The digital age has ushered in an era of unprecedented data generation. Every interaction, transaction, and operation within an organization now contributes to a sprawling, ever-increasing digital footprint. Effectively harnessing this data, transforming raw information into actionable insights, is no longer a luxury but a critical necessity for survival and growth. At the heart of this data-driven revolution lies the concept of the data warehouse, a foundational technology that empowers businesses to understand their past, optimize their present, and intelligently predict their future.
A data warehouse is not simply a large database. It is a strategically designed, subject-oriented, integrated, time-variant, and non-volatile collection of data used to support management decision-making processes. Unlike transactional databases that focus on capturing real-time events, data warehouses are optimized for analytical querying and reporting, providing a historical perspective that enables deeper understanding and more informed strategic planning.
The Core Concepts of Data Warehousing
At its essence, a data warehouse serves as a central repository for consolidated data from various disparate sources. This consolidation is meticulously managed to ensure consistency, accuracy, and accessibility for analytical purposes. Understanding the fundamental characteristics that define a data warehouse is crucial to appreciating its immense value.
Subject-Oriented
Data warehouses are organized around major subjects of the enterprise rather than specific application processes. For instance, instead of organizing data by sales transactions or inventory management systems, a data warehouse would be structured around subjects like “Customer,” “Product,” “Sales,” or “Employee.” This subject-oriented approach allows for a holistic view of the business, enabling analysis across different functional areas. By focusing on these key business entities, users can easily retrieve information relevant to a particular subject without having to navigate complex application-specific data models. This organization facilitates a more intuitive and comprehensive understanding of business performance and trends related to each subject.
Integrated
Data integration is a cornerstone of data warehousing. Data from multiple, often heterogeneous, source systems (e.g., CRM, ERP, spreadsheets, flat files) are extracted, transformed, and loaded (ETL) into the data warehouse. During this process, inconsistencies in naming conventions, data formats, coding structures, and units of measure are resolved. For example, customer addresses might be stored in different formats across various systems; the data warehouse integrates these into a standardized format. This unification ensures that data from different sources can be consistently queried and analyzed, providing a single, reliable source of truth for the organization. Without integration, comparing data from different systems would be a complex and error-prone endeavor.
Time-Variant
Data in a warehouse is associated with a specific point in time, allowing for historical analysis. Unlike operational systems that typically store only the current state of data, data warehouses retain historical data, enabling the tracking of changes and trends over time. This temporal aspect is critical for understanding performance evolution, identifying patterns, and forecasting future outcomes. For example, a data warehouse can store monthly sales figures for the past five years, allowing analysts to compare sales performance across different months and years. This historical record is invaluable for strategic planning, identifying seasonal trends, and evaluating the effectiveness of past initiatives.
Non-Volatile
Once data is loaded into a data warehouse, it is generally not updated or deleted. New data is added periodically, usually in batches, but existing historical data remains stable. This non-volatility ensures that analytical queries run against a consistent and unchanging dataset, preventing the introduction of errors or discrepancies during the analysis. In contrast, operational databases are constantly being updated and modified as transactions occur. The static nature of data in a warehouse allows for reliable and reproducible analysis, building trust in the insights derived from it. This stability is paramount for accurate reporting and historical trend analysis.
Architectures and Design Principles
The design and implementation of a data warehouse are complex undertakings, requiring careful consideration of architectural choices and design principles. These elements dictate how data is stored, accessed, and managed, ultimately impacting the performance and usability of the warehouse.
Types of Data Warehouse Architectures
Several architectural patterns exist for data warehouses, each with its own advantages and disadvantages. The choice of architecture often depends on the organization’s specific needs, resources, and existing infrastructure.
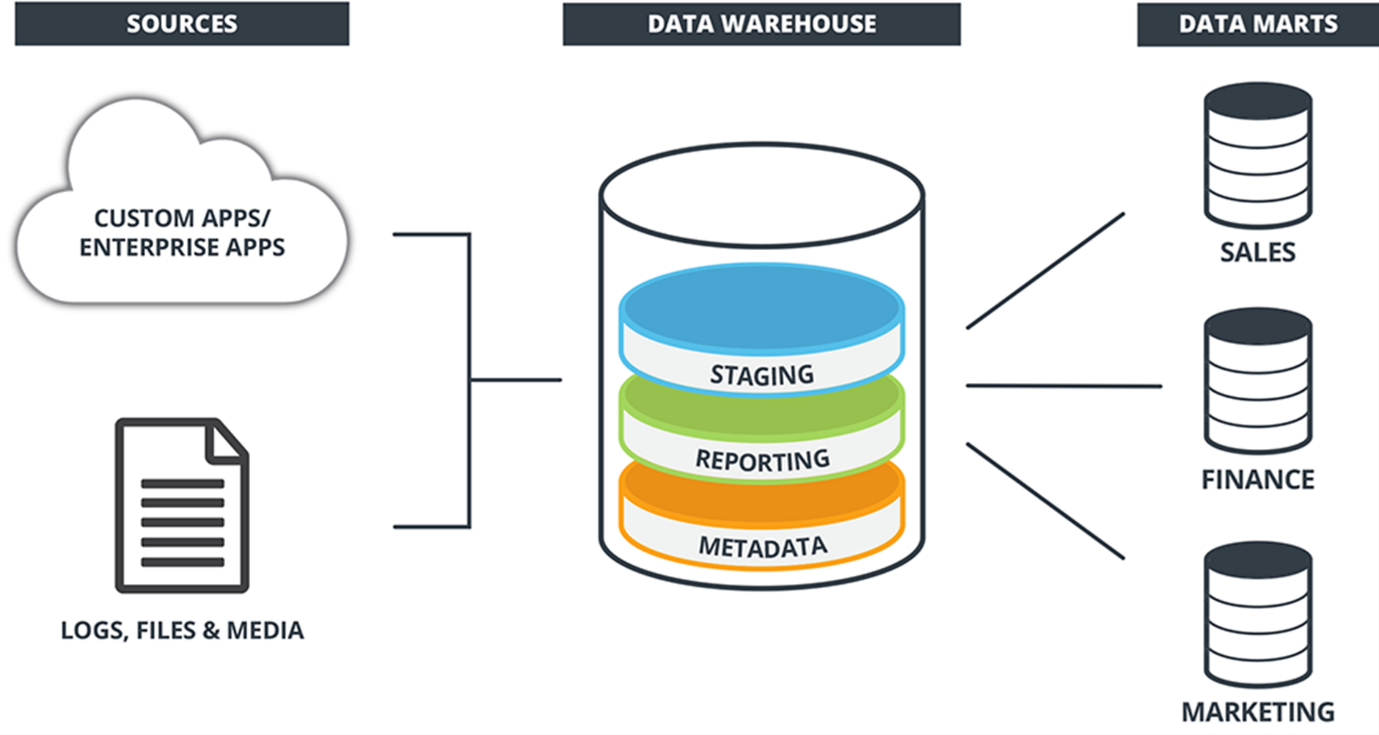
The Traditional (Inmon) Architecture
This approach, often attributed to Bill Inmon, emphasizes a top-down design. It begins with the creation of a central, integrated enterprise data warehouse (EDW) that serves as the sole source of truth. From the EDW, smaller data marts are created, which are subject-oriented subsets of the EDW designed to serve the specific analytical needs of particular departments or business units. This architecture promotes consistency and a single version of the truth across the organization, but it can be complex and time-consuming to implement. The EDW acts as a normalized repository, and data marts are denormalized for easier querying by end-users.
The Dimensional (Kimball) Architecture
In contrast to the top-down approach, Ralph Kimball’s data mart bus architecture promotes a bottom-up design. It focuses on building individual data marts that are independently usable but can also be conformed and integrated over time to form a larger, enterprise-wide view. Data marts in this architecture are typically designed using dimensional modeling, which involves star schemas or snowflake schemas. These schemas are optimized for query performance and ease of understanding for business users, making them highly effective for reporting and analysis. This approach allows for faster initial deployment of departmental analytical capabilities and gradual integration.
The Hub-and-Spoke Architecture
This hybrid approach combines elements of both Inmon and Kimball methodologies. It features a central data warehouse (the hub) that stores integrated data, and from which data marts (the spokes) are populated. The hub typically follows a normalized structure, while the spokes are dimensionally modeled for analytical purposes. This architecture aims to leverage the benefits of both centralized control and departmental flexibility. It can provide a balance between enterprise-wide consistency and agility for specific business needs.
Data Modeling Techniques
The way data is structured within a data warehouse significantly impacts its performance and the ease with which users can extract insights. Two primary data modeling techniques are prevalent:
Relational Modeling (Normalized)
This approach, often used in the central EDW of the Inmon architecture, involves organizing data into tables with relationships defined between them. Normalization aims to reduce data redundancy and improve data integrity by dividing data into multiple tables. While this approach is efficient for data storage and updates, it can lead to complex queries requiring joins across many tables, potentially impacting query performance for analytical workloads.
Dimensional Modeling (Denormalized)
This technique, central to the Kimball architecture, is optimized for analytical queries and reporting. It typically uses a star schema, which consists of a central fact table (containing quantitative measures) surrounded by dimension tables (containing descriptive attributes). A snowflake schema is a variation where dimension tables are further normalized. Dimensional models are easier for business users to understand and query, and they generally offer better query performance for analytical tasks due to reduced complexity in queries.
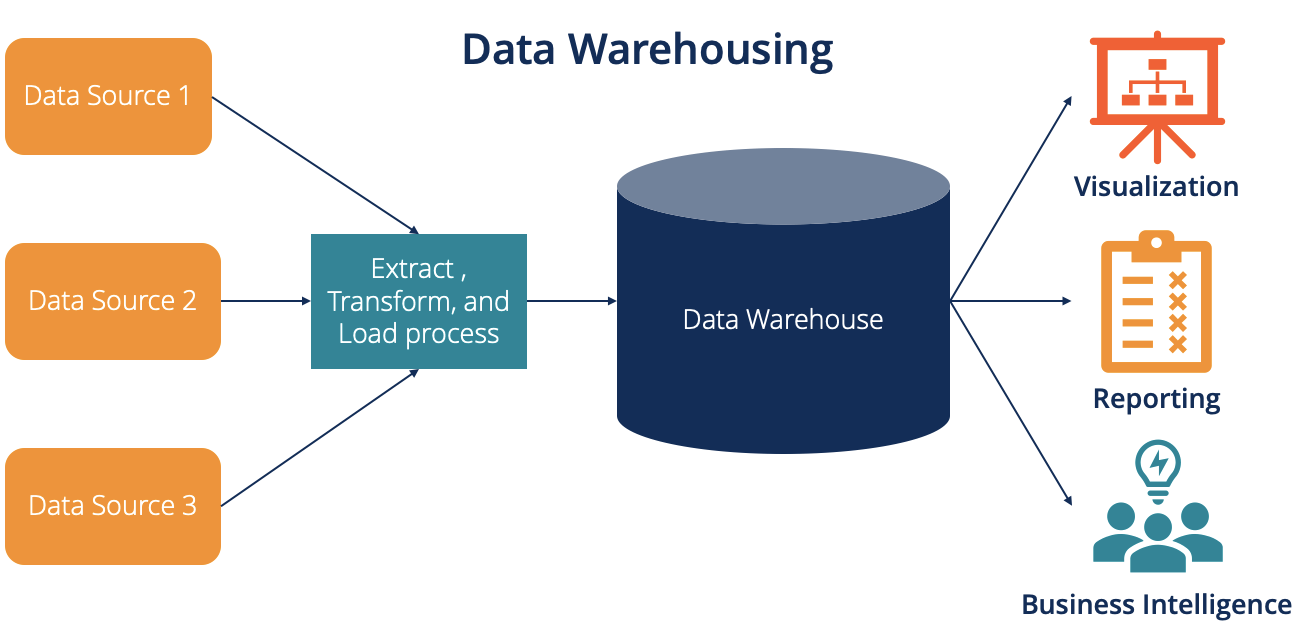
The ETL Process: Populating the Data Warehouse
The lifeblood of any data warehouse is the data it contains. This data does not magically appear; it must be meticulously extracted from various source systems, transformed into a consistent format, and then loaded into the warehouse. This complex, multi-step process is known as Extract, Transform, Load (ETL).
Extraction
This initial phase involves reading and extracting data from the various source systems. These systems can be diverse, including transactional databases, flat files, spreadsheets, cloud applications, and external data feeds. The extraction process needs to be efficient and reliable, ensuring that all necessary data is captured without negatively impacting the performance of the operational systems. Different strategies exist for extraction, such as full extraction (copying all data) or incremental extraction (only capturing data that has changed since the last extraction).
Transformation
This is often the most complex and time-consuming stage of the ETL process. Data from disparate sources is cleansed, standardized, and aggregated to conform to the data warehouse’s schema and business rules. Transformations can include:
- Cleansing: Identifying and correcting errors, inconsistencies, and missing values in the data. This might involve standardizing address formats, correcting typos, or imputing missing data points.
- Standardization: Ensuring data conforms to predefined formats and conventions. This includes standardizing units of measure, date formats, currency codes, and naming conventions.
- Integration: Combining data from multiple sources, resolving discrepancies and ensuring a unified view.
- Aggregation: Summarizing data to a higher level of granularity. For instance, daily sales figures might be aggregated into monthly or quarterly totals.
- Derivation: Creating new data fields by applying business logic or calculations to existing data. For example, calculating profit margin from sales revenue and cost of goods sold.
Loading
Once the data has been transformed and validated, it is loaded into the data warehouse. The loading process can be done in different ways:
- Full Load: Replacing all existing data in a table with the new dataset. This is typically done during initial setup or for smaller tables.
- Incremental Load: Adding only new or changed records to the existing data. This is more efficient for large, frequently updated datasets.
- Update Load: Modifying existing records in the data warehouse based on changes in the source data.
The ETL process is iterative and can be automated using specialized ETL tools, ensuring data consistency and timely updates to the data warehouse.
Benefits and Applications of Data Warehousing
The strategic implementation of a data warehouse yields a multitude of benefits that can profoundly impact an organization’s performance and competitive standing. By providing a unified, historical, and accessible source of truth, data warehouses empower businesses to make smarter decisions, optimize operations, and identify new opportunities.
Enhanced Business Intelligence and Decision Making
The primary benefit of a data warehouse is its ability to support robust business intelligence (BI) and analytical processes. It provides a centralized platform for generating reports, performing ad-hoc queries, and conducting complex data analysis. This enables decision-makers at all levels of the organization to gain deeper insights into business performance, identify trends, pinpoint areas for improvement, and make data-driven decisions. Whether it’s understanding customer purchasing behavior, tracking sales performance against targets, or analyzing operational efficiency, a data warehouse provides the foundation for informed strategic and tactical choices.
Improved Data Quality and Consistency
The ETL process inherent in data warehousing rigorously cleanses and standardizes data from disparate sources. This leads to a significant improvement in overall data quality and consistency across the organization. A single, unified view of data reduces discrepancies and ensures that everyone is working with the same, accurate information, fostering trust in the data and the insights derived from it. This consistency is crucial for reliable reporting and analysis, preventing costly errors that can arise from relying on conflicting or inaccurate data.
Historical Analysis and Trend Identification
The time-variant nature of data warehouses allows for comprehensive historical analysis. Businesses can track performance over time, identify seasonal patterns, understand long-term trends, and evaluate the effectiveness of past strategies and initiatives. This historical perspective is invaluable for forecasting, strategic planning, and understanding the root causes of performance fluctuations. It enables organizations to learn from their past and make more informed predictions about the future.
Increased Operational Efficiency
By consolidating data and providing easy access to relevant information, data warehouses can streamline various business processes. For instance, sales teams can quickly access customer data, marketing departments can segment audiences more effectively, and finance teams can generate financial reports with greater speed and accuracy. This improved access to information reduces the time spent searching for data and allows employees to focus on more value-added activities, ultimately leading to increased operational efficiency.
Competitive Advantage
In today’s data-driven landscape, organizations that effectively leverage their data gain a significant competitive advantage. A data warehouse empowers businesses to understand their market better, identify emerging trends before competitors, personalize customer experiences, and optimize resource allocation. The ability to quickly and accurately analyze vast amounts of data allows for agile responses to market changes and proactive identification of new opportunities, positioning the organization for sustained success.
In conclusion, data warehouses are indispensable tools for any organization seeking to thrive in the information age. They transform raw data into a strategic asset, providing the insights necessary to navigate complexity, drive innovation, and achieve sustained growth.