academic concept; it is a foundational element of virtually every modern technological application and system that relies on structured data. Its role extends far beyond simple data entry and retrieval, underpinning complex functionalities and driving innovation across various tech domains.
Powering Applications and Web Services
At the core of most web applications and services lies a database. DML commands are the workhorses that enable these applications to function. When a user logs into a website, SELECT statements retrieve their profile information. When a user makes a purchase, INSERT statements record the transaction, and UPDATE statements adjust inventory levels. Commenting on a social media post involves INSERTing new data, while liking a post might involve updating a counter. Every dynamic interaction a user has with an application, from filling out a form to viewing personalized recommendations, is facilitated by DML operations working behind the scenes.
Enabling Data Analytics and Business Intelligence
The ability to extract meaningful insights from vast datasets is crucial for modern businesses. DML, particularly the SELECT statement with its powerful filtering, joining, and aggregation capabilities, is the primary tool for data analysts and business intelligence professionals. They use DML to:
- Generate Reports: Create reports on sales figures, customer demographics, operational efficiency, and other key performance indicators.
- Identify Trends: Analyze historical data to spot emerging patterns and predict future outcomes.
- Segment Customers: Group customers based on purchasing behavior, demographics, or engagement levels for targeted marketing campaigns.
- Perform Root Cause Analysis: Investigate anomalies and diagnose problems by sifting through relevant data.
Without the ability to precisely query and aggregate data using DML, the field of data analytics would be severely hampered.
Supporting AI and Machine Learning Pipelines
Artificial intelligence and machine learning models are heavily reliant on high-quality, well-structured data for training and inference. DML plays a vital role in preparing this data.
- Data Extraction and Preprocessing: ML engineers use DML to extract relevant datasets from various sources, clean them, and transform them into formats suitable for model training. This might involve selecting specific features, handling missing values, and merging data from different tables.
- Feature Engineering: Creating new features from existing data often involves complex DML queries that combine, transform, and aggregate data in innovative ways.
- Model Output Storage: Once an AI model generates predictions or classifications, DML is used to store these results back into databases for further analysis or integration into applications.
The accuracy and effectiveness of AI models are directly proportional to the quality of the data they are trained on, making DML’s role in data preparation indispensable.
In conclusion, Data Manipulation Language is not just a set of SQL commands; it is the fundamental language of interaction with structured data. Its four core operations – INSERT, SELECT, UPDATE, and DELETE – form the bedrock of how we create, access, modify, and remove information within databases. As technology continues to advance, the ability to effectively wield DML will remain a critical skill for professionals across the tech landscape, enabling them to build robust applications, derive profound insights, and drive innovation forward.